




文章目录:
本节的主要目标是“动手”,从理论走向实践,真正地把大模型用起来。
-
-掌握通过 API 调用云端大模型的基本方法。
-
-掌握使用 transformers 库在本地运行大模型的基本流程。
-
-了解 vLLM 等高性能推理框架的用途和基本使用方法。
1.1云端API调用:无需考虑电脑配置,便捷使用
本次实训将以硅基流动平台为例,它提供了与 OpenAI API 完全兼容的接口,我们可以直接使用 OpenAI 中的 Python 库调用模型。
注:可以使用`openai` 库的方式来调用云端大模型,向远程服务器发送请求,也可以使用 python 中的 `requests` 库,以发送网络请求的方式也可以实现云端大模型的调用。
访问硅基流动平台官网,注册账号(免费赠送14元),在个人中心找到你的 API Key(密钥) 和 API Base URL(接口地址)。请务必保管好你的 API Key,不要泄露给别人哈。
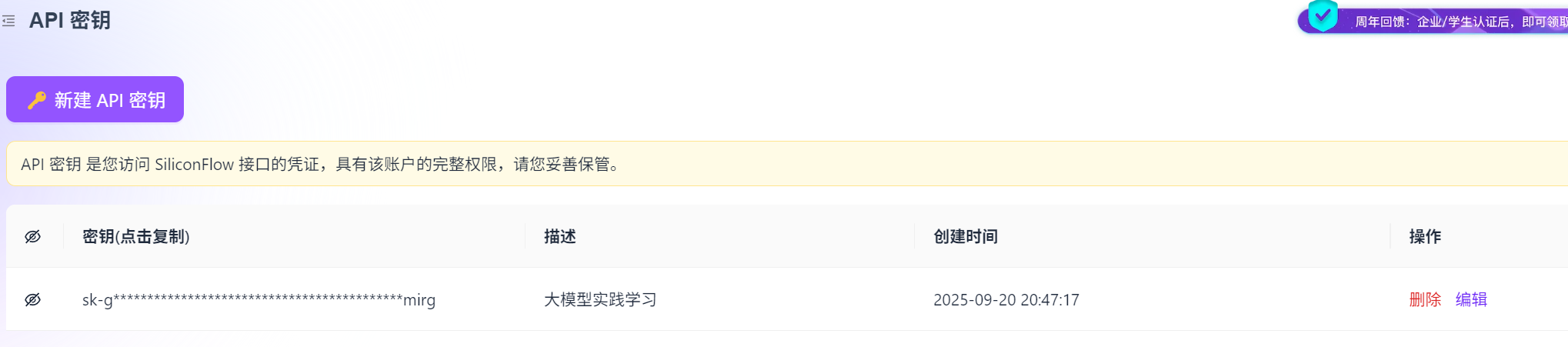
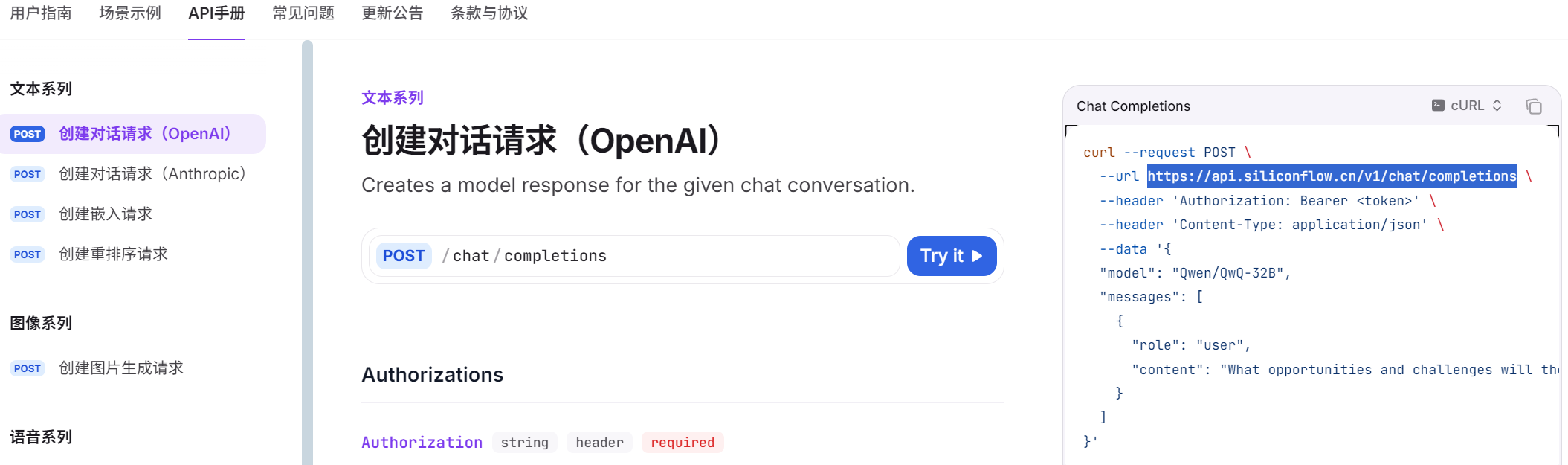
API Base URL(接口地址)在模型处找到需要的大模型,点击API文档内就有接口地址,本次项目需要调用“Qwen/Qwen3-8B”。API Base URL:https://api.siliconflow.cn/v1/chat/completions
1.2 调用大模型
接下来,我们安装`openai`库,使用清华镜像源下载,用于调用大模型。
!pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple!pip install -q openai使用以下Pyhon代码调用云端API大模型:
from openai import OpenAI
client = OpenAI(api_key="you_api_key",
base_url="https://api.siliconflow.cn/v1")
