







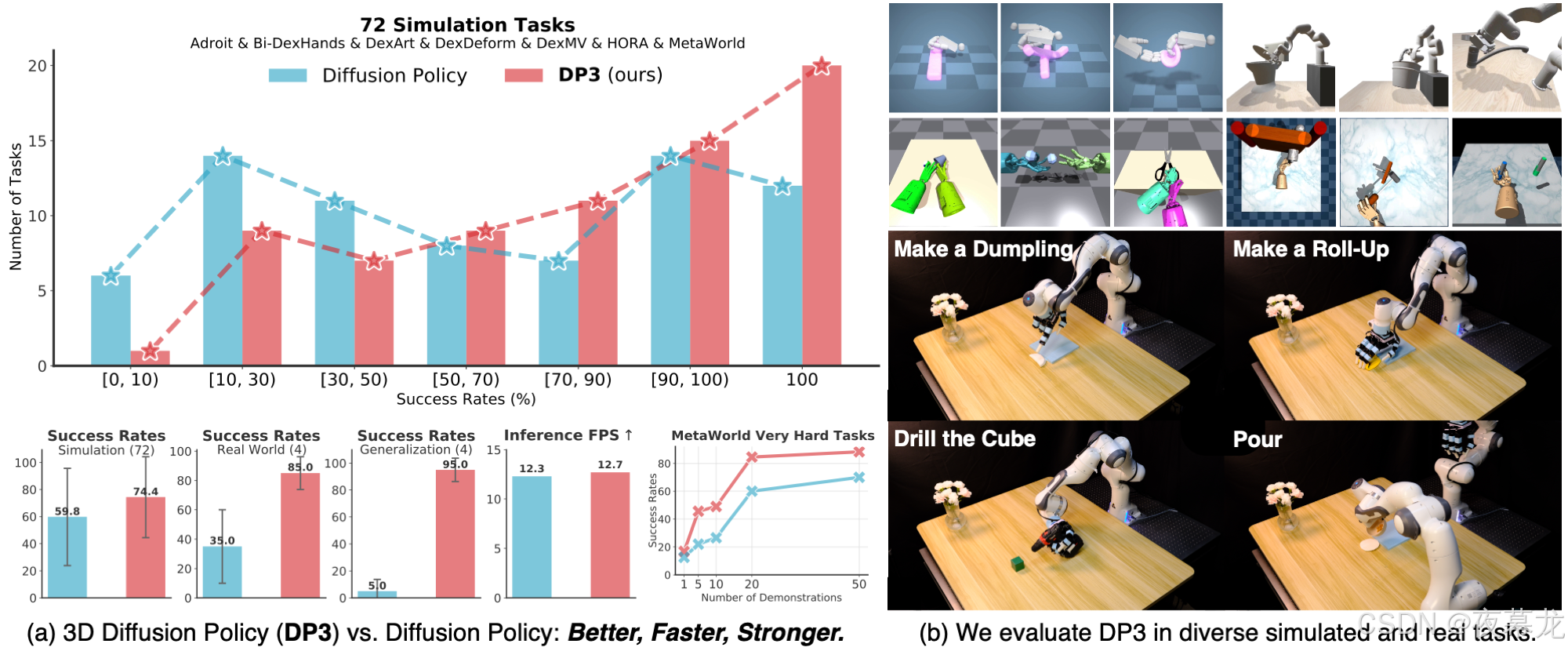
3D Diffusion Policy(DP3)是一种通用的视觉模仿学习算法,它将3D视觉表示与扩散策略结合在一起,在各种模拟和现实世界的任务中取得了惊人的效果,包括高维和低维控制任务,并具有实用的推理速度
目录
2.1 安装说明 Installing Conda Environment from Zero to Hero
1 DP3基准
1.1 仿真环境
在代码库中,为 Adroit、DexArt 和 MetaWorld 提供了灵巧的操作环境和专家策略(总共3+4+50=57个任务)。3D模态生成(深度和点云)已经被整合到这些环境中
1.2 真实世界的机器人数据
1.3 算法
提供了以下算法的实现:
- DP3: dp3.yaml
- 简单 DP3: simple_dp3.yaml
其中,dp3.yaml 是论文中提出的算法,相比于平均水平有着显著提升。在训练过程中,DP3 在Nvidia A40 gpu上需要 ~10G 的 gpu 内存和 ~3 个小时,因此对于大多数研究人员来说是可行的
simple_dp3.yaml 是 DP3 的简化版本,在训练(1~2小时)和推理(25 FPS)方面要快得多,没有太多的性能损失,因此更推荐给机器人研究人员
2. 安装
2.1 安装说明 Installing Conda Environment from Zero to Hero
以下指南适用于 3090/A40/A800/A100 GPU,cuda 11.7,驱动程序515.65.01的上位机
首先,git clone 这个 repo 并 cd 进去
git clone https://github.com/YanjieZe/3D-Diffusion-Policy.git请严格按照指南操作,以免出现错误。Especially, 确保 Gym 的版本是相同的
不用担心 Gym 版本。只要在 third_party/gym-0.21.0 安装作者版本就没有问题
2.1.1 创建 python/pytorch 环境
conda remove -n dp3 --all
conda create -n dp3 python=3.8
conda activate dp32.1.2 安装 torch
# if using cuda>=12.1
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# else,
# just install the torch version that matches your cuda version2.1.3 安装 dp3
cd 3D-Diffusion-Policy && pip install -e . && cd ..2.1.4 从 ~/.mujoco 中安装 mujoco
cd ~/.mujoco
wget https://github.com/deepmind/mujoco/releases/download/2.1.0/mujoco210-linux-x86_64.tar.gz -O mujoco210.tar.gz --no-check-certificate
