





0x0. 前言
本文主要是对FastLLM做了一个简要介绍,展示了一下FastLLM的部署效果。然后以chatglm-6b为例,对FastLLM模型导出的流程进行了解析,接着解析了chatglm-6b模型部分的核心实现。最后还对FastLLM涉及到的优化技巧进行了简单的介绍。
0x1. 效果展示
按照 https://github.com/ztxz16/fastllm 中 README教程 编译fastllm之后,再按照教程导出一个 chatglm6b 模型参数文件(按照教程默认叫chatglm-6b-fp16.flm)。然后在编译时创建的 build 目录中执行./webui -p chatglm-6b-fp16.flm --port 1234 即可启动一个由FastLLM驱动的webui程序,效果如下:
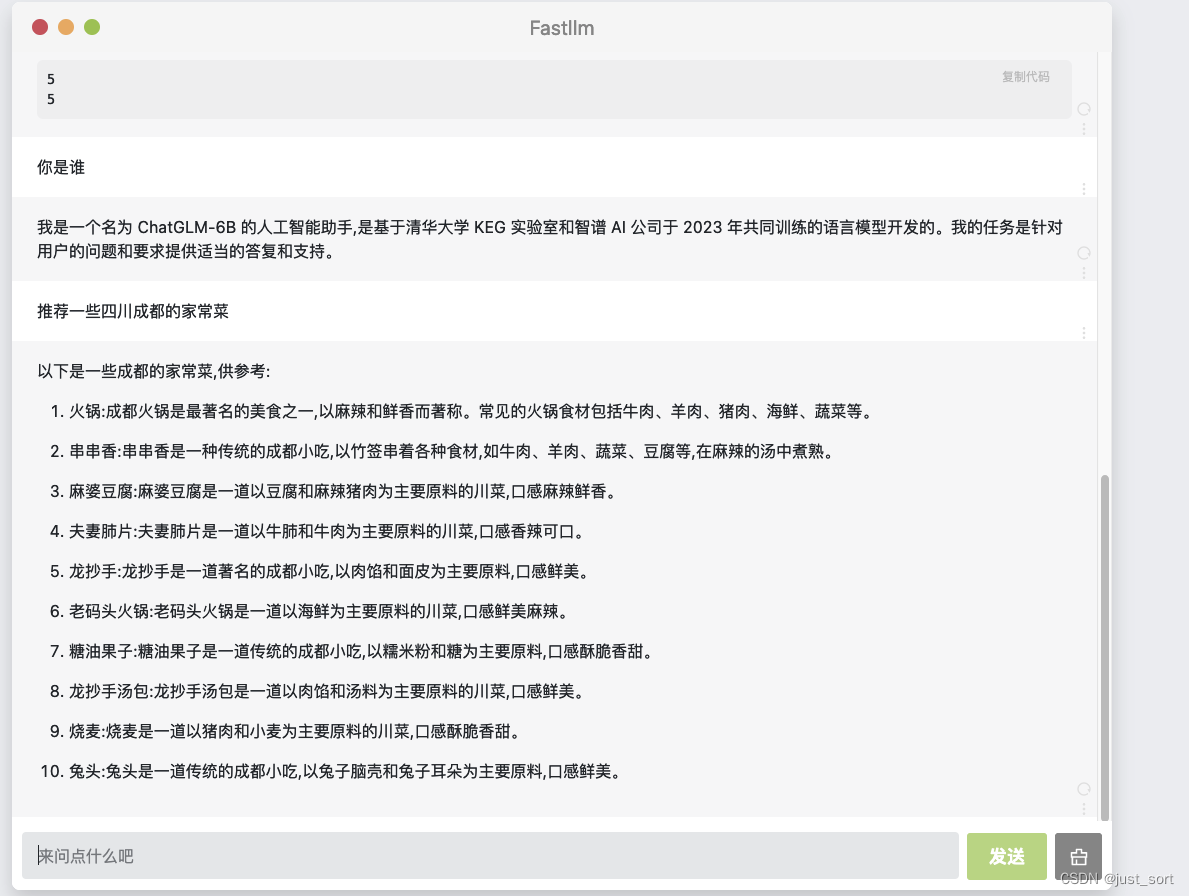
除了c++调用以外,FastLLM也基于PyBind导出了Python接口,支持简易python调用。并且FastLLM不仅支持Windows/Linux,还支持通过NDK将其编译到Android手机上进行使用。
另外在对话时,FastLLM支持了流式对话的效果,体验更好。并且FastLLM对批量推理进行了支持,也就是说如果有多个用户的请求进来,不管是否它们请求的长度是否相同都可以在FastLLM中组成一个batch来批量推理节约资源。
0x2. FastLLM chatglm-6b模型导出解析
首先解读一下FastLLM是如何导出huggingface的chatglm-6b模型的。
首先来看 fastllm/tools/fastllm_pytools/torch2flm.py 这个文件,这个文件实现了一个tofile函数用于将一个训练好的模型导出到一个文件中。具体来说,它包括以下几个步骤:
- 打开一个二进制文件,准备写入模型的数据。
- 写入一个版本号,用于后续的兼容性检查。
- 获取模型的配置信息,并将它们写入文件。如果提供了一些额外的配置参数,如 pre_prompt,user_role,bot_role,history_sep,也将它们添加到配置信息中。
- 如果提供了分词器(tokenizer),将分词器的词汇表写入文件。如果分词器是一个句子片段模型(sentence piece model),那么还会写入一些额外的信息。
- 获取模型的权重(包含在模型的状态字典中),并将它们写入文件。权重的名字和形状都会被写入文件,以便于后续正确地加载模型。
- 在每写入一个权重后,打印进度信息,以便于用户知道当前的进度。
- 最后,关闭文件。
更详细的解释可以请看:
# struct 是Python的一个内置模块,提供了一些函数来解析打包的二进制数据。
# 在这个代码中,它被用于将整数和字符串转换为二进制格式。
import struct
import numpy as np
# 定义一个函数 writeString,它接受两个参数:一个文件对象 fo 和一个字符串 s。
def writeString(fo, s):
# struct.pack 函数将 len(s)(字符串 s 的长度)打包为一个二进制字符串,
# 然后 fo.write 将这个二进制字符串写入文件。
fo.write(struct.pack('i', len(s)));
# s.encode() 将字符串 s 转换为二进制格式,然后 fo.write 将这个二进制字符串写入文件。
fo.write(s.encode());
# 定义一个函数 writeKeyValue,它接受三个参数:一个文件对象 fo,一个键 key 和一个值 value。
def writeKeyValue(fo, key, value):
writeString(fo, key);
writeString(fo, value);
# 这段Python代码的主要作用是将模型的状态字典(state_dict)以及一些模型的配置信息保存到一个文件中。
# 定义了一个函数 tofile,它接受七个参数:一个文件路径 exportPath,一个模型对象 model,
# 和五个可选参数 tokenizer,pre_prompt,user_role,bot_role,history_sep。
def tofile(exportPath,
model,
tokenizer = None,
pre_prompt = None,
user_role = None,
bot_role = None,
history_sep = None):
# 获取模型的状态字典。状态字典是一个Python字典,它保存了模型的所有权重和偏置。
dict = model.state_dict();
# 打开一个文件以写入二进制数据。
fo = open(exportPath, "wb");
# 0. version id
# 写入一个版本号 2。
fo.write(struct.pack('i', 2));
# 0.1 model info
modelInfo = model.config.__dict__ # 获取模型配置的字典。
if ("model_type" not in modelInfo):
print("unknown model_type.");
exit(0);
# 如果提供了 pre_prompt,user_role,bot_role,history_sep,则将它们添加到 modelInfo 中。
if (pre_prompt):
