







Transformer 是一种完全基于注意力机制的神经网络模型,首次在2017年的论文《Attention Is All You Need》中提出。该模型最初用于机器翻译任务,并在特定任务中表现优于谷歌的其他神经网络机器翻译模型。Transformer 也是 Seq2Seq(序列到序列)结构的模型,但与之前基于 RNN(循环神经网络)的 Seq2Seq 模型相比,Transformer 具有更好的并行性,能够显著提高模型的训练和推理速度
目录
1.2 多头注意力(Multi-Head Attention)
1.4 编码器-解码器结构(Encoder-Decoder Architecture)
1 Transformer 的核心特点
1.1 自注意力机制(Self-Attention)
-
Transformer 的核心是自注意力机制,它允许模型在处理输入序列时,关注序列中的不同部分。通过计算每个词与其他词的相关性,模型能够捕捉到长距离依赖关系
-
自注意力机制的计算公式如下:
其中,Q(查询)、K(键)、V(值)是输入序列的线性变换,dk 是键的维度
1.2 多头注意力(Multi-Head Attention)
-
为了增强模型的表达能力,Transformer 使用了多头注意力机制。它将输入序列分别映射到多个不同的子空间,并在每个子空间中计算注意力,最后将结果拼接起来
-
多头注意力的计算公式如下:
其中,每个 headi 是单头注意力的计算结果,WO 是输出权重矩阵
1.3 位置编码(Positional Encoding)
-
由于 Transformer 不使用 RNN,因此需要一种方式来表示序列中词的位置信息。Transformer 通过位置编码将位置信息注入到输入序列中。
-
位置编码的计算公式如下:
其中,pos 是位置,i 是维度
1.4 编码器-解码器结构(Encoder-Decoder Architecture)
-
Transformer 由编码器和解码器两部分组成。编码器将输入序列映射为一系列隐藏表示,解码器则根据这些表示生成输出序列
-
编码器和解码器都由多个相同的层堆叠而成,每层包含多头注意力机制和前馈神经网络
1.5 并行性
-
由于 Transformer 不依赖于 RNN 的递归结构,因此可以并行处理整个输入序列,大大提高了训练和推理的速度
2 架构及工作流程

