




DDP全称是DistributedDataParallel, 在torch.nn.parallel里面。
今天总结一下用DDP进行多GPU并行训练的方法,
内容来自build gpt2加上自己的补充。
本文有些长,需要耐心阅读,希望整理的这些对大家有所帮助。
如果你有多块GPU,就可以充分利用它们。
DDP会创建多个process(进程,不是线程哦), 每个process分配一个GPU,这些process同时运行,于是就达到了多个GPU同时训练的目的。
之前写的训练代码你就可以想象它们同时在被多个process同时运行,
但每个process处理的是不同部分的数据(数据当然要不同了,不然不成了重复训练了嘛)。
这时候你还需要注意一个问题就是梯度的计算,比如现在有8个GPU,它们同时计算了不同部分数据的梯度,
而你的训练目标是不是所有数据汇总的梯度,你就需要把8个GPU计算的梯度加起来求平均。
DDP变量
那么你该如何区分哪个机器上的哪个进程呢,有下面几个变量帮你区分:
WORLD_SIZE: 总进程数
LOCAL_RANK: 当前进程在本机器上的局部排名,从0开始计数
RANK: 当前进程在所有进程中的全局排名,从0到 WORLD_SIZE-1
举个例子:
在2台机器上运行4个进程时:
机器1:
- 进程0: RANK=0, LOCAL_RANK=0
- 进程1: RANK=1, LOCAL_RANK=1
机器2:
- 进程2: RANK=2, LOCAL_RANK=0
- 进程3: RANK=3, LOCAL_RANK=1
所有进程的 WORLD_SIZE=4
如果只有一个机器,那local_rank和rank的值是相同的。
启动train.py
可以手动设置分布式环境
import torch.distributed as dist
# 手动设置环境变量
os.environ['RANK'] = '0'
os.environ['WORLD_SIZE'] = '4'
os.environ['LOCAL_RANK'] = '0'
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
# 初始化进程组
dist.init_process_group(backend='nccl')
更方便的是用torchrun命令,它可以自动做如下事情:
- 自动设置环境变量(RANK, LOCAL_RANK, WORLD_SIZE等)
- 为每个GPU创建一个进程
- 设置进程组通信,初始化分布式环境
- 在每个进程中运行train.py
# 单机4卡
torchrun --standalone --nproc_per_node=4 train.py
torchrun --nproc_per_node=4 train.py #单机训练,--standalone参数会被自动设置为默认值
# 多机训练
torchrun --nproc_per_node=4 --nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=29500 train.py
torchrun会根据GPU序号设置RANK。例如在单机4卡时:
GPU 0: RANK=0
GPU 1: RANK=1
GPU 2: RANK=2
GPU 3: RANK=3
在多机时,RANK会跨机器累加。例如2机4卡:
机器1: RANK=0,1,2,3
机器2: RANK=4,5,6,7
那你说,我的train.py有时会用单个GPU,有时会用多个,我想让它具有通用性,不需要每次都修改代码。
可以下面这样做,后面都说的是单个机器的情况。
GPU之间的通信一般用’nccl’,
NCCL (NVIDIA Collective Communications Library) 是NVIDIA开发的GPU通信库,专门优化了GPU之间的通信效率。在PyTorch分布式训练中,它是GPU训练的默认后端选项。
初始化阶段
from torch.distributed import init_process_group
#如果用torchrun启动,RANK的值在0~WORLD_SIZE-1,WORLD_SIZE为进程数,即GPU总数
ddp = int(os.environ.get('RANK', -1)) != -1
if ddp:
assert torch.cuda.is_available() #DDP中CUDA是必须的
init_process_group(backend='nccl')
ddp_rank = int(os.environ['RANK'])
ddp_local_rank = int(os.environ['LOCAL_RANK'])
ddp_world_size = int(os.environ['WORLD_SIZE'])
device = f'cuda:{ddp_local_rank}'
torch.cuda.set_device(device)
master_process = ddp_rank==0 #防止log重复输出,指定master process输出
else:
ddp_rank = 0
ddp_local_rank = 0
ddp_world_size = 1
master_process = True
device = 'cpu'
if torch.cuda.is_available():
device = 'cuda'
elif hasattr(torch.backends, "mps") and torch.backends.mps.is_available():
device = 'mps' #较新的MAC用
print(f'using device: {device}')
在代码里面加上这么一句话,就可以看到代码正在被哪个GPU执行:
print("I am GPU: ", ddp_rank)
打印出来的是随机顺序,并不能保证先后,且它们是并行发生的。
batch size超过GPU内存的情况
比如gpt2, paper中的batch size为0.5M个token, 一般取2的N次方会利于GPU加速计算,
所以令total_batch_size=219=524288, 这么大的batch size一般GPU很难容纳,如何在有限的GPU内存上实现如此大的batch size?
