




声明:语音合成(TTS)论文优选系列主要分享论文,分享论文不做直接翻译,所写的内容主要是我对论文内容的概括和个人看法。如有转载,请标注来源。
欢迎关注微信公众号:低调奋进
IMPROVING LPCNET-BASED TEXT-TO-SPEECH WITH LINEAR PREDICTION-STRUCTURED MIXTURE DENSITY NETWORK
本文章是2020年1月韩国延世大学等发表的文章,主要工作是对LPCNet进行优化,使其保持原来的复杂度前提下,提高合成的语音质量,具体的文章链接https://arxiv.org/pdf/2001.11686.pdf
(最近看了lpcent的文章已经不少,打算对lpcnet做个总结,主要关于lpcnet的优化策略)
1 研究背景
神经网络声码器的出现使合成质量大大提高,比如wavenet,wavernn等等。利用声学的源滤波模型的声码器LPCNET相较其它声码器来说,其合成质量高,复杂度较低,因此受到从业者的欢迎。但Lpcnet模型并没有完全利用语音合成的机制,而且激励参数使用u-law量化造成不稳定现象。针对以上问题,本文做出以下贡献 1)提出基于LP-MDN的声码器ilpcnet,该声码器可以充分利用lp和激励之间的关系,替换原来的激励u-law离散分布,使mos提高。2)提出训练和生成的策略,比如stft loss等等。
2 系统设计
首先看一下lpcnet的计算方式如公式1和2。其中e为激励使用神经网络进行采样,p通过公式计算。
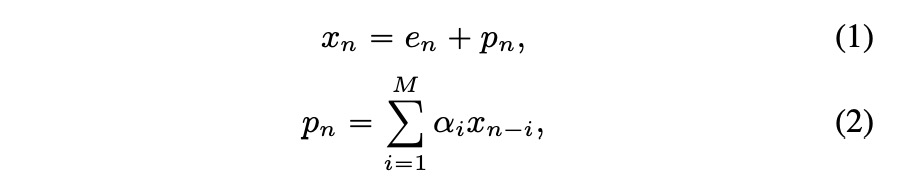
考虑到采样点和激励之间的分布关系,本文提出LP-MDN(mdn的均值、方差等参数是网络产生),该模型假设speehc和激励之间的分布关系如下图所示,因此可以使用神经网络进行w,u,s的预测。

