




 本文主要探讨了LPCNet声码器在语音合成中的应用,包括通过线性预测改进神经语音合成,提高音质的策略,以及效率提升的方法,如多采样和多频带技术。作者强调了对DSP技术的深入理解对于优化声码器的重要性,并提到了相关研究论文。
本文主要探讨了LPCNet声码器在语音合成中的应用,包括通过线性预测改进神经语音合成,提高音质的策略,以及效率提升的方法,如多采样和多频带技术。作者强调了对DSP技术的深入理解对于优化声码器的重要性,并提到了相关研究论文。
声明:工作以来主要从事TTS工作,工程算法都有涉及,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 低调奋进 TTS 开源数据 低调奋进。如转载,请标明出处。欢迎关注微信公众号:低调奋进
目录
2.3 效率的提升策略之多采样(multi-sampling)
1 背景
TTS的工作主要是把文本信息转成音频信息,其大致流程分为前端处理和后端处理两个部分。前端的工作主要是语言领域的处理,主要包括分句、文本正则、分词、韵律预测、拼音预测(g2p),多音字等等。后端的主要工作是把前端预测的语言特征转成音频的时域波形,大体包括声学模型和声码器,其中声学模型是把语言特征转成音频的声学特征,声码器的主要功能是把声学特征转成可播放的语音波形。声码器的好坏直接决定了音频的音质高低,尤其是近几年来基于神经网络声码器的出现,使语音合成的质量提高一个档次。目前,声码器大致可以分为基于相位重构的声码器和基于神经网络的声码器。基于相位重构的声码器主要因为TTS使用的声学特征(mel特征等等)已经损失相位特征,因此使用算法来推算相位特征,并重构语音波形。基于神经网络的声码器则是直接把声学特征和语音波形做mapping,因此合成的音质更高。目前,比较流行的神经网络声码器主要包括wavenet、wavernn、melgan、waveglow、fastspeech和lpcnet等等。其中,lpcent兼具复杂度低,合成音质高等优点,因此受到学术界和工业界的关注。本文主要关注lpcnet声码器的发展动向,对具有代表性的几篇文章进行总结。(本文稍长,还请读者耐心阅读,如有错误,还望指出)
2 研究情况
到目前为止,研究lpcnet的文章很多,主要研究两个维度:提高音质和降低复杂度。其采用的策略大致包括LP-MDN,gmm采样,multi-sampling多采样,multiband等等(其中lpcnet系统自带的稀疏化等策略,我们不再关注讲解)。本文根据采取的优化策略选取以下6篇具有代表性的文章:
1)LPCNet: Improving Neural Speech Synthesis Through Linear Prediction
2)Improving LPCNet-based Text-to-Speech with Linear Prediction-structured Mixture Density Network
3)Gaussian Lpcnet for Multisample Speech Synthesis
4)Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
5)FeatherWave: An efficient high-fidelity neural vocoder with multi-band linear prediction
6) An Efficient Subband Linear Prediction for LPCNet-based Neural Synthesis
接下来的主要组织结构:2.1小节回顾原始的Lpcnet系统,主要文章1;2.2小节为音质的提高策略,主要包括文章2(这个不能严格说那些策略只提升性能或者质量,后边加速策略multiband不仅可以提高性能,音质也提高不少);2.3 效率的提升策略之多采样(multi-sampling),主要文章3和文章4;2.4 效率的提升策略之多频带(multiband),主要文章5和文章6。
2.1 Lpcnet
LPCNet: Improving Neural Speech Synthesis Through Linear Prediction,该文章主要提出了神经网络声码器Lpcnet。该声码器把source-filter部分的source使用神经网络来预测,而filter部分则使用DSP的方法进行计算,具体如下的公式。其中每个采样点x是由filter部分的p和激励e来计算,而激励e使用神经网络来预测,p则直接根据DSP方法计算出来。
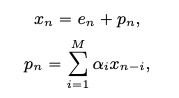
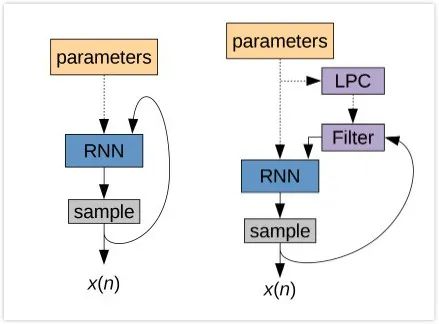
lpcnet声码器其原理和wavernn的区别如下图所示:左边为wavernn的示意图,该网络直接对采样点进行预测,整个流程为自回归模型。右边为lpcnet的示意图,其神经网络只对source的激励e进行预测,而filter的部分直接进行计算获取。该文章的作者回答这样的做的原因,是他认为使用一个神经网络不能同时很好的推算source和filter的两部分信息。
接下来看一下Lpcnet的详细系统架构,如下图所示。整个系统由帧级别的frame rate network(黄色部分)和采样点级别的sampling rate network(浅蓝色部分)。frame rate network每一帧计算一次,其中使用了2层1*3的一维卷积,因此该网络的感受视野为5帧。sampling rate network是每一帧计算160次(如使用16khz的音频,10ms帧移),该部分为autoregressive模型,每一个激励e的推测都需要前一个推测e作为条件。

接下来看一下声码器lpcnet的实验结果。首先,通过计算lpcnet的复杂度为2.8GFLOPS,而其它典型的声码器wavenet为16GFLOPS,wavernn为10GFLOPS,SampleRNN为50GFLOPS,由此可以看出lpcnet的复杂度非常低。另外,合成音质方面如下图所示,ref线为原始音频,绿色线为u-law转换,该转换造成部分音质降低,红色线为lpcnet,蓝色线为wavernn。由图可知lpcnet在相同的复杂度情况下,合成的音质是优于wavernn。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











