




在深入理解了注意力机制和Encoder-Decoder架构后,来到了最激动人心的环节——亲手搭建一个完整的Transformer模型。深入理解Embedding层和位置编码的工作原理,分享实践的心得体会。
一、Embedding层:
1.1 Embedding的核心作用
技术定义:将离散的token索引映射为连续的向量表示
工作流程:
-
输入:
(batch_size, seq_len)的索引矩阵 -
输出:
(batch_size, seq_len, embedding_dim)的向量矩阵
代码实现:
self.tok_embeddings = nn.Embedding(args.vocab_size, args.dim)实例说明:
# 假设词表大小为4,输入"我喜欢你"
输入索引: [[0, 1, 2]] # 对应["我", "喜欢", "你"]
输出向量:
[
[0.1, 0.2, 0.3, 0.4], # "我"的向量表示
[0.2, 0.3, 0.4, 0.5], # "喜欢"的向量表示
[0.3, 0.4, 0.5, 0.6] # "你"的向量表示
]个人理解:Embedding层就像本"词典",每个词对应一个向量"定义",让模型能理解词汇的语义。
1.2 Embedding的技术细节
学习机制:
-
Embedding矩阵是可训练参数
-
通过反向传播学习词汇的语义关系
-
语义相似的词在向量空间中距离相近
心得:预训练的Embedding往往能显著提升模型性能,特别是在数据量不足的情况下。
二、位置编码:
2.1 为什么需要位置编码?
核心问题:自注意力机制是位置无关的
-
"我喜欢你"和"你喜欢我"在模型看来完全相同
-
但实际语义截然不同
解决方案:位置编码为每个位置生成独特的"位置指纹"
2.2 正弦余弦位置编码
数学公式:
PE(pos, 2i) = sin(pos / 10000^(2i/d_model))
PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))代码实现:
class PositionalEncoding(nn.Module):
def __init__(self, args):
super().__init__()
# 创建位置编码矩阵
pe = torch.zeros(args.block_size, args.n_embd)
position = torch.arange(0, args.block_size).unsqueeze(1)
# 计算频率项
div_term = torch.exp(
torch.arange(0, args.n_embd, 2) * -(math.log(10000.0) / args.n_embd)
)
# 分别计算正弦和余弦
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe) # 注册为缓冲区,不参与训练
def forward(self, x):
return x + self.pe[:, :x.size(1)].requires_grad_(False)2.3 位置编码的数学原理
相对位置关系:
# 关键性质:PE(pos + k) 可以用 PE(pos) 线性表示
# 这使模型能够学习相对位置关系-
通过复数运算证明相对位置的可表示性
-
正弦余弦函数的周期性支持长序列
-
不同频率的组合提供丰富的位置信息
心得:位置编码的设计体现了深度学习中的"归纳偏置"——通过先验知识帮助模型更好地学习。
三、完整Transformer实现
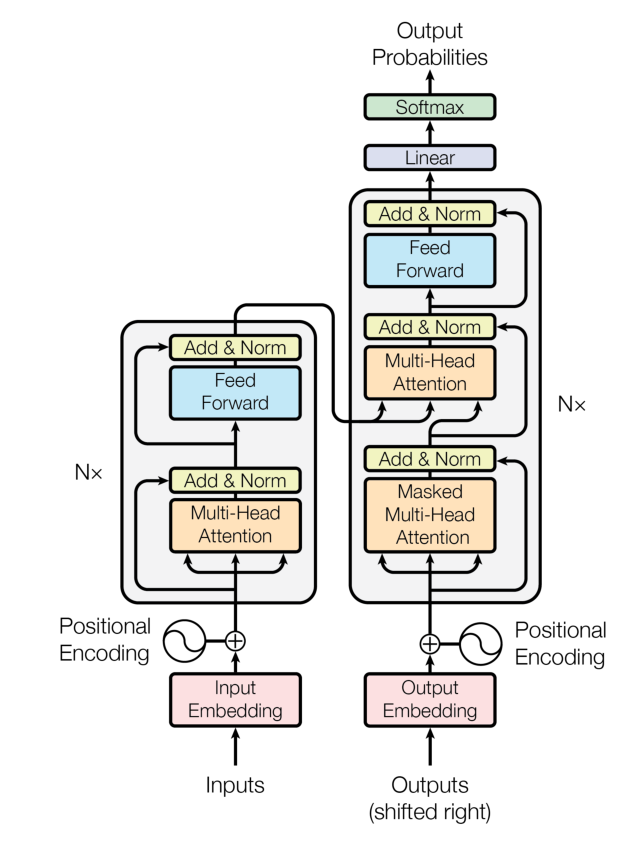
3.1 模型架构总览
class Transformer(nn.Module):
def __init__(self, args):
super().__init__()
self.args = args
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(args.vocab_size, args.n_embd), # Token Embedding
wpe = PositionalEncoding(args), # 位置编码
