




3.1 Encoder-only PLM
3.1.1 BERT
配合下文食用:
(42 封私信 / 80 条消息) 读懂BERT,看这一篇就够了 - 知乎![]() https://zhuanlan.zhihu.com/p/403495863
https://zhuanlan.zhihu.com/p/403495863
BERT 是一个统一了多种思想的预训练模型。其所沿承的核心思想包括:Transformer 架构和预训练+微调范式。
模型架构——Encoder Only
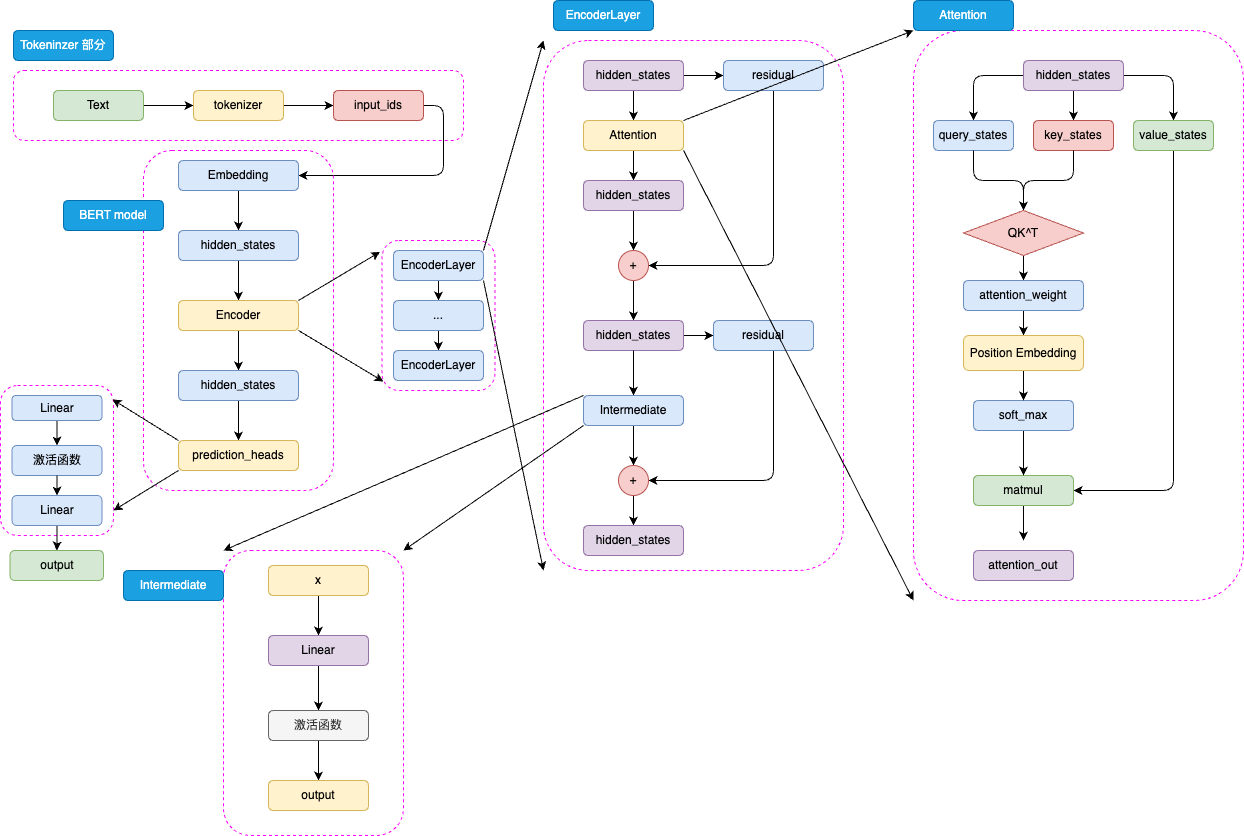 BERT整体既是由 Embedding、Encoder 加上 prediction_heads 组成。
BERT整体既是由 Embedding、Encoder 加上 prediction_heads 组成。
Embedding部分:文本序列Text通过分词器tokenizer转化为input_ids,然后进入Embedding层转化为特定维度的hidden_stats(包含Token Embeddings,Segment Embeddings以及Position Embeddings)。
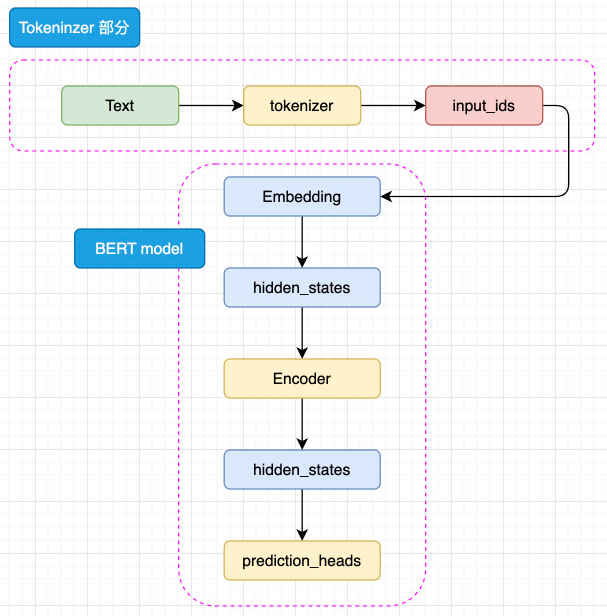
Encoder部分:进过Embedding转化后的hidden_states在金国Encoder块。Encoder 块中是对叠起来的 N 层 Encoder Layer。
BERT 有两种规模的模型,分别是 base 版本(12层 Encoder Layer,768 的隐藏层维度,总参数量 110M),large 版本(24层 Encoder Layer,1024 的隐藏层维度,总参数量 340M)。
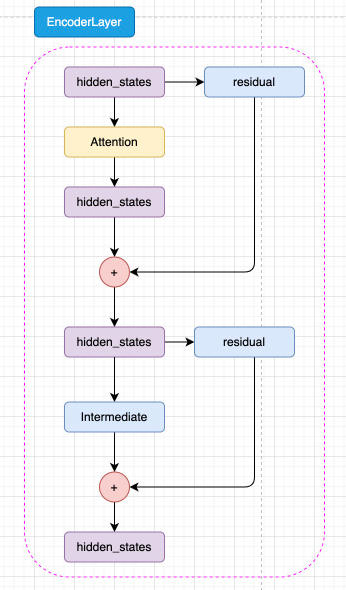
EncoderLayer: 每一层 Encoder Layer 都是和 Transformer 中的 Encoder Layer 结构类似的层。在EncoderLayer中,hidden_states先经过attention块。
在attention块中,hidden_states先完成注意力分数的计算获得attention_weight,再通过Position Embedding 层来融入相对位置信息,在进行softmax操作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









