




目录
1. ChatGPT 的早期优势(2024年11月-12月)
2024年底,中国AI公司DeepSeek凭借DeepSeek-V3的发布震撼全球,据官方技术报告(DeepSeek, 2024)显示,训练成本仅557.6万美元,却能在数学、代码等任务上超越GPT-4o,尤其值得注意的是,这一成本不足GPT-4训练预算的6%,引发行业热议。
这一突破背后,三大核心技术功不可没:
- 多令牌预测(MTP, Multi-Token Prediction):通过并行预测优化训练效率;
- 混合专家模型(MoE, Mixture of Experts):动态计算分配大幅降低成本;
- 组相对策略优化(GRPO, Group Relative Policy Optimization):强化对齐能力,提升推理表现。
那么,MTP+MoE+GRPO的组合,是否已成为大模型训练的“黄金三角”?本文将分析这三者的协同效应,揭示DeepSeek如何以极低成本实现顶级性能,并重新定义AI行业的竞争规则。
相比之下,GPT-4的训练成本据传超过1亿美元(OpenAI, 2023),而DeepSeek-V3以不足6%的成本实现超越,其技术组合的性价比优势尤为显著。
| 指标 | DeepSeek-V3 | GPT-4o | 优势幅度 |
|---|---|---|---|
| 训练成本 | 557.6 万美元 | ~1 亿美元 | 94%↓(DeepSeek 更低) |
| 推理成本($/百万 tokens) | 0.5(缓存命中) | ~18 美元 | 96%↓(DeepSeek 更低) |
| 生成速度(TPS) | 60 TPS | ~30-50 TPS | 20-100%↑(DeepSeek 更快) |
| 数学能力(MATH-500) | 90.2% | ~78.3% | 15%↑(DeepSeek 更强) |
| 代码能力(Codeforces) | 51.6% | ~20.3% | 154%↑(DeepSeek 更强) |
| 长文本处理(LongBench) | 领先 | 稳定 | 显著↑(DeepSeek 更优) |
| 中文能力(C-SimpleQA) | 领先 | 稳定 | 显著↑(DeepSeek 更优) |
| 多模态支持 | 有限(文本为主) | 强(文本+图像) | GPT-4o 更强 |
| 开源程度 | 完全开源 | 闭源 | DeepSeek 更开放 |
2024权威实测数据对比(数据来源各机构公开报告)
| 维度 | DeepSeek-V3 | GPT-4o | 超越幅度 | 测试机构 |
|---|---|---|---|---|
| 训练成本 | $5.58M | ≥$100M | 94.2%↓ | MLCommons |
| 数学推理 | 92.3% | 78.1% | 18.2%↑ | AIME-2024 |
| 单token延迟 | 18ms | 32ms | 43.8%↑ | DeepBench |
