




如有转载,请注明出处。欢迎关注微信公众号:低调奋进。打算开始写LLM系列文章,主要从数据、训练框架、对齐等方面进行LLM整理。
Baichuan 2: Open Large-scale Language Models
原始文章链接
https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
github
https://github.com/baichuan-inc
hugginggface
https://huggingface.co/baichuan-inc
训练LLM的同行可以精读文章llama、llama2和baichuan2等文章,干货较多。本文不做翻译,主要罗列个人关注的重点。阅读本文的前提是已经对LLM熟悉,最好已经积累一定训练经验。本文干货较多,有的实验可以作为自己试验的指向标。
同时想阅读LLM的综述文章可以读以下文章:
A Survey of Large Language Models
https://arxiv.org/pdf/2303.18223.pdf
Large Language Models
https://arxiv.org/pdf/2307.05782.pdf
A Comprehensive Overview of Large Language Models
https://arxiv.org/pdf/2307.06435.pdf
A Survey on Evaluation of Large Language Models
https://arxiv.org/pdf/2307.03109.pdf
Is Prompt All You Need? No. A Comprehensive and Broader View of Instruction Learning
https://arxiv.org/pdf/2303.10475.pdf
|
模型名称 |
Baichuan 2-7b, Baichuan 2-13b, |
