




 本文探讨了语音合成(TTS)和自动语音识别(ASR)结合的双重学习方法,旨在减少训练语料需求。文章介绍了四个相关研究,包括Listening while Speaking Speech Chain、Machine Speech Chain with One-shot Speaker Adaptation、Almost Unsupervised Text to Speech and Automatic Speech Recognition以及RSpeech-Extremely Low-Resource Speech Synthesis and Recognition,展示了如何通过相互学习改善TTS和ASR的性能。这些研究利用人类生理系统启发的模型,实现了一定程度的语音复刻和低资源语音合成。
本文探讨了语音合成(TTS)和自动语音识别(ASR)结合的双重学习方法,旨在减少训练语料需求。文章介绍了四个相关研究,包括Listening while Speaking Speech Chain、Machine Speech Chain with One-shot Speaker Adaptation、Almost Unsupervised Text to Speech and Automatic Speech Recognition以及RSpeech-Extremely Low-Resource Speech Synthesis and Recognition,展示了如何通过相互学习改善TTS和ASR的性能。这些研究利用人类生理系统启发的模型,实现了一定程度的语音复刻和低资源语音合成。
声明:工作以来主要从事TTS工作,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 低调奋进
欢迎关注个人公众号:低调奋进
写在文前:该方向不是我研究的方向,只是凭着兴趣阅读相关文章,对应的实验没有时间和资源做(不能占用公司的资源)。
目录