modelInfo["pre_prompt"] = pre_prompt;
if (user_role):
modelInfo["user_role"] = user_role;
if (bot_role):
modelInfo["bot_role"] = bot_role;
if (history_sep):
modelInfo["history_sep"] = history_sep;
# 如果模型是 "baichuan" 类型,并且模型有 "get_alibi_mask" 属性,
# 则将一些额外的信息添加到 modelInfo 中。
if (modelInfo["model_type"] == "baichuan" and hasattr(model, "model") and hasattr(model.model, "get_alibi_mask")):
# Baichuan 2代
modelInfo["use_alibi"] = "1";
modelInfo["pre_prompt"] = "";
modelInfo["user_role"] = tokenizer.decode([model.generation_config.user_token_id]);
modelInfo["bot_role"] = tokenizer.decode([model.generation_config.assistant_token_id]);
modelInfo["history_sep"] = "";
# 写入 modelInfo 的长度。
fo.write(struct.pack('i', len(modelInfo)));
# 遍历 modelInfo 的每一个键值对,并使用 writeKeyValue 函数将它们写入文件。
for it in modelInfo.keys():
writeKeyValue(fo, str(it), str(modelInfo[it]));
# 1. vocab
# 判断是否提供了分词器 tokenizer。分词器是一个将文本分解为词或其他有意义的符号的工具。
if (tokenizer):
# 如果分词器有 "sp_model" 属性,这意味着分词器是
# 一个句子片段模型(sentence piece model),这是一种特殊的分词方法。
if (hasattr(tokenizer, "sp_model")):
# 获取句子片段模型的大小(即词汇表的大小)。
piece_size = tokenizer.sp_model.piece_size();
fo.write(struct.pack('i', piece_size));
# for i in range(piece_size): 遍历词汇表中的每一个词。
for i in range(piece_size):
# s = tokenizer.sp_model.id_to_piece(i).encode();
# 将词的ID转换为词本身,并将其编码为二进制字符串。
s = tokenizer.sp_model.id_to_piece(i).encode();
# 写入词的长度。
fo.write(struct.pack('i', len(s)));
# 遍历词的每一个字符,并将其写入文件。
for c in s:
fo.write(struct.pack('i', c));
# 写入词的ID。
fo.write(struct.pack('i', i));
else:
# 如果分词器没有 "sp_model" 属性,那么它就是一个普通的分词器。
# 在这种情况下,它将获取词汇表,然后遍历词汇表中的每一个词,将词和对应的ID写入文件。
vocab = tokenizer.get_vocab();
fo.write(struct.pack('i', len(vocab)));
for v in vocab.keys():
s = v.encode();
fo.write(struct.pack('i', len(s)));
for c in s:
fo.write(struct.pack('i', c));
fo.write(struct.pack('i', vocab[v]));
else:
# 如果没有提供分词器,那么它将写入一个0,表示词汇表的大小为0。
fo.write(struct.pack('i', 0));
# 2. weight
# 写入模型状态字典的长度,即模型的权重数量。
fo.write(struct.pack('i', len(dict)));
tot = 0;
# 遍历模型状态字典中的每一个键值对。键通常是权重的名字,值是权重的值。
for key in dict:
# 将权重的值转换为NumPy数组,并确保其数据类型为float32。
cur = dict[key].numpy().astype(np.float32);
# 写入权重名字的长度。
fo.write(struct.pack('i', len(key)));
# 将权重名字编码为二进制字符串,然后写入文件。
fo.write(key.encode());
# 写入权重的维度数量。
fo.write(struct.pack('i', len(cur.shape)));