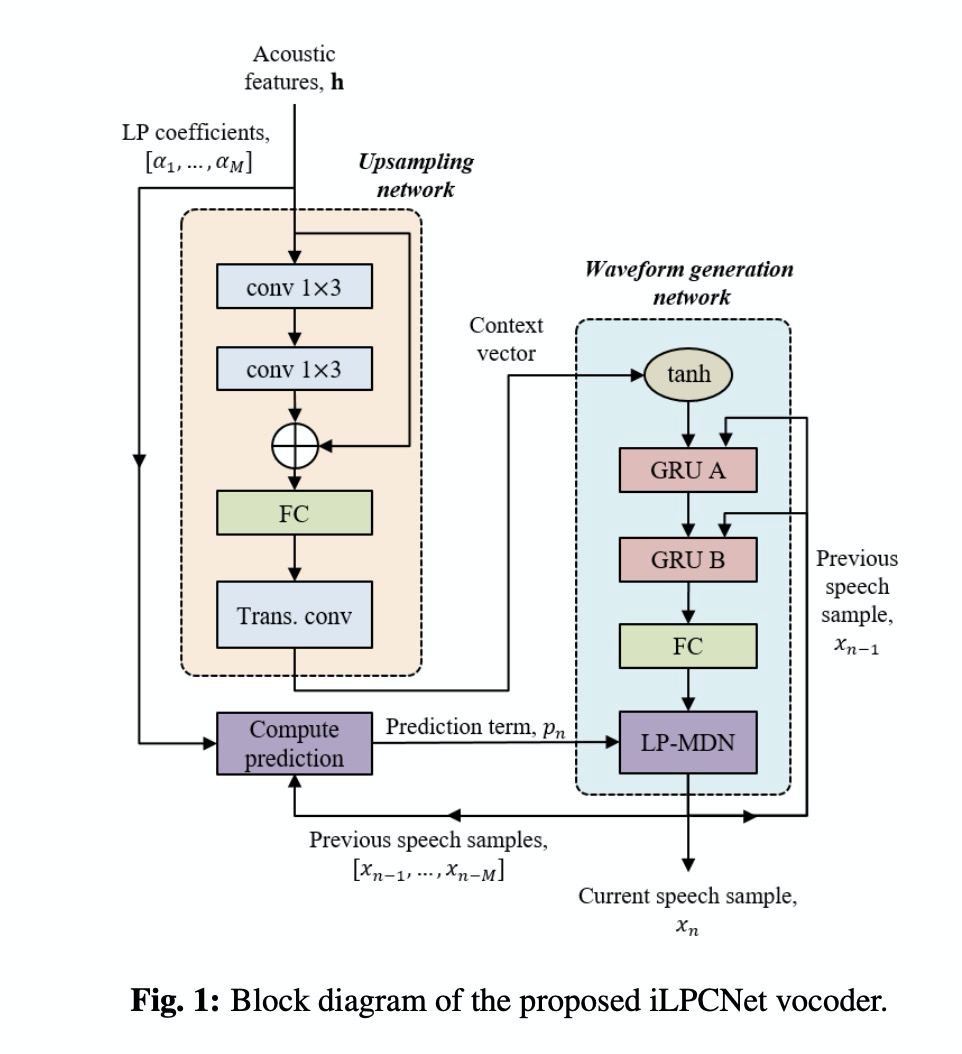
ilpcent主要把lp-mdn应用到原始的lpcent中,如图1所示,主要区别的几点是 1)upsampling network最后一层由fc替换成conv,;2)waveform generation network的grua的输入只有上一个采样点和frame feature;3)最后使用LP-MDN进行采样点生成。
另外本文使用了STFT loss,因此总的loss如公式7所示。

3 实验
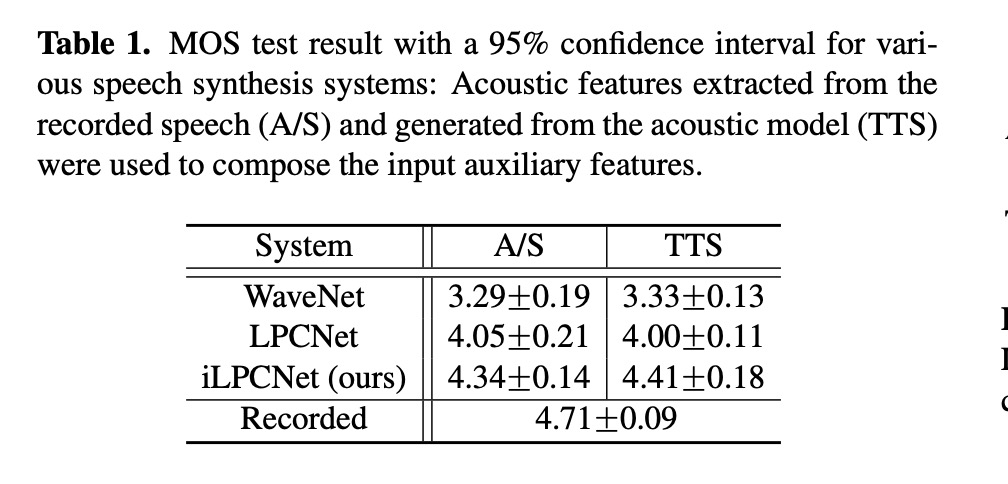
本文实验很简单,只对比合成质量MOS和ABtest。table 1显示本文提出的ilpcnet比原始的lpcnet提高0.4(这就厉害了,而且wavenet竟然这么点?仅仅做个参考吧!)ABtest测试也显示本文提出的方案ilpcnet远远比lpcnet较好。

4 总结
本文充分利用lp和激励的关系提出LP-MDN模型,并提出ilpcnet,是该声码器保持lpcnet的较低复杂度的优势前提下,提高了合成质量。


















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