2.1 Listening while Speaking Speech Chain by Deep Learning
2.2 Machine Speech Chain with One-shot Speaker Adaptation
2.3 Almost Unsupervised Text to Speech and Automatic Speech Recognition
2.4 RSpeech- Extremely Low-Resource Speech Synthesis and Recognition
1 背景
世界存在6000多种语言,按照工业标准来制作高质量的TTS和ASR,每种语言获取训练语料(<speech,text>格式)的成本在10w美元以上[5],而且很多语言存在标注困难的问题,因此使用少数量的训练语料来训练TTS和ASR是迫切的需求。从研究发展阶段来看(早期单任务研究到成熟期的多任务融合研究),TTS和ASR联合训练是未来发展必然趋势。
2 研究情况
目前Dual Learning研究还处于初始阶段,根据最近文章的搜索,2018年日本nais发表两篇文章Machine Speech Chain with One-shot SpeakerAdaptation和Listening while SpeakingSpeech Chain by DeepLearning,接下来的文章主要出自微软,其中包括2019年的Almost Unsupervised Text to Speech and Automatic Speech Recognition和2020年的RSpeech-Extremely Low-Resource Speech Synthesis and Recognitio。
接下来我主要根据时间轴顺序来简单分享这四篇文章。
2.1 Listening while Speaking Speech Chain by Deep Learning
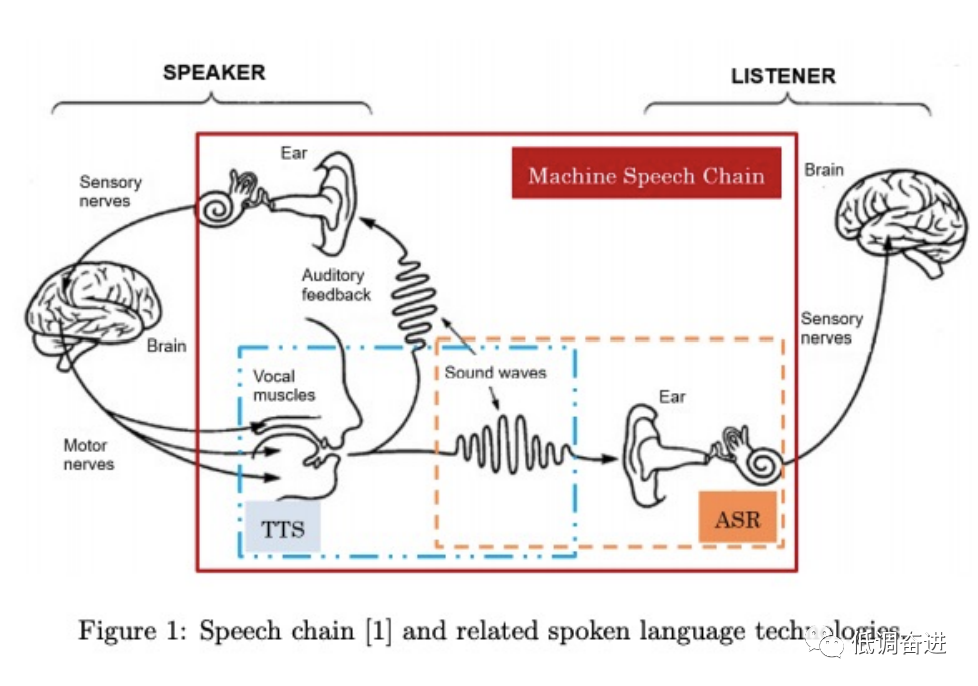
