




深入理解大语言模型的核心架构,探寻Decoder-Only成为LLM主流选择的技术必然性
引言:为什么是Decoder-Only?
在深入学习自然语言处理技术的过程中,我逐渐意识到模型架构的选择往往决定了技术路线的成败。从Transformer出发,预训练语言模型发展出了三条主要技术路径:
-
Encoder-Only架构:以BERT为代表,擅长理解任务
-
Encoder-Decoder架构:以T5为代表,适合序列转换任务
-
Decoder-Only架构:以GPT为代表,专精文本生成
Decoder-Only架构我想结合自己的学习实践,分享对Decoder-Only架构的深入理解和思考。
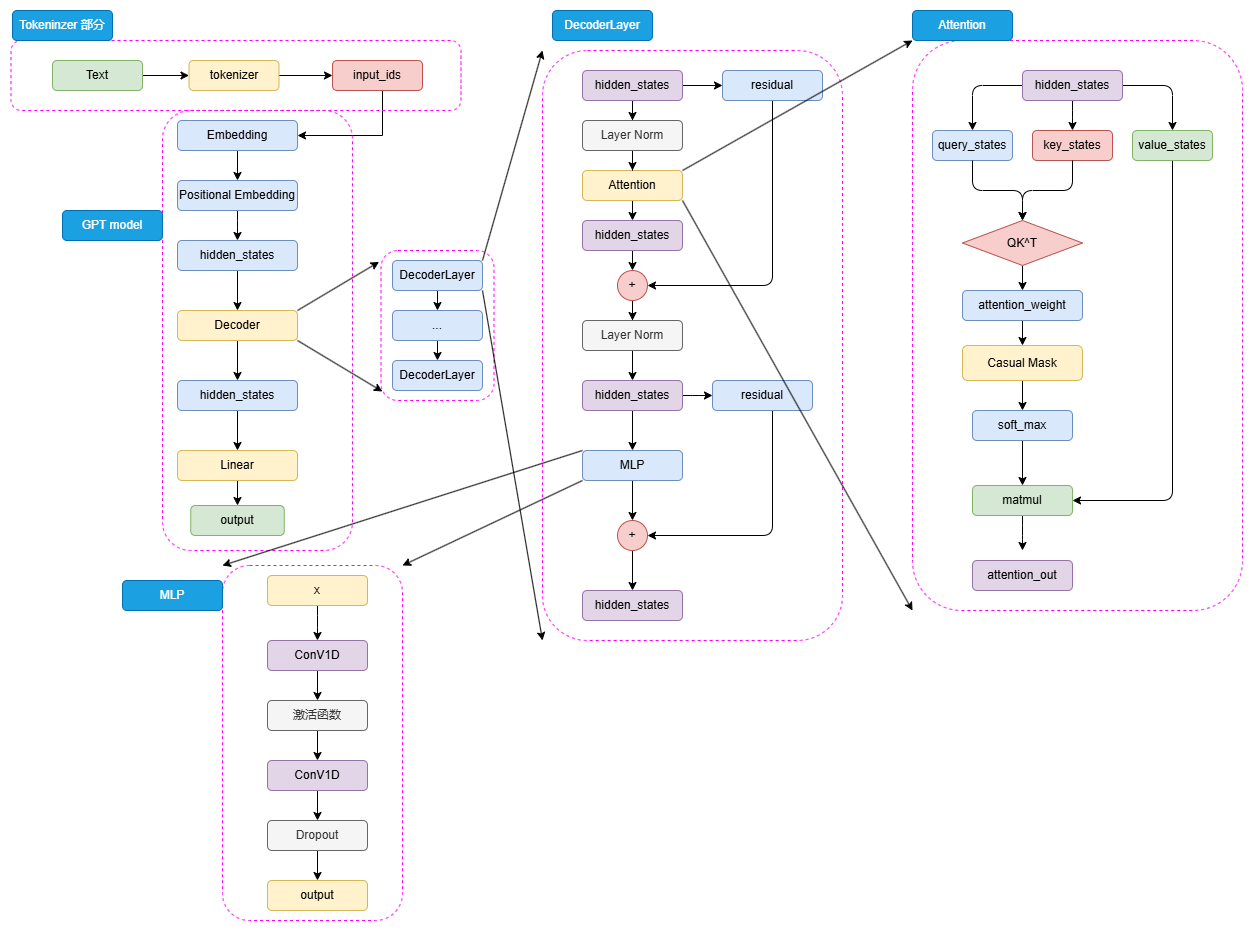
一、GPT系列:坚持与突破的技术启示
1.1 GPT-1
技术特点:
-
12层Transformer Decoder堆叠
-
Sinusoidal位置编码
-
掩码自注意力机制
-
因果语言模型(CLM)预训练
学习心得:
GPT-1最让我佩服的是其前瞻性。虽然当时BERT在各项基准测试中表现更优,但OpenAI团队坚持的生成式预训练思路和Decoder-Only架构,为后续的突破奠定了坚实基础。
1.2 GPT-2
技术突破:
-
参数量从1.17亿扩大到15亿
-
预训练数据从5GB扩展到40GB
-
提出zero-shot学习概念
-
使用Pre-LayerNorm提升训练稳定性
1.3 GPT-3
核心贡献:
-
参数量达到1750亿
-
提出few-shot learning(上下文学习)
-
稀疏注意力机制优化
-
在570GB高质量数据上训练
学习心得:
GPT-3的few-shot能力让我意识到,大语言模型已经具备了从少量示例中抽象模式和规律的能力。这种上下文学习能力,使得AI应用的开发门槛大幅降低。