tar -xvzf mujoco210.tar.gz此处说明一下,MuJoCo(Multi-Joint dynamics with Contact),这是一个用于物理仿真和机器人控制的强大库
cd ~/.mujoco:这条命令将切换到 ~/.mujoco 目录。~/.mujoco 是 MuJoCo 库的默认安装路径
如果该目录不存在,会报错:bash: cd: /home/yejiangchen/.mujoco: No such file or directory
那就手动创建,执行
mkdir ~/.mujoco我们在 home 文件夹打开显示隐藏文件夹,可以找到

将以下内容放入 bash 脚本中(通常在 YOUR_HOME_PATH/.bashrc 中),当然在安装过程中也可能已经自动写好了,可以注意一下。输入 source ~/.bashrc 使其生效,然后打开一个新的终端
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HOME}/.mujoco/mujoco210/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export MUJOCO_GL=egl然后安装 mujoco-py(在 third_party 文件夹中)
cd YOUR_PATH_TO_THIRD_PARTY
cd mujoco-py-2.1.2.14
pip install -e .
cd ../..2.1.5 安装 sim 环境
pip install setuptools==59.5.0 Cython==0.29.35 patchelf==0.17.2.0
cd third_party
cd dexart-release && pip install -e . && cd ..
cd gym-0.21.0 && pip install -e . && cd ..
cd Metaworld && pip install -e . && cd ..
cd rrl-dependencies && pip install -e mj_envs/. && pip install -e mjrl/. && cd ..此处建议逐行执行,因为不知道会报什么错......
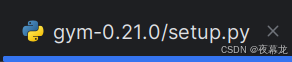
如果报错:ERROR: Requested gym==0.21.0 from file:///home/yejiangchen/%E6%A1%8C%E9%9D%A2/%E6%BA%90%E7%A0%81/Codes/3D-Diffusion-Policy-master/third_party/gym-0.21.0 has invalid metadata: Expected end or semicolon (after version specifier)
opencv-python>=3.