本文章主要阐述文章灵感来源主要人类的生理系统。对于人类而言(图一所示),人类的语音的产生和感知是互相促进的。比如,当你向别人说话的同时,不仅把话语传给对方,而且语音也被自己感知从而判断自己说的话是否正确,并纠正说话方式,这也是孩童时期学会说话的生理模式。但对于语言的研究,TTS和ASR却是相互独立的两个任务,因此作者提出了TTS和ASR相互学习的speech chain.
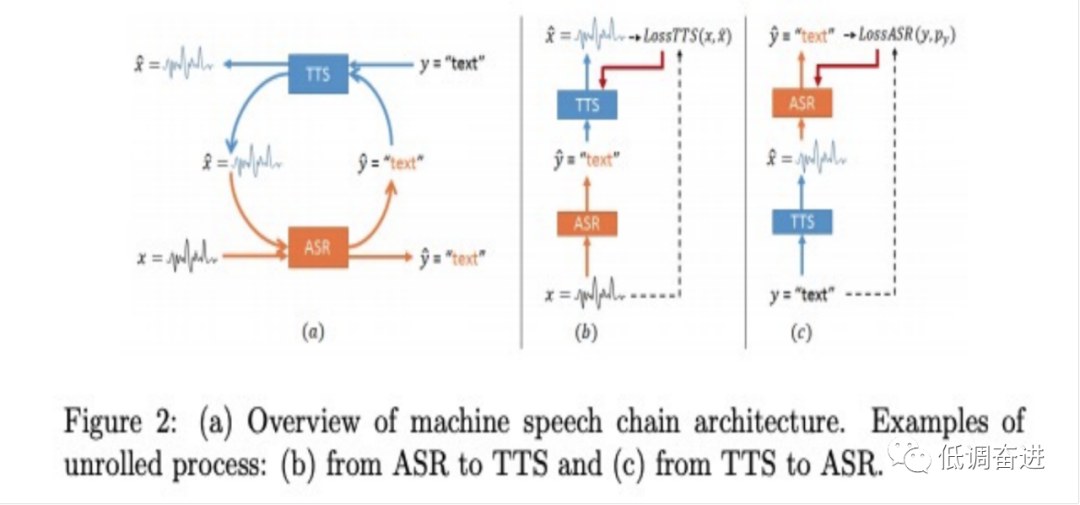
具体的speech chain如图二所示:a)是整个chain的架构,其中的训练chain由两部分组成speech->ASR->text->TTS->speech和text->TTS->speech->ASR->Text,具体的结构对应为图b和图c。
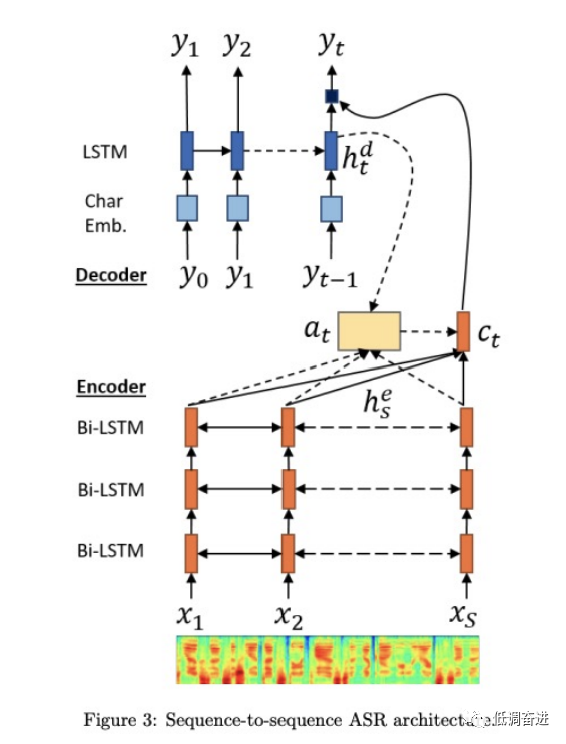
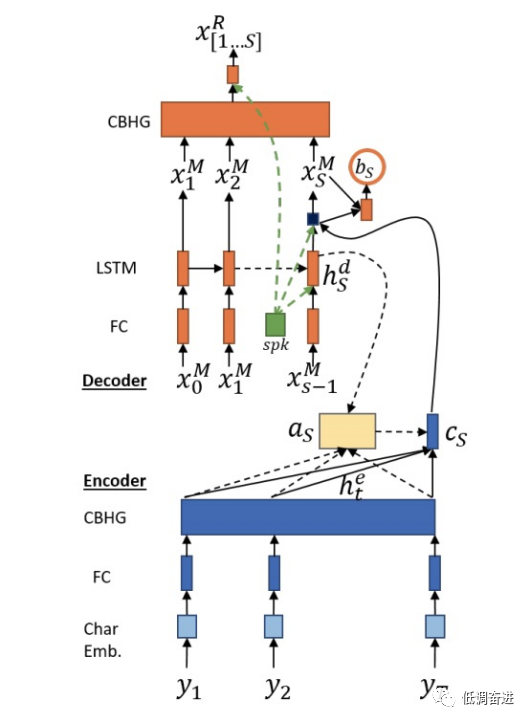
以上内容不难理解,就是使用不同的研究领域来优化另一个研究领域。接下来文章讲述所使用的ASR和TTS结构,其结构为encoder-attention-decoder的,具体如下图所示。ASR主要把语音的声学特征给映射到语言特征,TTS相反地把语言特征映射到声学特征,由于输入和输出是非等长的,因此需要attention模块进行对齐。
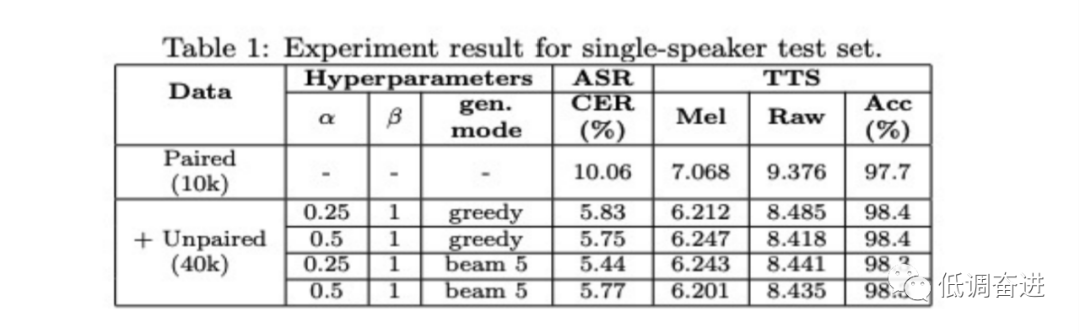
以上为该文章的大致内容,使用上述方法进行单人和多人的模型训练,从结果(table 1和table 2)可知,TTS和ASR的各项指标都得到提高(ASR的CER逐渐下降,TTS的acc得到提高),该文章没有给出TTS的MOS指标。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6512
6512





 到【灌水乐园】发言
到【灌水乐园】发言