可以每次处理小批量的batch, 分多次处理。
比如gpt的sequence length设为T=128,batch size B=32, 这是一次处理的batch量(设为你的GPU能承受的batch size),
总共要处理grad_accum_steps=total_batch_size // (B * T)次。
这是在分解任务,总共batch, 可是我的GPU容纳不下,于是分批处理,最后再合起来。
total_batch_size = 524288
B = 32 #小的batch size(GPU能承受的)
T = 128
assert total_batch_size % (B*T) == 0
grad_accum_steps = total_batch_size // (B*T) #一共需要累加多少轮
print(f"total desired batch size: {total_batch_size}")
print(f"=> calculated grad accumulation steps: {grad_accum_steps}")
于是到了训练的时候,我们要在step里面再分解为micro_step,
我们的目的是最后把每个iteration里面的所有micro_steps的梯度累加起来,才算一个大batch的梯度,累加完了之后再更新optimizer, 梯度归0。
用到了这个特性:
如果你不用optimizer.zero_grad(),梯度梯度是累加的,所以每个iteration开始时用一次, micro_step里面(小batch结束时)不用。optimizer.step()是用梯度来更新变量,所以也是每个iteration结束时用一次,micro_step里面不用。
不过loss不会自动累加,你需要设一个变量用来累加loss.
在累加loss的时候,你要注意一个问题,
举例来说明,假如现在batch size=B, 每个micro_step中的batch size=b. 一共累加B//b=N次。
一般loss里面会对这个batch里面的loss求平均,会有mean的运算。
那么每一个micro_step里面的loss就是1/b * 小batch的loss和,
最后我们把所有micro_step的loss累加起来之后loss就是1/b * 大batch的loss.
发现问题了吗,本来大batch的loss应该是1/B * 大batch的loss, 现在变成了1/b, 这个求平均的基数不对。
所以在所有micro_steps的loss累加时,要另外再除grad_accum_steps.
for step in range(max_steps):
t0 = time.time()
optimizer.zero_grad()
loss_accum = 0.0 #用于print loss
#在这些步里面累加梯度(用loss.backward的累加梯度效果),模拟一个0.5M的batch size的效果
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x = x.to(device)
y = y.to(device)
#一般的loss里面会用mean来求这个batch里面loss的平均,所以每个batch会除以batch_size
#那么大batch的loss加起来,也只相当于除以了小batch的batch_size,并不是大batch_size
#所以在累加的loss基础上还要除以(大batch_size / 小batch_size), 也就是grad_accum_steps
loss /= grad_accum_steps
loss_accum += loss.detach() #detach():变成叶子节点,梯度累加,loss可没有累加,累加loss要自己算
loss.backward() # 更新梯度,会累积,所以每次optimizer要设置zero_grad,它不会自动清零
#把梯度的norm限制在1,什么是norm,就是一个向量的L2 norm
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) #根据gpt3 paper
optimizer.step() #更新参数
现在用了DDP,就有多个GPU一起来处理这个batch, 每个GPU处理的grad_accum_steps变为:
grad_accum_steps=total_batch_size // (B * T * ddp_world_size)
划分不同数据区域
这部分讨论如何让每个process访问不同的数据部分,也就是说每个GPU处理不同的数据。
所以我们需要把数据划分,让不同的GPU访问不同的部分。
如何识别不同的GPU,这就用到了前面的RANK.