如下改一下 setup.py 就好了
![]()
从 Google Drive 下载 DexArt 资源,解压缩,并将其放入 third_party/dexart-release/assets 中
从 OneDrive 下载 Adroit RL experts,解压缩,将 ckpts 文件夹放在 $YOUR_REPO_PATH/third_party/VRL3/ 中
2.1.6 安装 pytorch3d(简化版)
cd third_party/pytorch3d_simplified && pip install -e . && cd ..如果报错:error: [Errno 2] No such file or directory: ':/usr/local/cuda-11.8/bin/nvcc'
可以参考此篇文章
2.1.7 安装必要软件包
pip install zarr==2.12.0 wandb ipdb gpustat dm_control omegaconf hydra-core==1.2.0 dill==0.3.5.1 einops==0.4.1 diffusers==0.11.1 numba==0.56.4 moviepy imageio av matplotlib termcolor2.1.8 安装点云可视化工具(可选)
pip install kaleido plotly
cd visualizer && pip install -e . && cd ..2.2 安装过程错误解决办法
在安装过程中可能遇到的错误与解决办法
3 数据集
可以使用官方提供的专家策略自己生成演示。生成的演示位于 $YOUR_REPO_PATH/3D-Diffusion-Policy/data/ 下
- 从 OneDrive 下载 Adroit RL experts,解压缩,将 ckpts 文件夹放在 $YOUR_REPO_PATH/third_party/VRL3/ 中
- 从 Google Drive 下载 DexArt 资源,解压缩,并将其放入 $YOUR_REPO_PATH/third_party/ DexArt -release/ 中
Note:由于是自己生成演示,因此结果可能与论文中报告的结果略有不同。这是正常的,因为模仿学习的结果高度依赖于演示质量。如果遇到一些不好的演示,请重新生成演示
4 使用
用于生成演示、培训和评估的脚本都在 Scripts/ 文件夹中
结果由 wandb 记录,所以需要先 wandb login 才能看到结果和视频
有关更详细的参数,请参考脚本和代码。在这里提供了一个使用代码库的简单说明
1. 通过 gen_demonstration_adroit.sh 和 gen_demonstration_dexart.sh 生成演示。相关详细信息参见脚本。例如:
bash scripts/gen_demonstration_adroit.sh hammer这将在 Adroit 环境中生成锤子任务的演示。数据将自动保存在 3D-Diffusion-Policy/data/ 文件夹中
2. 用行为克隆训练和评估策略。例如:
bash scripts/train_policy.sh dp3 adroit_hammer 0112 0 0这将在 Adroit 环境中使用点云模式针对 hammer 任务训练 DP3 策略。默认情况下,保存 ckpt(在脚本中是可选的)
如果报错:ImportError: cannot import name 'cached_download' from 'huggingface_hub'
可以参考解决方案
如果报错:hydra.errors.InstantiationException: Error locating target 'diffusion_policy_3d.env_runner.adroit_runner.AdroitRunner', see chained exception above.
full_key: task.env_runner
往上看,关键在于ModuleNotFoundError("No module named 'natsort'"),所以只需要安装一下相关库:
pip install natsort3. 评估已保存的策略或将其用于推理过程。例如:
bash scripts/eval_policy.sh dp3 adroit_hammer 0112 0 0这将评估刚刚训练并保存的 DP3 策略
Note: 评估脚本仅用于部署/推理。对于基准测试,在训练期间登录 wandb 查看结果
5 真实机器人
5.1 硬件设置
- Franka Robot
- Allegro Hand
- L515 Realsense Camera (Note: using the RealSense D435 camera might lead to failure of DP3 due to the very low quality of point clouds)
- Mounted connection base [link] (connect Franka with Allegro hand)
- Mounted finger tip [link]
5.2 软件
- Ubuntu 20.04.01 (tested)
- Franka Interface Control
- Frankx (High-Level Motion Library for the Franka Emika Robot)