# 遍历权重的每一个维度,将其写入文件。
for i in cur.shape:
fo.write(struct.pack('i', i));
# 写入一个0,可能是为了标记权重值的开始。
fo.write(struct.pack('i', 0));
# 将权重的值写入文件。
fo.write(cur.data);
# 记录已经写入的权重数量。
tot += 1;
# 打印进度信息。
print("output (", tot, "/", len(dict), end = " )\r");
print("\nfinish.");
fo.close(); # 最后,关闭文件。
以ChatGLM为例,在模型导出时执行的命令如下:
# 需要先安装ChatGLM-6B环境
# 如果使用自己finetune的模型需要修改chatglm_export.py文件中创建tokenizer, model的代码
# 如果使用量化模型,需要先编译好quant文件,这里假设已经存在build/quant文件
cd build
python3 tools/chatglm_export.py chatglm-6b-fp32.flm # 导出浮点模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-fp16.flm -b 16 #导出float16模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-int8.flm -b 8 #导出int8模型
./quant -p chatglm-6b-fp32.flm -o chatglm-6b-int4.flm -b 4 #导出int4模型
所以我们接着解读一下chatglm_export.py。
# 这段代码的主要功能是从预训练模型库中加载一个模型和对应的分词器,
# 并将它们导出为一个特定的文件格式(在这个例子中是 .flm 格式)。以下是代码的详细解析:
# 导入Python的sys模块,它提供了一些与Python解释器和环境交互的函数和变量。
# 在这段代码中,它被用于获取命令行参数。
import sys
# 从transformers库中导入AutoTokenizer和AutoModel。transformers库是一个提供大量预训练模型的库,
# AutoTokenizer和AutoModel是用于自动加载这些预训练模型的工具。
from transformers import AutoTokenizer, AutoModel
# 从fastllm_pytools库中导入torch2flm模块。
# 这个模块可能包含了一些将PyTorch模型转换为.flm格式的函数。
from fastllm_pytools import torch2flm
if __name__ == "__main__":
# 从预训练模型库中加载一个分词器。"THUDM/chatglm-6b"是模型的名字。
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
# 从预训练模型库中加载一个模型,并将它转换为浮点类型。
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
# 将模型设置为评估模式。这是一个常见的操作,用于关闭模型的某些特性,
# 如dropout和batch normalization。
model = model.eval()
# 获取命令行参数作为导出文件的路径。如果没有提供命令行参数,
# 那么默认的文件名是"chatglm-6b-fp32.flm"。
exportPath = sys.argv[1] if (sys.argv[1] is not None) else "chatglm-6b-fp32.flm";
# 使用torch2flm的tofile函数将模型和分词器导出为.flm文件。
torch2flm.tofile(exportPath, model, tokenizer)
这里的torch2flm.tofile就是我们上面解析的函数。
0x3. FastLLM chatglm-6b模型支持流程解析
在FastLLM中要支持一个新的模型需要在fastllm/include/models这个目录下进行扩展,我们这里以chatgm6b为例简单解析一下流程。首先我们在fastllm/include/models下定义一个chatglm.h头文件:
//
// Created by huangyuyang on 5/11/23.
//
#ifndef FASTLLM_CHATGLM_H
#define FASTLLM_CHATGLM_H
#include "basellm.h"
#include "cmath"
#include <iostream>
namespace fastllm {
class ChatGLMModel: public basellm {
public:
ChatGLMModel (); // 构造函数
// 推理
virtual int Forward(
const Data &inputIds,
const Data &attentionMask,
const Data &positionIds,
std:: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