|
模型大小 |
7b, 13b |
|
支持语言 |
多语言 |
|
模型具体参数 |
|
|
预训练数据 |
2.6 T tokens |
|
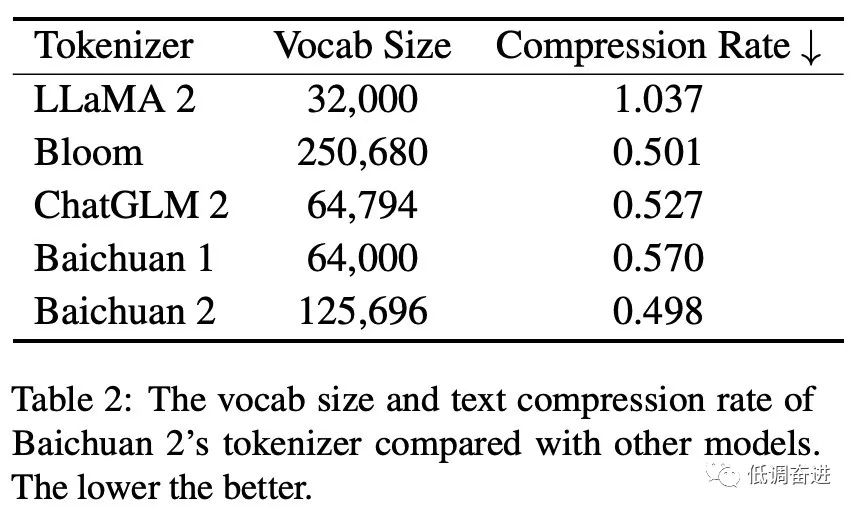
模型tokenizer |
|
|
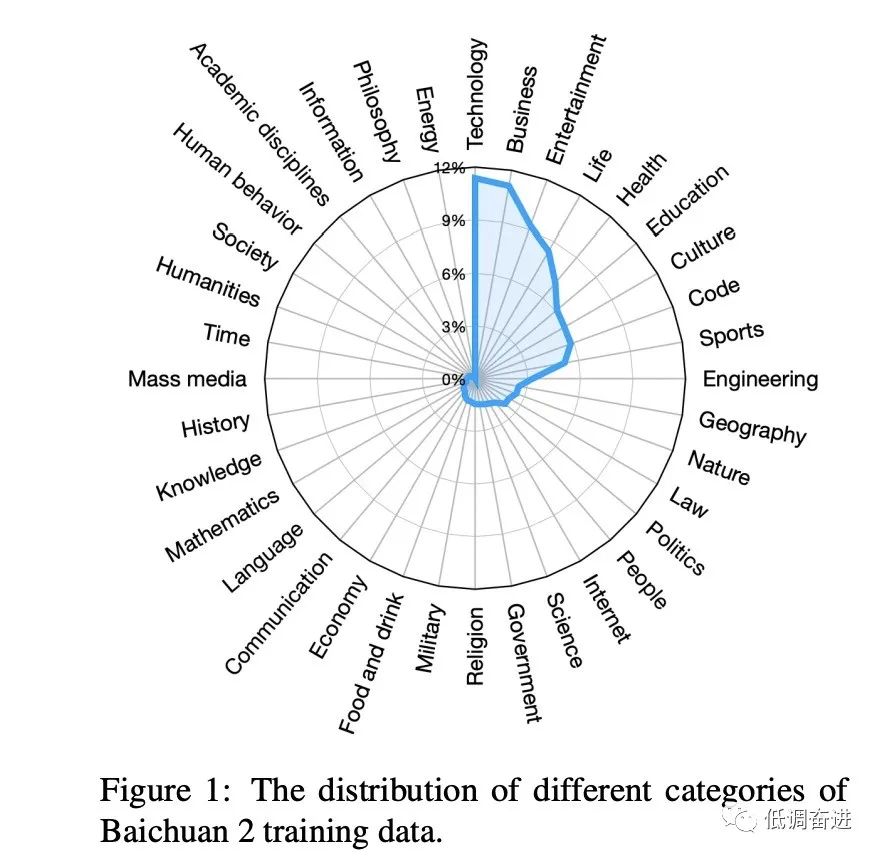
预训练数据分类占比 |
|
|
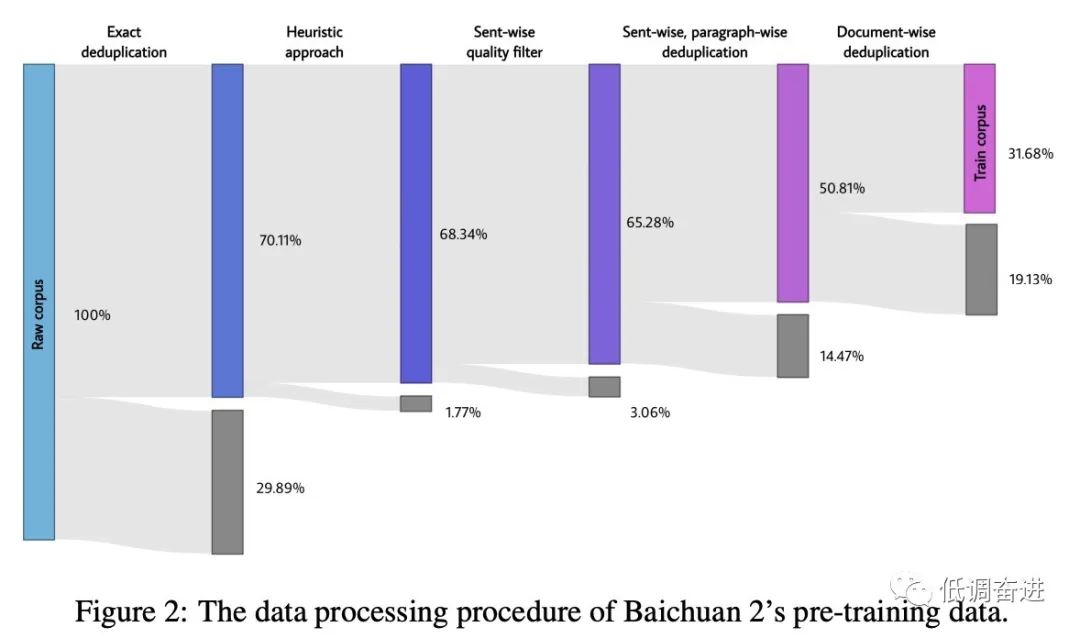
预训练数据处理流程 |
|
|
预训练改进点 |
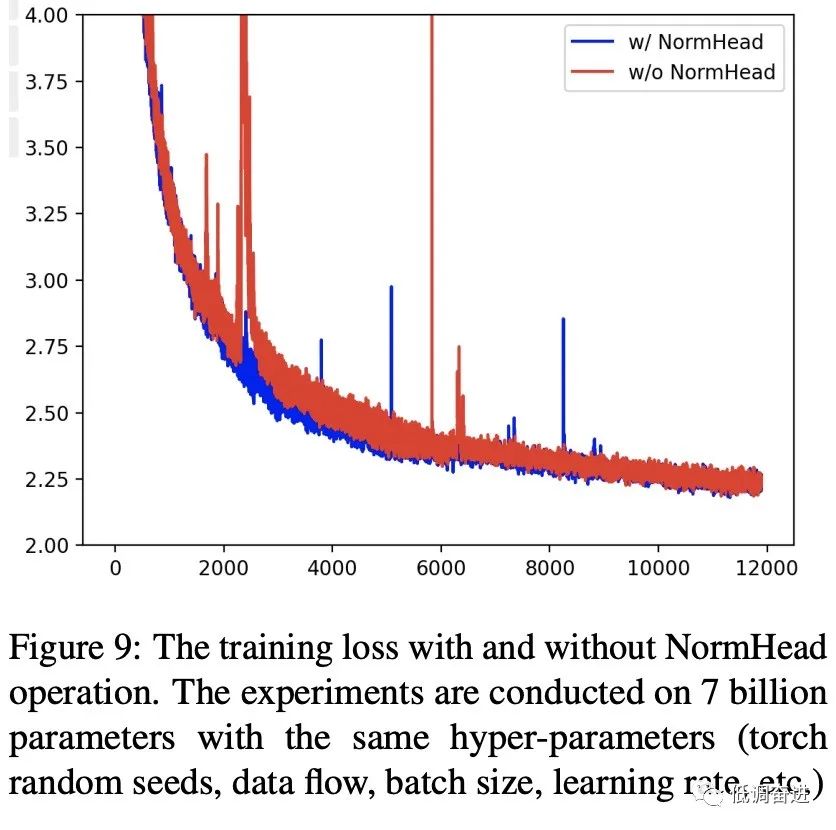