你就需要把ddp_rank和ddp_world_size传给dataloader.
class DataLoaderLite:
def __init__(self, B, T, process_rank, num_processes):
self.B = B
self.T = T
self.process_rank = process_rank #ddp_rank
self.num_processes = num_processes #ddp_world_size
with open('./data/input.txt','r') as f:
text = f.read()
enc = tiktoken.get_encoding('gpt2')
tokens = enc.encode(text)
self.tokens = torch.tensor(tokens)
print(f"loaded {len(self.tokens)} tokens")
print(f"1 epoch = {len(self.tokens) // (B*T)} batches")
#每个GPU读不同的数据
self.current_position = self.B * self.T * self.process_rank
def next_batch(self):
B, T = self.B, self.T
buf = self.tokens[self.current_position:self.current_position+B*T+1]
x = buf[:-1].view(B,T)
y = buf[1:].view(B,T)
self.current_position += B*T * self.num_processes #每个GPU处理的数据,有点类似CNN中的batch
#数据应该不会小到一个循环之内self.B * self.T * self.process_rank的时候就超出边界了
if self.current_position + (B*T*self.num_processes+1) >= len(self.tokens):
self.current_position = B * T * self.process_rank
return x, y
train_loader = DataLoaderLite(B=B, T=T, process_rank=ddp_rank, num_processes=ddp_world_size)
如何处理model
由于一个代码被N个GPU同时执行,这里假设有8个GPU并行。
那么model就会被创建8次,要保证这8个model是一致的,就需要固定seed.
还需要把model装进DDP container.
这个可以参考DistributedDataParallel官方文档,device_ids这个参数指的是ddp_local_rank, 而不是ddp_rank.
DDP 这样包装 model 的主要原因是为了实现高效的分布式训练,
device_ids=[ddp_local_rank] 的作用:
将模型绑定到指定的 GPU 上
ddp_local_rank 通常是 0,1,2,3… 这样的局部 GPU 编号
确保每个进程只使用分配给它的那个 GPU
DDP 包装后会实现:
自动梯度同步:不同 GPU 上的梯度会自动进行平均
参数广播:确保所有 GPU 上的模型参数保持一致
通信优化:使用高效的 ring-allreduce 算法进行梯度同步
包装了之后model就变成了DDP model.
而需要调用model里面的method时,需要的是raw model.
#这里model会被创建GPU个数次,比如8个GPU,就会创建8个model, torch.compile也会发生8次
#固定seed, 让每个model计算一致
torch.manual_seed(1337)
if torch.cuda.is_avaliable():
torch.cuda.manual_seed(1337)
model = GPT(GPTConfig(vocab_size=50534))
model.to(device)
model = torch.compile(model)
if ddp:
model = DDP(model, device_ids=[ddp_local_rank])
raw_model = model.module if ddp else model
#当需要调用model里面的method时,要用raw_model
optimizer = raw_model.configure_optimizers(weight_decay=0.1, ...)
同步梯度计算
forward过程每个GPU都是一样的,
backward涉及到每个GPU都在计算梯度,所以在backward结束的时候,会计算所有GPU计算的梯度的平均,
同步这个平均梯度到每个GPU上。其实是调用了all_reduce
实际上并不是结束的时候才这样做,而是在backward正在进行的时候就在同步做这些事情。
在loss.backward()时,就会发生通信,并同步梯度信息到各GPU。
前面提到了batch size过大时,会分解成每次处理小的batch.