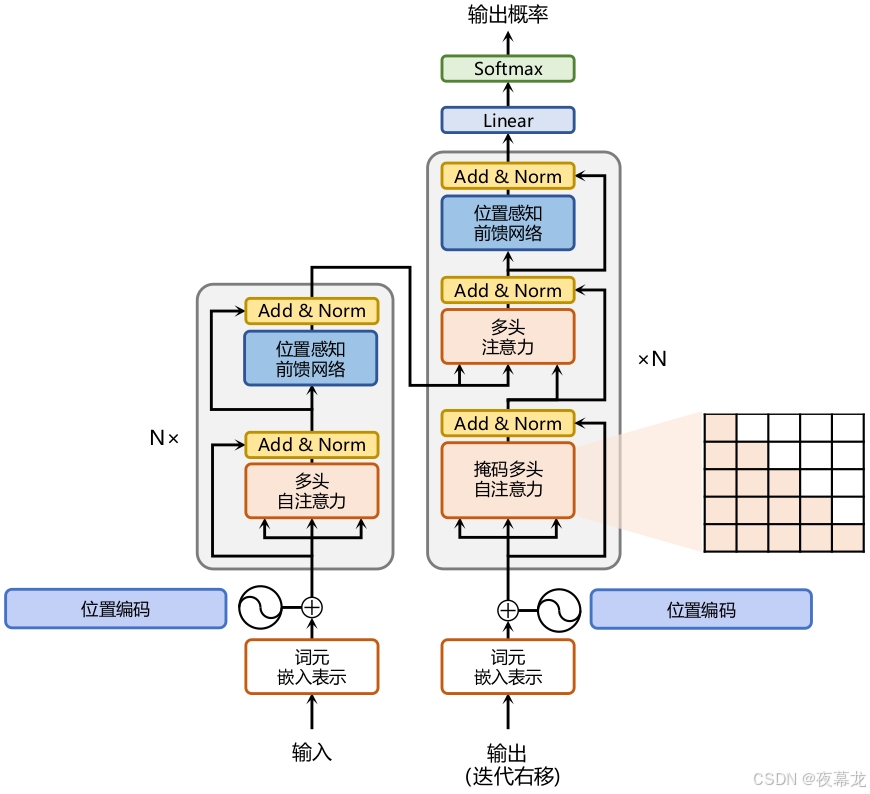
2.1 输入(Input)
-
接受输入数据,通过输入 Tokenizer 和 Embedding 进行预处理
-
Tokenizer 将输入文本分割为 token,Embedding 将 token 映射为固定维度的向量表示
2.2 编码器(Encoder)
-
编码器由多个相同的层(Nx)堆叠而成
-
每一层包括以下两个主要组件:
-
多头自注意力机制(Multi-Head Attention):
-
计算输入序列中每个 token 与其他 token 的相关性
-
-
前馈神经网络(Feed Forward):
-
对每个 token 的表示进行非线性变换
-
-
-
每个子层后都进行加和归一化(Add & Norm):
-
加和(Add):将子层的输入与输出相加(残差连接)
-
归一化(Norm):对结果进行层归一化(Layer Normalization)
-
2.3 解码器(Decoder)
-
解码器也由多个相同的层(Nx)堆叠而成
-
每层包括以下三个主要组件:
-
掩码多头自注意力机制(Masked Multi-Head Attention):
-
用于处理解码器输入数据的注意力计算,通过掩码防止未来 token 的信息泄露
-
-
多头自注意力机制(Multi-Head Attention):
-
计算解码器输出与编码器输出的相关性
-
-
前馈神经网络(Feed Forward):
-
对每个 token 的表示进行非线性变换
-
-
-
每个子层后同样进行加和归一化(Add & Norm)。
2.4 输出(Output)
-
解码器的输出通过以下步骤生成最终结果:
-
线性层(Linear):
-
将解码器的输出映射到目标词汇表大小的维度
-
-
Softmax 函数:
-
将线性层的输出转换为概率分布
-
-
-
最终生成输出概率分布(Output Probabilities),用于预测下一个 token 或生成目标序列
3 通俗比喻
可以用更通俗的比喻来理解Transformer:
想象你是一个国际会议的翻译员。传统的翻译系统(RNN模型)像是只能逐个单词记录的小本子,必须按顺序记录每个词,遇到长句子就容易记混重点。而Transformer则像是一支分工明确的高效团队:
1️⃣【注意力聚焦】团队成员通过"注意力放大镜"(注意力机制)同时观察整个句子,自动识别关键信息。比如翻译"那只站在树下的黑白猫吃了鱼"时,他们会同时注意到"猫-吃-鱼"的核心关系,以及"树下-黑白"的修饰信息,就像团队中有人专门记录动作,有人负责观察场景
2️⃣【并行工作流】不同于传统翻译必须逐字处理,这个团队可以多人同时工作。就像快递分拣中心同时处理多个包裹,Transformer能并行处理所有单词,训练速度比传统模型快6倍以上,这也是它迅速成为AI核心技术的原因
3️⃣【全局理解力】在翻译长文本时,传统方法像用手电筒逐字照亮,而Transformer像打开了整个房间的灯,能同时看清所有词语之间的关系。这种全局视野让它特别擅长处理需要长距离关联的任务,比如理解"虽然昨天下雨了,但是因为小明带了伞,所以..."这类复杂逻辑
正是这些突破,让Transformer不仅成为翻译利器,还成为了ChatGPT等大语言模型的核心架构。就像内燃机彻底改变了交通工具,Transformer机制正在重塑人工智能的发展方向


















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









