



基于二值权重网络的现场可编程门阵列CNN加速器
摘要
目前,卷积神经网络在执行物体识别任务时表现出良好的性能,但其依赖于GPU来解决大量复杂的运算。因此,神经网络的硬件加速器已成为硬件研究人员关注的核心课题。本文介绍了一种基于FPGA的神经网络加速器设计,该设计实现于赛灵思 Zynq‐7020 FPGA 上。我们使用二值化的LeNet模型在 MNIST数据集上实现了91%的准确率,并使用二值化的 AlexNet模型在CIFAR‐10数据集上实现了67%的准确率。同时,硬件资源占用仅约为原始设计在FPGA上资源使用的10%。
I. 引言
卷积神经网络(CNN)模型需要大量级的存储器和寄存器,以及大量的计算资源[1]。这使得在嵌入式系统中实现CNN模型变得困难。为了减少存储和计算资源的使用,[2]提出了两种方法:二值权重网络(BWN)和 XNOR‐Net。BWN使用缩放因子来减小二值化权重与原始权重之间的差异,从而比BC保持更高的识别准确率。XNOR‐Net不仅对权重进行二值化,还对输入数据进行二值化。尽管XNOR‐Net可以大幅降低硬件资源的使用,但其精度损失较高,不利于许多应用。
近年来,已提出多种二值权重卷积神经网络硬件架构。[3]提出了一种基于BinaryConnect的硬件架构,称为 YodaNN。由于采用简单的补码运算和多路复用器替代复杂的乘法累加运算,YodaNN所需的面积和能耗相对较小。[4]提出了一种名为FINN的硬件架构,这是一种为BNN构建的现场可编程门阵列加速器,能够在ZC706 FPGA上实现模型到硬件的高效映射与部署。
本文提出了一种基于二值权重网络(BWN)的硬件加速器,采用[2]训练策略,并对批归一化进行二值化以减少计算量。此外,通过增加神经网络规模[5]可提高系统准确率。我们还比较了定点16位权重与二值化权重设计之间的差异。所提出的架构应用于LeNet、AlexNet和 VGG‐16,并在MNIST、CIFAR‐10和CIFAR‐100数据集上进行了验证。对于MNIST、CIFAR‐10和CIFAR‐100数据集,二值化权重模型的识别准确率分别可达91%、67% 和52%。
II. 硬件架构
系统架构图如图1所示。我们共享卷积层和全连接层的硬件架构以减少硬件资源,并通过控制器控制输入数据的维度和大小、滤波器大小,以及启动卷积层、全连接层或最大池化。CNN权重模块和FC权重模块被构建为 ROM,用于存储训练好的模型权重。乒乓RAM是双端口随机存取存储器,用于存储临时特征图,且在每一层中乒乓会切换输出/输入对。临时特征图通过遵循[6]设计的 DDR控制器传输到DDR3。最后,SoftMax层根据前一层的结果找出最大值,同时控制器也输出一个有效信号。
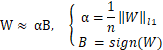
我们使用16位定点权重和二值化权重进行每项工作,以比较其准确率与硬件资源的差异。由于卷积操作的计算密度高于全连接层,我们主要介绍卷积层的硬件架构。我们将分别介绍通用卷积架构和二值化权重的卷积架构。
A. 通用卷积层的硬件架构
通用卷积层的硬件架构如图2所示。首先,流控制器读取输入数据和权重数据并将其放入缓冲区。特征缓冲区由移位寄存器组成,当缓冲区满时,可以连续执行操作。当处理单元完成乘法操作后,加法树对结果进行求和并传输到池化模块,同时处理单元采用流水线设计,可同时处理下一个输入。
B. 二值权重卷积层的硬件架构
与第一种设计类似,BWN使用二值化权重,其方程如 (1)所示,参考[2]。W是原始权重,可以通过αB来近似,其中α是W的平均值,B是W的符号。在训练策略中,α和 B用于前向传播阶段的结果计算,而近似权重αB则用于反向传播阶段的权重更新。因此,我们用乘加单元(MAU)替代了乘法器。在此设计中,允许16个乘加单元并行处理,以减少卷积操作时间,因为在第一种设计中,权重为16位定点数,所以我们读取16个通道的二值化权重,从而使用与第一种设计相同的存储模块。这使得第二种设计能够同时执行16位定点数权重的卷积操作和二值化权重的卷积操作。
$$ y $$
III. 实验结果
为了实现硬件加速器,我们使用包含赛灵思 Zynq‐7020 FPGA 的 EGO‐XZ7 开发板。通过 UART接口 将输入图像从 PC 传输到开发板,并由 DDR控制器 将流图像保存到 DRAM 中。然后命令解码器触发硬件加速器从 DRAM 读取图像到片上内存,启动卷积和全连接操作,并将临时特征图保存到 DRAM。完成所有计算后,结果通过响应模块发送回 PC。
表I和表II展示了我们设计的结果,我们提出了两种实现方案以验证加速器设计,一种是通用CNN(GCNN),另一种是二值权重CNN(BCNN)。使用了三个模型来验证这两种硬件设计之间的差异。在硬件资源的比较方面,GCNN 和BCNN均被设计为使用相同的乘加单元数量,以确保帧率相同。可以发现,层数越多,BCNN引起的精度损失越高,但硬件资源的使用量会更低。
然而,在许多应用中,更深的神经网络的准确率损失难以接受,这是一种权衡。
IV. 结论
在本文中,我们提出了两种架构,用于加速神经网络的推理阶段,同时保持其最高的准确率。第一种是通用的卷积神经网络硬件加速器,第二种是采用二值化权重以减少硬件加速器的计算量和硬件资源占用。最后,我们在赛灵思 Zynq‐7020 FPGA 上实现了我们的设计,具有较低的硬件资源占用。
| 表I. 二值化卷积神经网络(BCNN)的结果 | |||
|---|---|---|---|
| Mereices BCNN | |||
| 模型 | LeNet | AlexNet | VGG‐16 |
| 数据集 | MNIST | CIFAR‐10 | CIFAR‐10 |
| Tech | Zynq 7Z020 FPGA | ||
| 频率 | 100兆赫兹 | ||
| FP | 1位 | ||
| BRAM | 4 | 11.5 | 32 |
| DSP48E | 11 | 12 | 18 |
| FF | 970 | 1,678 | 1,705 |
| LUT | 2,998 | 8,761 | 11,671 |
| 准确率 | 91% (‐5.7%) | 67.1% (‐7.1%) | 44.3% (‐15.3%) |
| 帧率(赫兹) | 1570 | 154 | 21 |
| 表II. GCNN结果 | |||
|---|---|---|---|
| Mereices GCNN | |||
| 模型 | LeNet | AlexNet | VGG‐16 |
| 数据集 | MNIST | CIFAR‐10 | CIFAR‐10 |
| Tech | Zynq 7Z020 FPGA | ||
| 频率 | 100兆赫兹 | ||
| FP | 16位 | ||
| BRAM | 16.5 | 75 | 221 |
| DSP48E | 13 | 16 | 20 |
| FF | 3,316 | 10,357 | 10,525 |
| LUT | 10,390 | 36,278 | 60,674 |
| 准确率 | 96.7% | 74.2% | 59.6% |
| 帧率(赫兹) | 1570 | 154 | 21 |

















 4114
4114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