NormHead, Max-z loss
|
|
模型 |
SwiGLU、xFormers、RMSnorm |
|
训练框架 |
Megatron-LM + deepspeed(zero3) |
|
预训练参数 |
BFloat16、AdamW(β1=0.9, β2=0.95,warm_up=2000, lr=2e-4(7b),1.4e-4(13b) |
|
训练硬件 |
1024 *A800 (80G) |
|
对齐SFT数据 |
100k sft (人工标注校验) |
|
Safety工作 |
Pretraining stage, alignment stage |
|
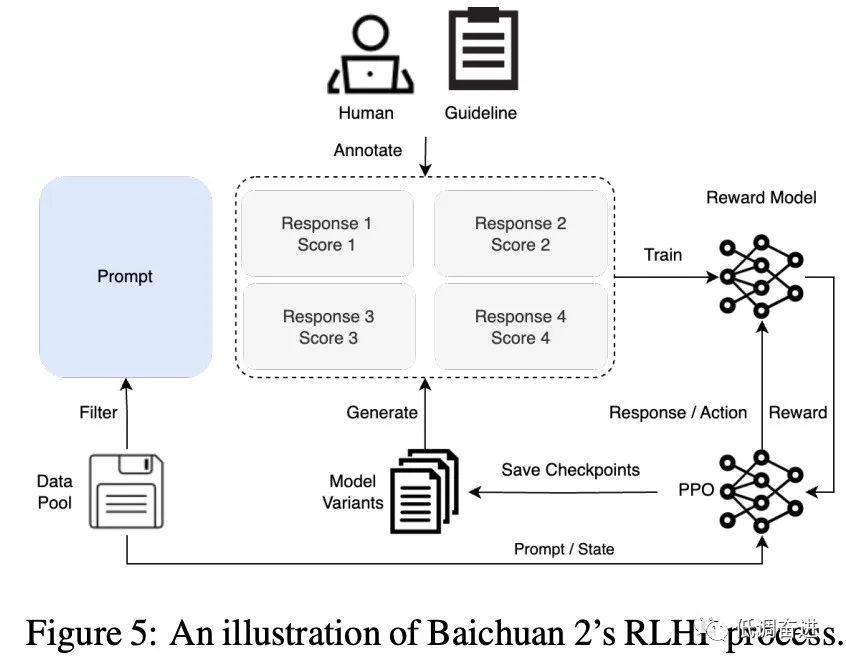
对齐RLHF流程 |
|
|
实验一:NormHead |
|
|
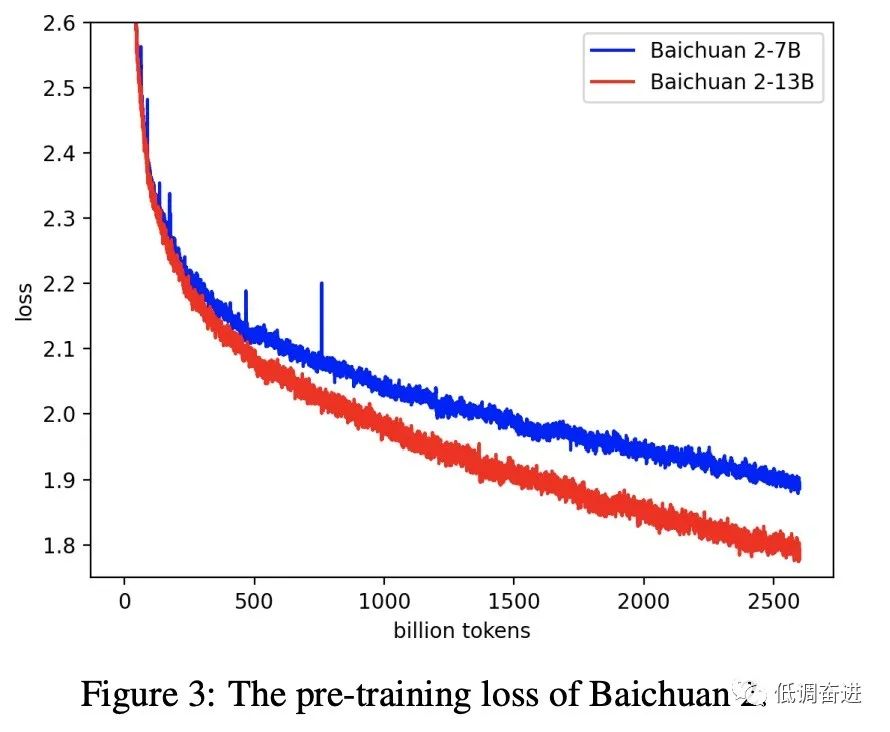
实验二:7b, 13b预训练 loss |
|
|
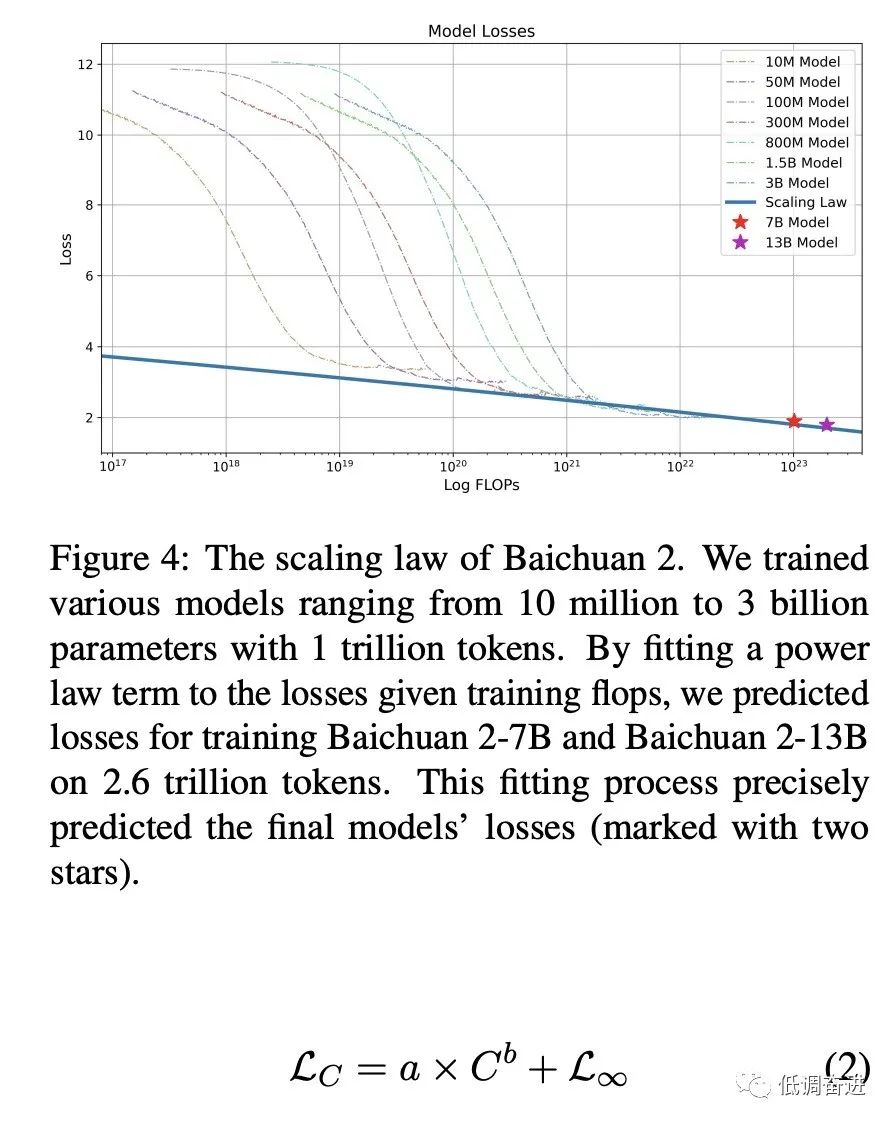
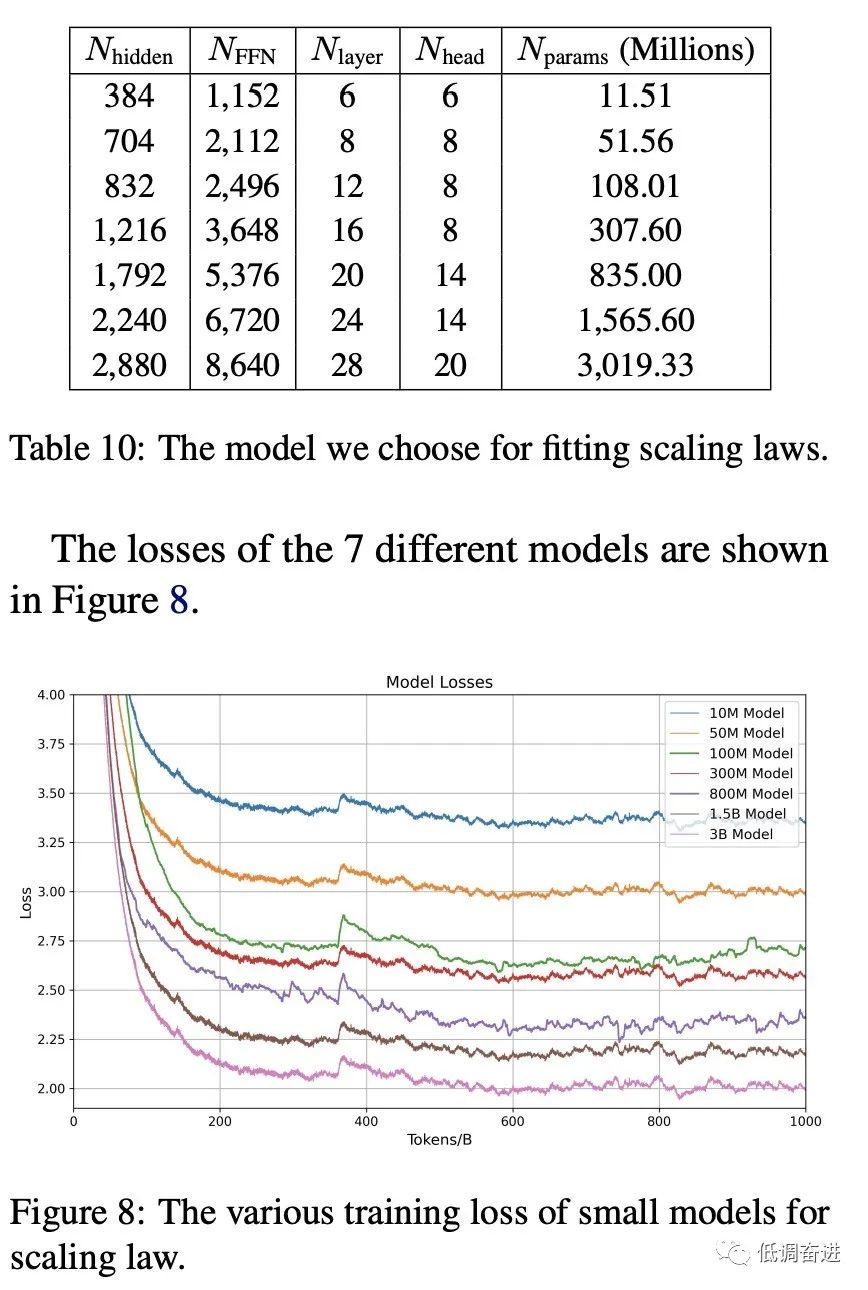
实验三:Scaling Laws |
|
|
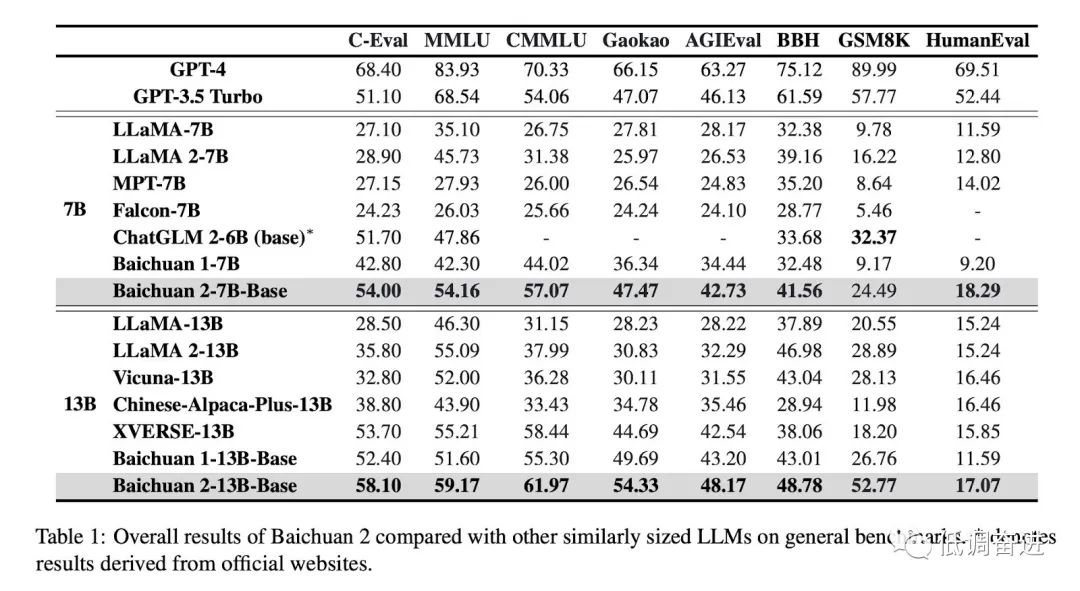
