




 本文探讨了歌唱合成(Singing Voice Synthesis, SVS)的最新进展,特别是在数据充足和数据匮乏条件下的研究策略。在数据充足的情况下,系统架构设计和高采样率数据的应用成为关键;而在数据匮乏时,研究人员借助低质数据、歌声转换和迁移学习来提升合成质量。文章列举了多个实例,如ByteSing、XiaoIceSing、HiFiSinger和DeepSinger等,展示了如何通过创新方法克服训练语料的局限,实现高质量的歌唱合成。"
124421352,9205853,Python爬虫:停电公告解密抓取,"['Python爬虫', '数据解密', '网络爬虫', '加密技术', 'JavaScript']
本文探讨了歌唱合成(Singing Voice Synthesis, SVS)的最新进展,特别是在数据充足和数据匮乏条件下的研究策略。在数据充足的情况下,系统架构设计和高采样率数据的应用成为关键;而在数据匮乏时,研究人员借助低质数据、歌声转换和迁移学习来提升合成质量。文章列举了多个实例,如ByteSing、XiaoIceSing、HiFiSinger和DeepSinger等,展示了如何通过创新方法克服训练语料的局限,实现高质量的歌唱合成。"
124421352,9205853,Python爬虫:停电公告解密抓取,"['Python爬虫', '数据解密', '网络爬虫', '加密技术', 'JavaScript']
声明:工作以来主要从事TTS工作,工程算法都有涉及,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 低调奋进 TTS 开源数据 低调奋进。如转载,请标明出处。欢迎关注微信公众号:低调奋进
目录
1 研究背景
歌唱合成SVS(singing voice synthesis)是根据歌词和乐谱信息合成歌唱。相比于TTS(text to speech)使机器“开口说话”,歌唱合成则是让机器唱歌,因此更具有娱乐性。互联网的时代,人机交互更加频繁和智能,歌唱合成则添加了人机交互的趣味性,因此受到工业界和学术界的关注。相比TTS,歌唱合成需要更多的输入信息,比如乐谱中的音高信息,节拍信息等等。但是歌唱合成的训练语料十分昂贵,为获得较高品质的歌唱干声和乐谱信息,研究者需要付出上百万的开销,这也阻碍大量研究人员的脚步。本文针对2020年歌唱合成的发展状况,总结在是否拥有大量训练数据前提下采用的不同方案,以供同行参考。
各家demo的链接:
https://bytesings.github.io/paper1.html
https://xiaoicesing.github.io/
HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis - Speech Research
DurIAN-SC: Duration Informed Attention Network based Singing Voice Conversion System | [“DurIAN_SC”]
DeepSinger: Singing Voice Synthesis with Data Mined From the Web - Speech Research
2 研究情况
其实歌声合成(singing voice synthesis)的文章不算太多,本打算通读以后再做个总结,但思来想去还不如先总结之后,以后再慢慢修改,也算“敏捷”总结。我找的文章都是2020年的文章,这样可以看出去年歌唱合成的发展动态。我们知道,歌唱合成之所以没有像TTS这样受到强烈关注的原因之一就是训练语料的匮乏。相较普通音频的训练语料,歌唱合成的训练语料要贵好几倍,因此很少有企业和研究所能够承担此种开销。歌唱合成训练语料相比普通语料的成本较高的原因:1)需要专业歌手在专业的录音棚录制高音质的干声;2)歌声的标注需要更复杂的信息,标注成本较高。是否拥有充足的训练数据导致不同的研究方向和策略,因此我根据训练数据是否充足进行以下分类:
2.1 数据充足
2.1.1 系统架构设计
(a)ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders
(b)XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System
2.1.2 高采样率数据
(a)HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis
2.2 数据匮乏
2.2.1 低质数据
(a)Deepsinger: Singing voice synthesis with data mined from the web
2.2.2 歌声转换
(a)Durian-sc: Duration informed attention network based singing voice conversion system
2.2.2 迁移学习
(a)learn2sing target speaker singing voice synthesis by learning from a singing teacher
2.1 数据充足
2.1.1 系统架构设计
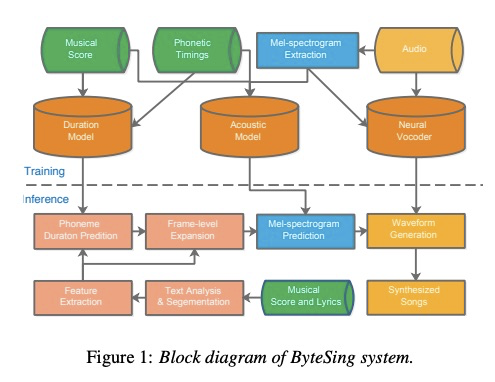
2.1.1.1 ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders
图一展示了ByteSing 系统的整体架构,该系统包含时长模型,声学模型和神经网络声码器。时长模型的输入为音素+音素类型+节奏和音符时长,输出为音素对应的时长。声学模型的输入为音素+音符音高+每帧的位置信息,输出为声学信息,具体为图2展示。看到图2结构可能大家跟我有相同的疑惑,既然时长模型已经预测出了每个音素时长,为什么还使用attention?本文在实验部分给出了实验结果:使用attention的效果更好。神经网络声码器是把声学特征转成波形,具体结构图3所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