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{'role': 'user', 'content': "来一首古诗"}
],
max_tokens=1024,
temperature=1.0,
stream=False
)
print(response.choices[0].message.content)以下是我调用Qwen3-8B大模型的回答:
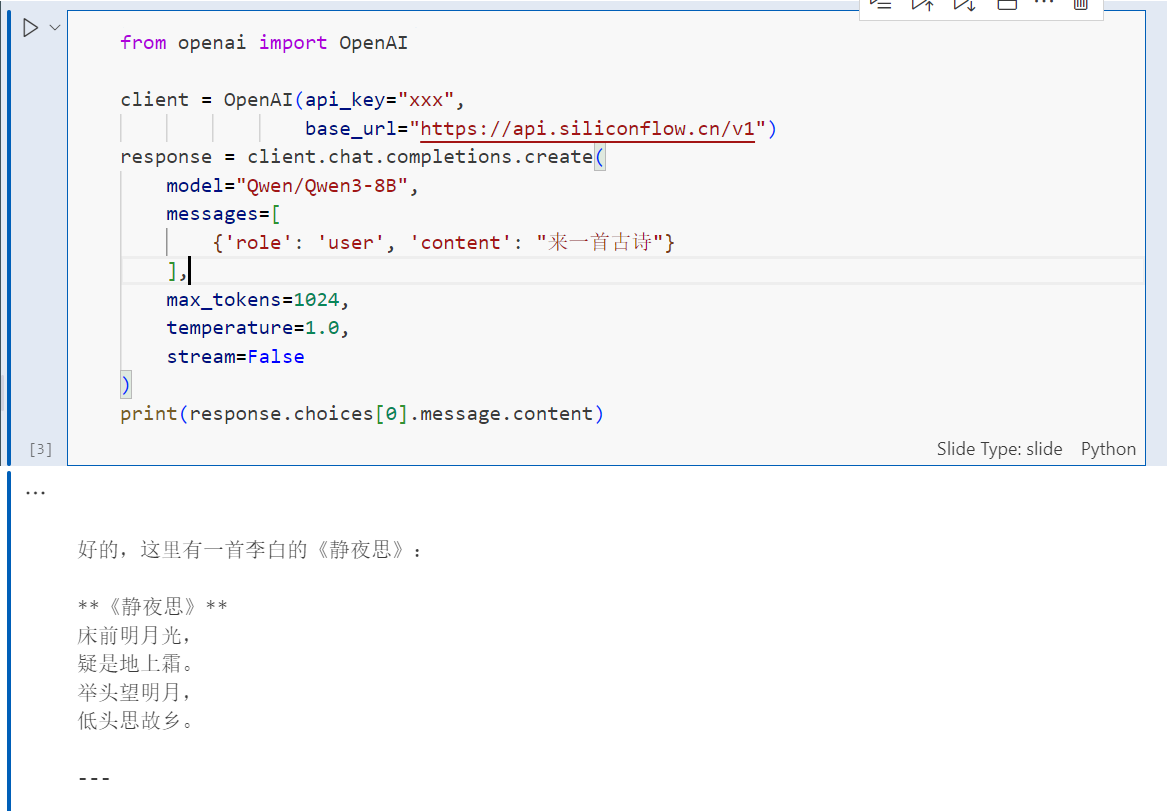
但是,我们会发现stream设置为False了,那么设置为True会怎么样呢?stream如果是False大模型就是一次性全部输出,设为True就会像deepseek一样的流式输出(逐字输出)。
以下是我的更改流式输出的代码,大家可以参考:
from openai import OpenAI
client = OpenAI(
api_key="x'x'x",
base_url="https://api.siliconflow.cn/v1"
)
# 将stream参数改为True
response = client.chat.completions.create(
model="Qwen/Qwen3-8B",
messages=[
{'role': 'user', 'content': "鼓励一下我学习大模型!"}xxx
],
max_tokens=1024,
temperature=0.9,
stream=True # 这里改为True
)
# 处理流式响应
for chunk in response: # 遍历API返回的每个数据块
if chunk.choices[0].delta.content:# 检查刚传来的数据包里,有没有新的文字内容
print(chunk.choices[0].delta.content, en 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2633
2633



 到【灌水乐园】发言
到【灌水乐园】发言