实验四:同尺寸预训练模型对比 |
|
|
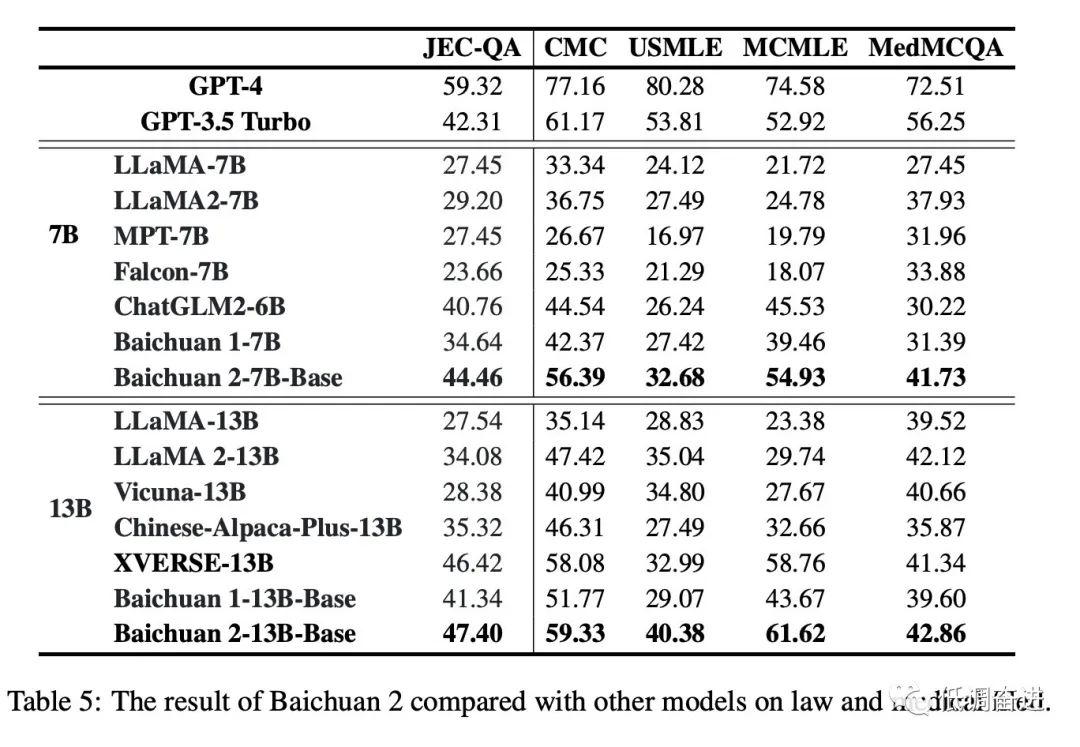
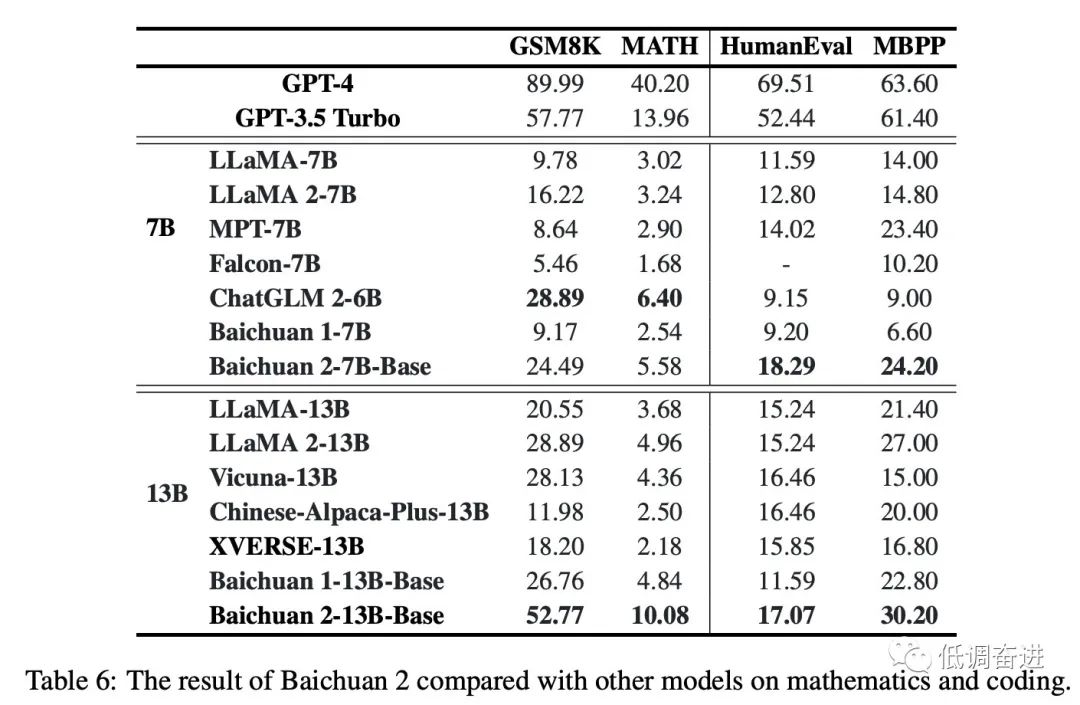
实验五:同尺寸预训练模型垂直领域对比 |
|
|
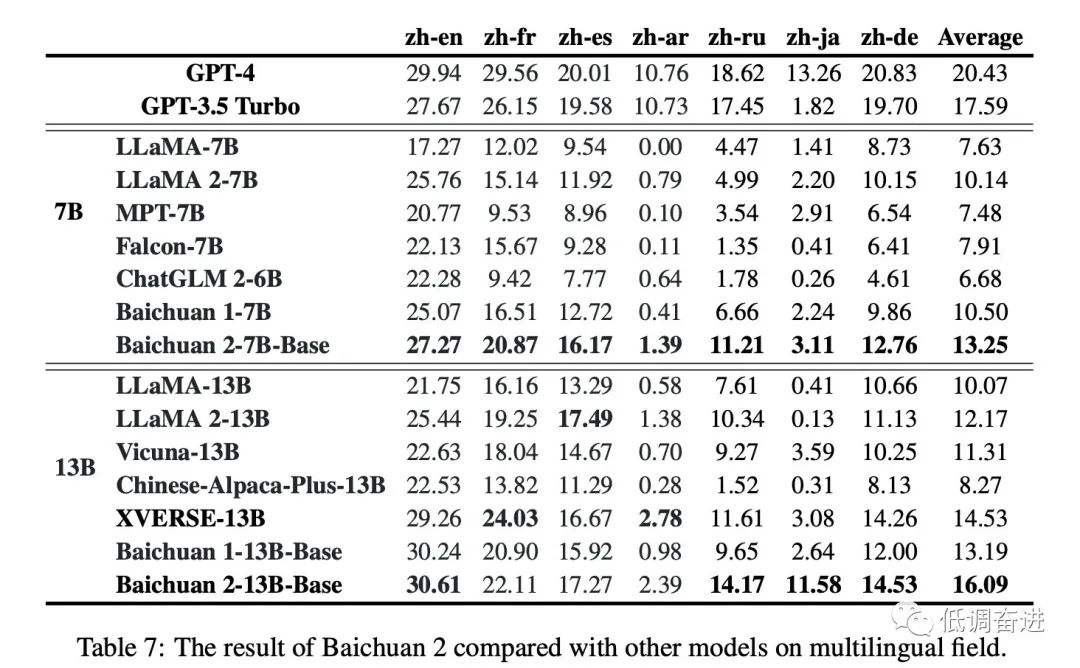
实验六:预训练多语种 |
|
|
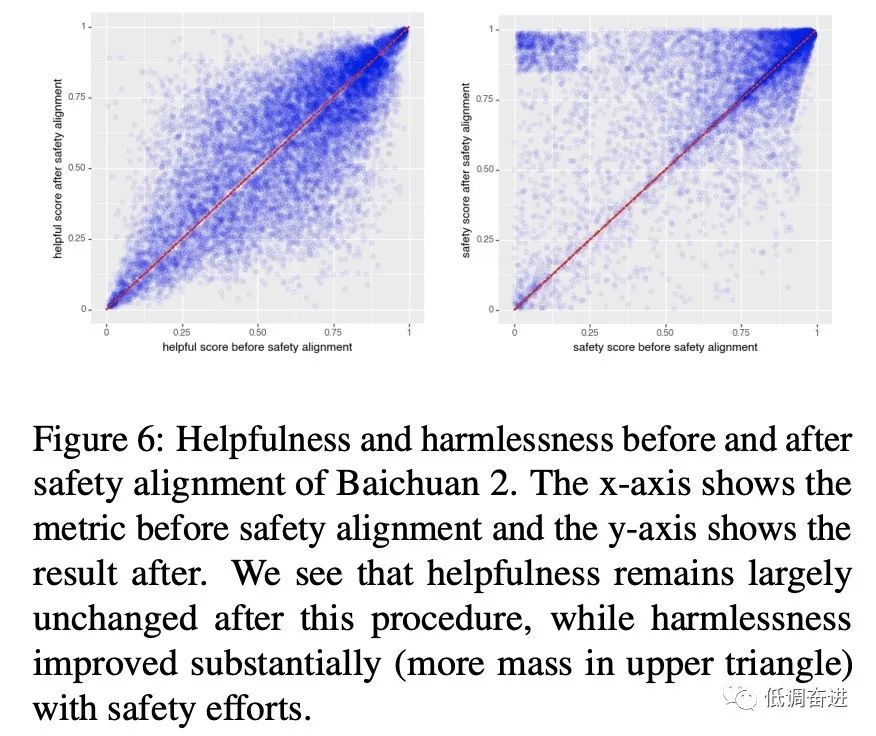
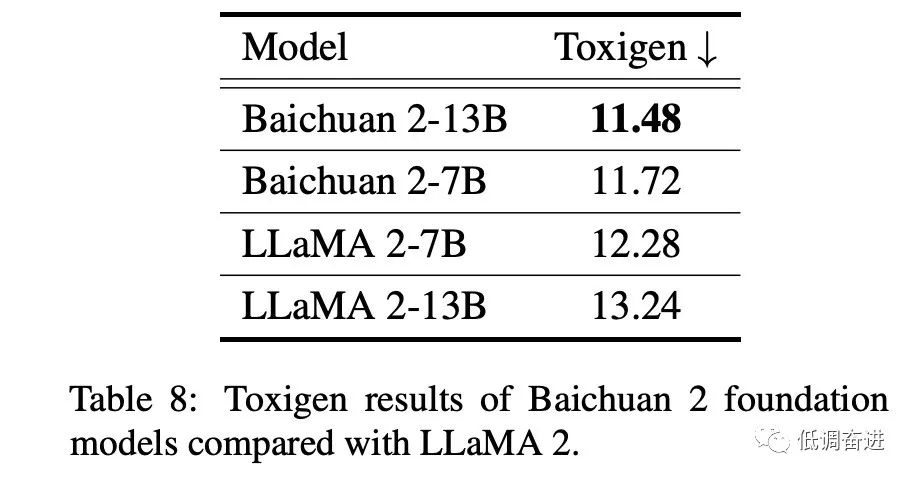
实验七:Safety 评估 |
