




本文将带学习T5模型的核心思想与实现原理。
一、从BERT到T5:NLP模型的演进之路
在上一节中,我们学习了Encoder-Only结构的BERT模型,它通过MLM和NSP预训练任务学习文本的双向语义关系,在下游任务中表现出色。然而,BERT也存在一些问题:
-
预训练与微调的不一致性:MLM任务与生成类任务存在差异
-
长度限制:无法处理超过预训练长度的输入
-
任务特定设计:不同任务需要不同的模型头部
Encoder-Decoder模型的优势在于它能够自然地处理序列到序列的任务,既理解输入又生成输出,这为NLP任务提供了更加统一的解决方案。
二、T5模型概述:文本到文本的统一框架
T5(Text-To-Text Transfer Transformer)由Google提出,其核心思想是:将所有NLP任务都统一为文本到文本的转换问题。
2.1 统一框架的魅力
想象一下,无论是文本分类、翻译、摘要还是问答,都使用相同的输入输出格式:
输入: "分类: 这部电影很棒"
输出: "正面"
输入: "翻译英文到中文: I love you"
输出: "我爱你"三、T5模型架构详解
3.1 整体结构:编码器-解码器的完美结合
T5采用经典的Encoder-Decoder结构:
-
Encoder:负责理解输入文本,提取语义特征
-
Decoder:基于Encoder的理解生成输出文本
这种结构就像人类的理解与表达过程:先理解问题,再组织答案。
3.2 核心组件:Transformer块的堆叠
T5的Encoder和Decoder都由多个Transformer块堆叠而成,每个块包含:
# 简化的Transformer块结构
class TransformerBlock:
def __init__(self):
self.self_attention = MultiHeadAttention() # 自注意力机制
self.cross_attention = MultiHeadAttention() # 编码器-解码器注意力(仅Decoder)
self.feed_forward = FeedForwardNetwork() # 前馈神经网络
self.norm = RMSNorm() # 归一化层3.3 关键技术改进
RMSNorm归一化:
T5采用了RMSNorm而非传统的LayerNorm,公式为:
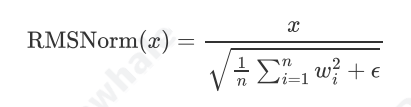
这种归一化方法参数更少,训练更稳定,在实践中表现出色。
四、预训练任务:掩码语言建模
T5的预训练延续了BERT的MLM思想,但有重要改进:
4.1 动态掩码策略
-
随机掩蔽15%的输入token
-
使用特殊标记替换被掩蔽的部分
-
模型需要预测被掩蔽的原始内容
4.2 大规模高质量数据
T5使用C4数据集(Colossal Clean Crawled Corpus):
-
规模:750GB清洗过的英文文本
-
质量:经过严格的数据清洗和去重
-
多样性:涵盖网页内容、新闻、书籍等
五、T5的大一统思想:NLP的通用解决方案
5.1 统一的任务格式
T5的核心创新在于将所有NLP任务都转换为相同的文本到文本格式:
| 任务类型 | 输入格式 | 输出格式 |
|---|---|---|
| 文本分类 | "分类: [文本]" | "类别" |
| 翻译 | "翻译英文到中文: [文本]" | "翻译结果" |
| 摘要 | "摘要: [长文本]" | "摘要内容" |
| 问答 | "问题: [问题] 上下文: [文本]" | "答案" |
5.2 实际应用示例
让我们通过具体例子理解T5如何处理不同任务:
# 情感分析
输入: "情感分析: 我喜欢这个产品"
输出: "正面"
# 机器翻译
输入: "翻译英文到中文: Hello world"
输出: "你好世界"
# 文本摘要
输入: "摘要: 今天天气很好,阳光明媚..."
输出: "天气晴朗"5.3 前缀指令的重要性
任务前缀(如"分类:"、"翻译:")起到了指令提示的作用,告诉模型应该执行什么类型的任务。这种设计让模型学会了根据指令切换工作模式。
六、心得体会
T5的成功让我深刻认识到,优秀的技术应该是"用人话沟通"的。模型通过简单的前缀指令就能理解用户意图并切换工作模式,这启示我们:真正的智能不在于模型的复杂度,而在于它能多自然地理解人类的表达方式。这种设计思路值得所有AI产品借鉴——让技术适应人,而不是让人去适应技术。
资料来源:Happy-LLM

















 770
770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