# 上下文学习的示例对比
# zero-shot
prompt = "请判断'这个电影太精彩了'的情感倾向:正面/负面"
# few-shot
prompt = """
请判断以下文本的情感倾向:
1. '这个产品很好用' -> 正面
2. '服务态度很差' -> 负面
3. '电影剧情很吸引人' -> 正面
4. '这个电影太精彩了' ->
"""二、LLaMA系列:开源的力量
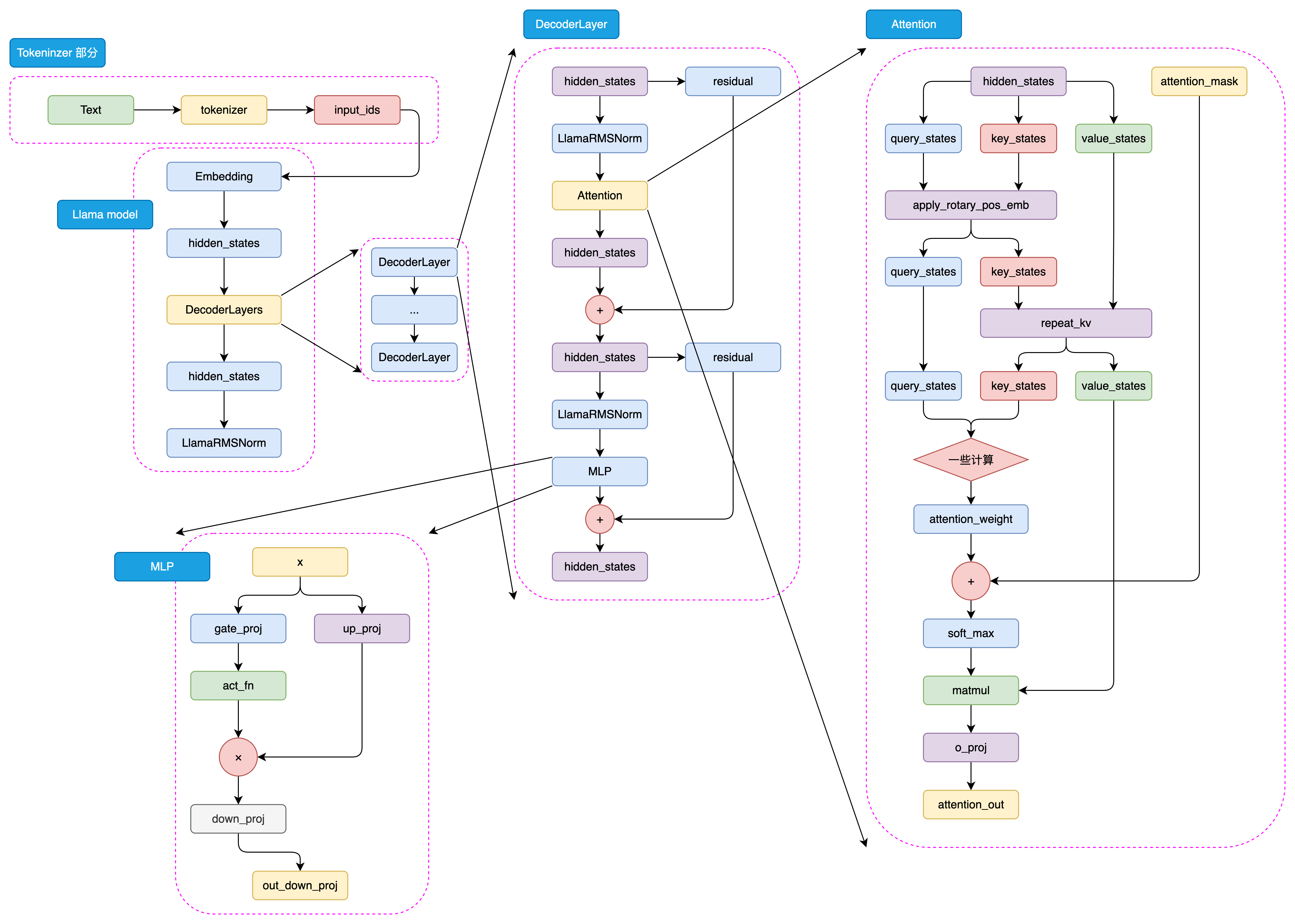
2.1 架构优化亮点
关键技术改进:
-
旋转位置编码(RoPE):更好地处理长序列
-
SwiGLU激活函数:替代传统的ReLU
-
分组查询注意力(GQA):降低推理内存占用
-
Pre-LayerNorm:提升训练稳定性
学习心得:
在本地部署LLaMA模型的过程中,我深刻体会到这些"小而美"的优化带来的实际收益。特别是GQA机制,在保持性能的同时显著降低了推理显存需求,让更多开发者能够在消费级硬件上运行大模型。
2.2 训练策略演进
| 版本 | 训练数据 | 上下文长度 | 关键特性 |
|---|---|---|---|
| LLaMA-1 | 1T token | 2K | 开源奠基 |
| LLaMA-2 | 2T token | 4K | 引入GQA |
| LLaMA-3 | 15T token | 8K | 128K词表 |
心得体会:
从LLaMA系列的发展可以看出,数据质量与数据规模同样重要。LLaMA-3使用的15T token经过严格清洗过滤,对数据质量的重视。
三、GLM系列:中文LLM的创新探索
3.1 架构微创新
与GPT的差异:
-
使用Post-LayerNorm而非Pre-LayerNorm
-
简化输出层,使用单个线性层
-
采用GeLU激活函数替代ReLU
心得体会:
GLM在架构上的微调尝试告诉我,没有绝对的最优架构,只有最适合当前约束的架构。虽然这些改动未被主流采纳,但这种探索精神推动了技术发展。
3.2 GLM预训练任务:融合的创新
核心思想:
将MLM的完形填空与CLM的自回归生成相结合,通过自回归空白填充任务统一理解和生成能力。
# GLM预训练任务示例
输入: "我今天感觉很<mask>,因为考试<mask>"
输出: "<mask>->高兴</mask>; <mask>->考得很好</mask>"学习心得:
GLM的这种设计体现了架构设计中的平衡艺术。虽然在大模型时代,纯CLM展现出更强优势,但GLM的尝试为多任务学习提供了宝贵思路。
四、关键技术思考
4.1 为什么CLM优于MLM?
通过对比,我理解到CLM的优势在于:
-
任务一致性:预训练与下游生成任务完全一致
-
渐进式学习:从左到右的生成方式更符合人类思维
-
更好的泛化:自回归方式迫使模型学习更深层的语言规律
4.2 注意力机制的演进
从原始Transformer到LLaMA的GQA,注意力机制的优化路径清晰可见:
-
MHA:原始多头注意力,效果最好但计算量大
-
MQA:共享key和value,大幅减少参数
-
GQA:分组共享,平衡效果与效率
在资源受限场景下,GQA确实提供了更好的权衡。
五、学习心得与总结
通过系统学习Decoder-Only架构的技术演进,我深刻体会到:技术的发展从来不是一蹴而就的,而是在坚持、试错和优化中逐步前进的。从最初被BERT"压制"的GPT-1,到如今引领AI革命的GPT-4,这条技术路线的发展历程充满了启示。
作为技术学习者,我们不仅要掌握当前的最优解,更要理解技术演进的脉络和背后的设计思想。只有这样,才能在快速变化的技术浪潮中保持洞察力,为未来的技术突破贡献自己的力量。
资料来源:Happy-LLM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