drop = nn.Dropout(args.dropout), # Dropout层
encoder = Encoder(args), # 编码器
decoder = Decoder(args), # 解码器
))
self.lm_head = nn.Linear(args.n_embd, args.vocab_size, bias=False) # 输出层3.2 前向传播流程
def forward(self, idx, targets=None):
# 1. Token Embedding
tok_emb = self.transformer.wte(idx) # (batch, seq_len) → (batch, seq_len, dim)
# 2. 位置编码
pos_emb = self.transformer.wpe(tok_emb) # 加入位置信息
# 3. Dropout
x = self.transformer.drop(pos_emb)
# 4. 编码器
enc_out = self.transformer.encoder(x) # 编码输入序列
# 5. 解码器
x = self.transformer.decoder(x, enc_out) # 解码生成输出
# 6. 输出层
if targets is not None:
logits = self.lm_head(x) # 训练模式:计算所有位置
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
else:
logits = self.lm_head(x[:, [-1], :]) # 推理模式:只计算最后一个位置
loss = None
return logits, loss3.3 关键实现细节
参数初始化:
def _init_weights(self, module):
# 线性层和Embedding层使用正态分布初始化
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)参数统计:
def get_num_params(self, non_embedding=False):
n_params = sum(p.numel() for p in self.parameters())
if non_embedding:
n_params -= self.transformer.wte.weight.numel() # 排除Embedding参数
return n_params四、Pre-Norm vs Post-Norm
4.1 架构差异
原始论文(Post-Norm):
输出 = LayerNorm(输入 + 子层(输入))现代实现(Pre-Norm):
4.2 选择Pre-Norm的原因
训练稳定性:
-
Pre-Norm让梯度流动更顺畅
-
减少梯度消失/爆炸问题
-
更适合深层网络
现代大语言模型(如LLaMA、GPT)普遍采用Pre-Norm结构
五、个人心得
Transformer架构的精髓在于它完美模拟了人类理解语言的思维方式。当我们阅读一篇文章时,我们不会机械地逐字阅读,而是会快速扫视全文,同时捕捉关键词、理清逻辑关系、理解上下文语境——这正是Transformer自注意力机制的核心思想。它的Embedding层如同为每个词语赋予了独特的"人格特征",位置编码则像给词语标注了精确的"坐标",而多头注意力机制就如同多个专业分析师同时从不同角度解读文本:一个关注语法结构,一个分析情感色彩,一个梳理逻辑关系。这种设计让模型摆脱了传统RNN必须"逐字咀嚼"的束缚,实现了"纵观全局"的突破性进化。更重要的是,这种并行处理的思想不仅大幅提升了计算效率,更关键的是让模型建立了真正的语义理解能力——它能瞬间把握"它"指代的是前文的哪个名词,能理解"虽然...但是..."之间的转折关系,能捕捉字里行间的言外之意。这正是为什么Transformer能够成为大语言模型基石的根本原因:它不是在机械地处理文字,而是在构建一个立体的、关联的、深层次的语义网络,这让我们向真正的机器理解人类语言迈出了最关键的一步。
资料来源:Happy-LLM

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