|
|
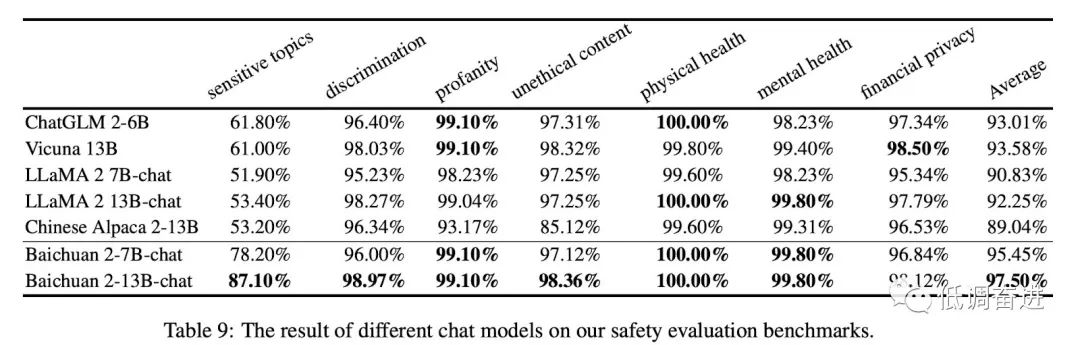
实验八:chat模型safety评估 |
|
|
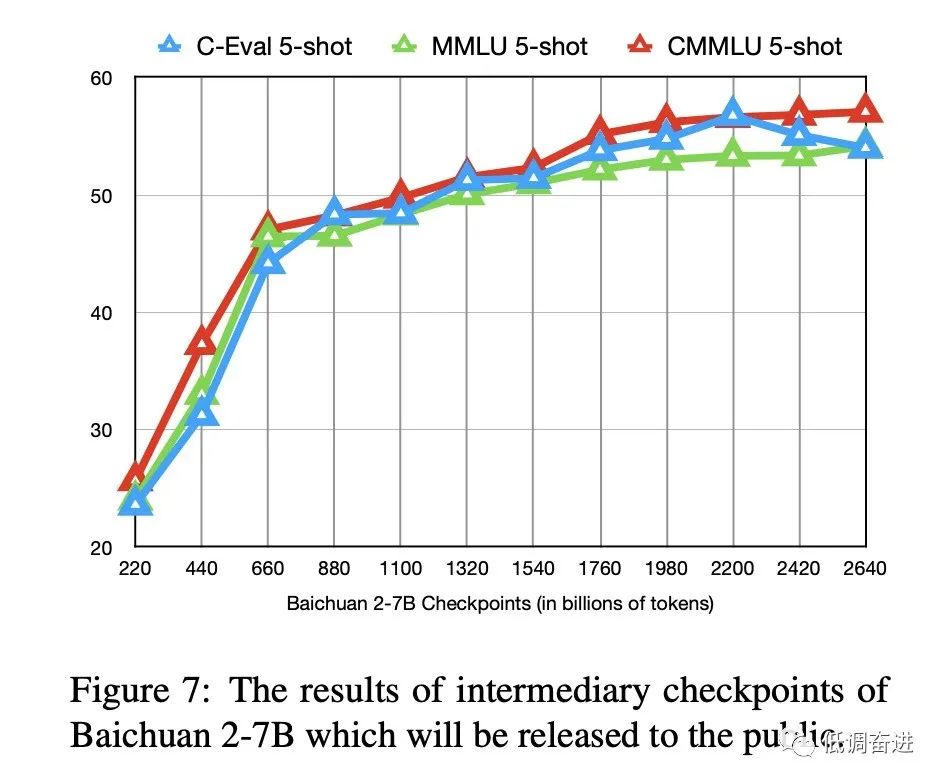
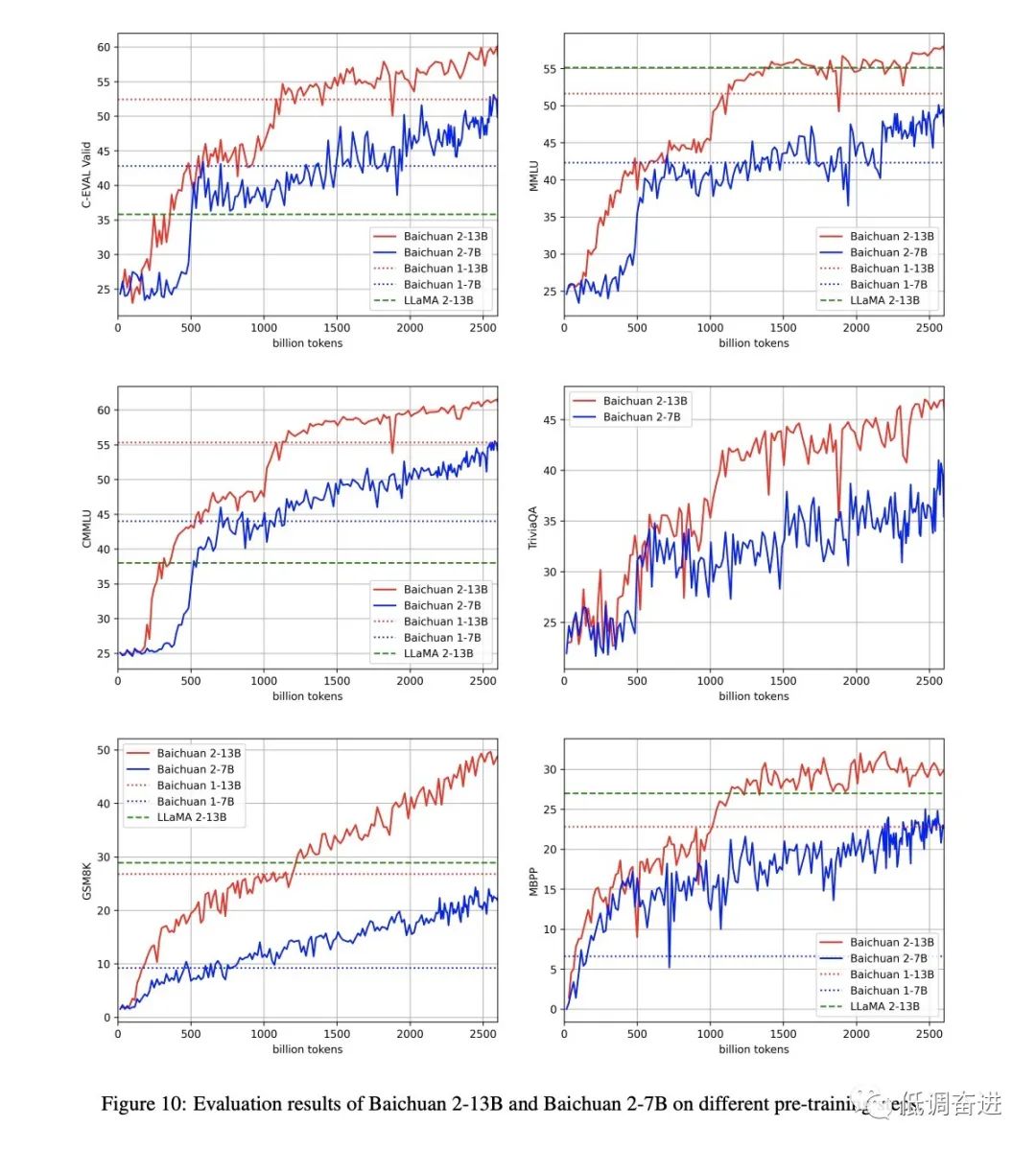
实验九:训练过程评估 |
|
|
训练风向标 |
|

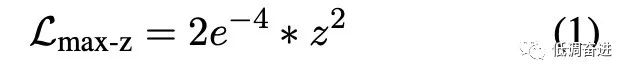


















 354
354




 到【灌水乐园】发言
到【灌水乐园】发言