可以看到每个小batch计算时都有loss.backward(), 导致多次通信,同步梯度,影响效率,
我们现在不想这么做,想让一轮batch计算结束时再同步。
for step in range(max_steps):
t0 = time.time()
optimizer.zero_grad()
loss_accum = 0.0
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x = x.to(device)
y = y.to(device)
loss /= grad_accum_steps
loss_accum += loss.detach()
loss.backward()
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step() #更新参数
一般是用no_sync(), 看上去比较复杂

而当你看了no_sync()的源码,你会发现起作用的是一个flag
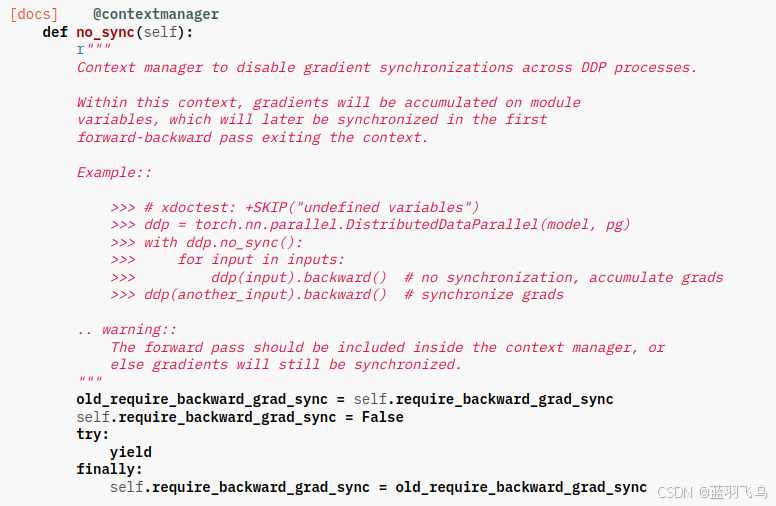
所以直接用这个flag, 会比较简洁,风险就是将来版本升级了这个flag可能就不存在了-_-
需要在loss.backward()前面设置是否需要通信同步梯度。
另外,梯度已经求了所有GPU的平均并同步,但是loss并没有求各GPU的平均,
每个GPU只能看见它自己的loss.
这时需要调用all_reduce, 前面提到了同步梯度时也是all_reduce.
在完成了一整个大batch的计算后(从for loop出来),调用all_reduce.
all_reduce做的事情是对每个GPU上的loss_accum, 计算所有GPU(rank)上的平均值,然后同步到每个GPU。
当你print(loss_accum)时,所有GPU上的数值应该是一致的。
import torch.distributed as dist
for step in range(max_steps):
t0 = time.time()
optimizer.zero_grad()
loss_accum = 0.0
for micro_step in range(grad_accum_steps):
x, y = train_loader.next_batch()
x = x.to(device)
y = y.to(device)
loss /= grad_accum_steps
loss_accum += loss.detach()
if ddp:
#到最后一轮时才需要同步梯度
model.require_backward_grad_sync = (micro_step == grad_accum_steps-1)
loss.backward()
#从for loop中出来后所有GPU里面的梯度都同步了
if ddp:
dist.all_reduce(loss_accum, op=dist.ReduceOp.AVG) #average
norm = torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
输出log
应该意识到现在每个GPU都在运行这个代码,所以你会输出重复的log,
设置一个master, 只输出一个log,
master可以在前面初始化的时候设置
结束时要调用destroy_process_group
#master_process = ddp_rank==0 #前面初始化的部分已经设置
for step in range(max_steps):
...
token_processed = train_loader.B * train_loader.T * grad_accum_steps * ddp_world_size
token_per_sec = token_processed / dt
if master_process:
print(f"step {step:4d} | loss: {loss.item():.6f} | norm: {norm:.4f} | dt: {dt*1000:.2f}ms, token_per_sec: {token_per_sec:.2f}ms")
if ddp:
destroy_process_group()
你会发现多GPU并行时的loss可能会和单GPU不同,这是因为data_loader中读取数据的方式不一样,
以前是一个一个的batch, 超出边界了就从0开始,现在把N个GPU一次读的数据看成一个page, page超过边界时重置,这个地方会导致batch数据可能会出现不同。
如果想让loss相同,需要调节total batch size, 让单个GPU重置的边界和多个GPU相同。
拓展一下,如果数据很大,存储在不同的地方,也可通过DDP实现训练,设置不同rank的GPU读取不同地方的数据。
不过要注意以下几点:
确保数据分片大小相近,避免负载不均衡
根据实际存储位置和网络带宽调整数据分配策略
可能需要处理数据分片边界的问题



















 1741
1741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