- Allegro Hand Controller - Noetic
5.3 数据格式
每个收集到的真实机器人演示(episode length: T)都是 dictionary:
- "point_cloud": 形状为 (T, Np, 6) 的数组, Np 是点云的个数, 6 代表 [x, y, z, r, g, b]. Note: 强烈建议裁剪去除桌面/背景,在观测中只留下有用的点云,这已经在实验中证明了有效性
- "image": 形状为 (T, H, W, 3) 的数组
- "depth": 形状为 (T, H, W) 的数组
- "agent_pos": 形状为 (T, Nd) 的数组, Nd is the 动作维度 of the robot agent, i.e. 22 for our dexhand tasks (6自由度末端执行器位姿 + 16维度关节位姿)
- "action": 形状为 (T, Nd) 形状为. 对机械臂采用相对末端执行器位置控制, 对 dex hand 采用相对关节角位置控制
展开说明一下:
在 3D Diffusion Policy 中,每个从真实机器人收集的示例(即每一段机器人执行任务的记录)包含多个关键的数据字段,以字典的形式存储,其中:
1. "point_cloud":三维点云数组,形状为 (T,Np,6),其中:
- T表示示例的长度(episode length),即一段任务的时间步长数
- Np 是点云的数量。点云数据记录的是在特定时刻机器人的视觉信息,每个点云数据点包含6个数值
- 6 表示每个点的具体数据,包括三个空间坐标(x, y, z)和颜色信息(r, g, b)
Note:建议在处理点云数据时将桌面或背景裁剪掉,仅保留与任务相关的点云部分。在实验中,裁剪后的点云数据对于提升机器人的实际操作表现有明显效果
2. "image":图像数组,形状为 (T,H,W,3),其中:
- H和 W分别为图像的高度和宽度
- 3 表示图像的RGB三通道
3. "depth":深度信息数组,形状为 (T,H,W),与图像信息的形状相似,但只有单通道,用于记录每个像素点的深度信息(即目标物体和相机之间的距离)
4. "agent_pos":机器人的位置数据数组,形状为 (T,Nd),其中:
- Nd 是机器人的动作维度。在本项目中,用于 DexHand 任务时,动作维度为22
- 22 表示机器人末端执行器的 6 维空间位置(包括位置和方向)和手指关节的 16 维位置
5. "action":机器人的动作数据数组,形状为 (T,Nd)。在这里,机器人的动作控制分为:
- 对于机械臂,使用的是末端执行器的相对位置控制
- 对于 DexHand 手部模型,使用的是关节角度的相对位置控制
5.4 示例
对于训练和评估,应处理点云(使用 bounding box 和 FPS downsampling 进行裁剪),如论文中所述。同时,还提供了一个示例脚本 (here)
可以尝试使用官方提供的真实世界数据来训练策略
- 下载真实机器人数据。将数据放到 3D-Diffusion-Policy/data/ 文件夹下,例如 3D-Diffusion-Policy/data/realdex_drill.zarr,请选择与任务 yaml 文件中的 ‘zarr_path’ 相同路径
- 训练策略。例如:
bash scripts/train_policy.sh dp3 realdex_drill 0112 0 0
6 可视化
为了方便调试,提供了一个简单的可视化工具来,可视化点云。可以通过以下方式安装:
cd visualizer
pip install -e .然后通过以下命令可视化点云:
import visualizer
your_pointcloud = ... # your point cloud data, numpy array with shape (N, 3) or (N, 6)
visualizer.visualize_pointcloud(your_pointcloud)这将在网页浏览器中显示点云
7 在自己的任务上运行
DP3的优点在于它的通用性,因此可以轻松地在自己的任务上运行DP3。需要添加的是使此代码库支持相应格式的任务。以下是一些简单的步骤:
- 为任务编写环境包装器。您需要为您的环境编写一个包装器,以使环境接口易于使用。参见 3D-Diffusion-Policy/diffusion_policy_3d/env/adroit
- 为任务添加环境运行程序。参见 3D-Diffusion-Policy/diffusion_policy_3d/env_runner/
- 为任务准备专家数据。脚本 third_party/VRL3/src/gen_demonstration.py 是一个很好的示例,说明如何以自己的格式生成演示。基本上,专家数据是按顺序保存的状态-动作对
- 添加加载数据的数据集。参见 3D-Diffusion-Policy/diffusion_policy_3d/dataset/
- 在 3D-Diffusion-Policy/diffusion_policy_3d/configs/task 中添加配置文件。文件夹里有很多案例
- 对DP3进行训练和评估。参见 3D-Diffusion-Policy/scripts/train_policy.sh


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