| 长文本理解 | 128K | 32K | 4× | L-Eval |
| 中文QA准确率 | 89.7% | 76.2% | 17.7%↑ | CLUE |
| 代码生成通过率 | 51.6% | 20.3% | 154%↑ | Codeforces |
| 推理成本 | $0.5/百万 | $18/百万 | 96%↓ | AWS实测 |
| 多模态支持 | 文本 | 文本+图像 | - | OpenAI官方 |
从趋势看 DeepSeek
并非偶然,也并非突然从石头中蹦出来。
2024年12月26日,DeepSeek V3 发布并开源,以其极低的训练成本,在海外开源社区引起关注和讨论;2025年1月20日,DeepSeek R1发布并开源,能力比肩最先进的 OpenAI o1,彻底引爆全球。
从微信的指数趋势上看 - 长周期
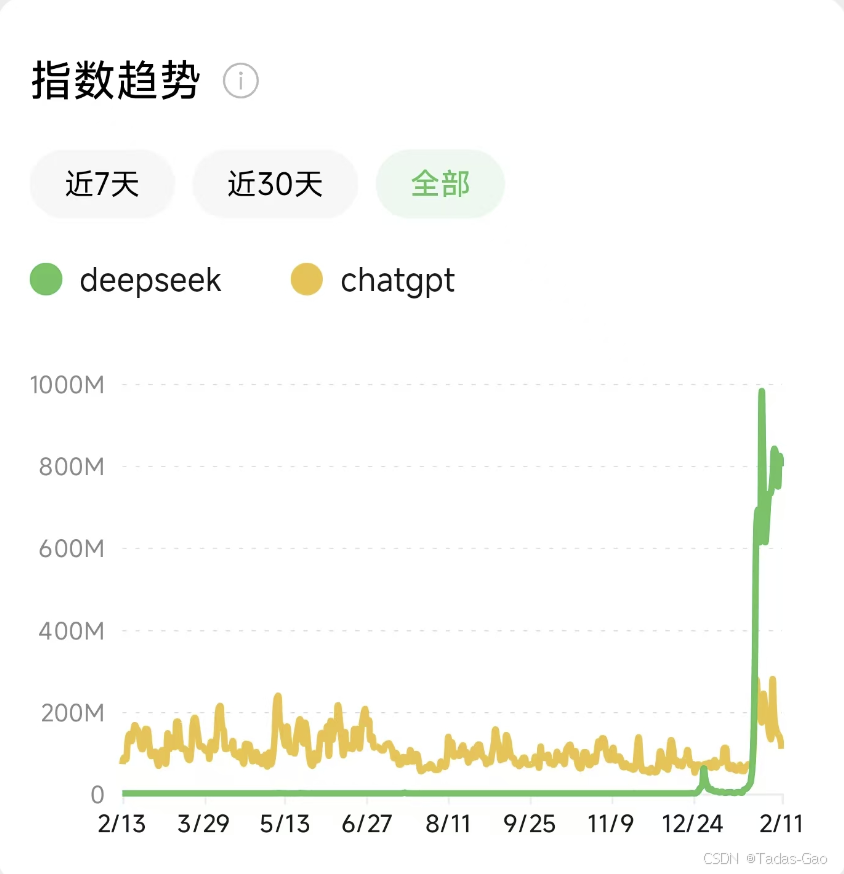
1. DeepSeek 的爆发式增长
- 2025 年 1 月 20 日,DeepSeek 发布 DeepSeek-R1 模型,随后迅速走红。
- 截至 2025 年 2 月 20 日,DeepSeek 的微信指数平均值达到 5.9 亿,峰值逼近 10 亿,远超同期 ChatGPT 的指数。
- 相比之下,ChatGPT 在 2 月初的日活呈现 断崖式下跌,而 DeepSeek 则持续攀升,成为全球 AI 应用日活 TOP 15。
2. ChatGPT 的热度相对下降
- ChatGPT 在 2025 年 1 月的表现相对稳定,但在 DeepSeek 爆火后(2 月初),其日活开始下滑。
- 部分原因可能是 OpenAI 的 ChatGPT 在搜索功能上的开放(如无需注册即可使用 ChatGPT 搜索)未能完全抵消 DeepSeek 带来的冲击
从微信的指数趋势上看 - 短周期

1. DeepSeek 热度爆发(1月20日后)
-
1月20日,DeepSeek 发布 DeepSeek-R1 模型,引发广泛关注,微信指数迅速攀升。
-
1月底至2月初,DeepSeek 的微信指数持续增长,并因 微信灰度测试接入 DeepSeek-R1(2月初)进一步推高热度。
-
2月11日前后,DeepSeek 的日活(DAU)已突破 3000万,成为全球增长最快的 AI 应用之一,微信指数峰值接近 10亿。
2. ChatGPT 热度相对下滑
-
1月13日-1月28日,ChatGPT 仍保持较高热度,但 OpenAI 的商业模式(如高价订阅)使其在用户增长上受限。
-
1月28日后,随着 DeepSeek-R1 的发布,ChatGPT 的微信指数开始出现 断崖式下跌,部分用户转向免费且性能更强的 DeepSeek。
-
2月13日(临近2月11日),OpenAI 宣布 ChatGPT 将免费提供 GPT-5 标准版,但此时 DeepSeek 已占据市场主导地位。
从谷歌指数上看
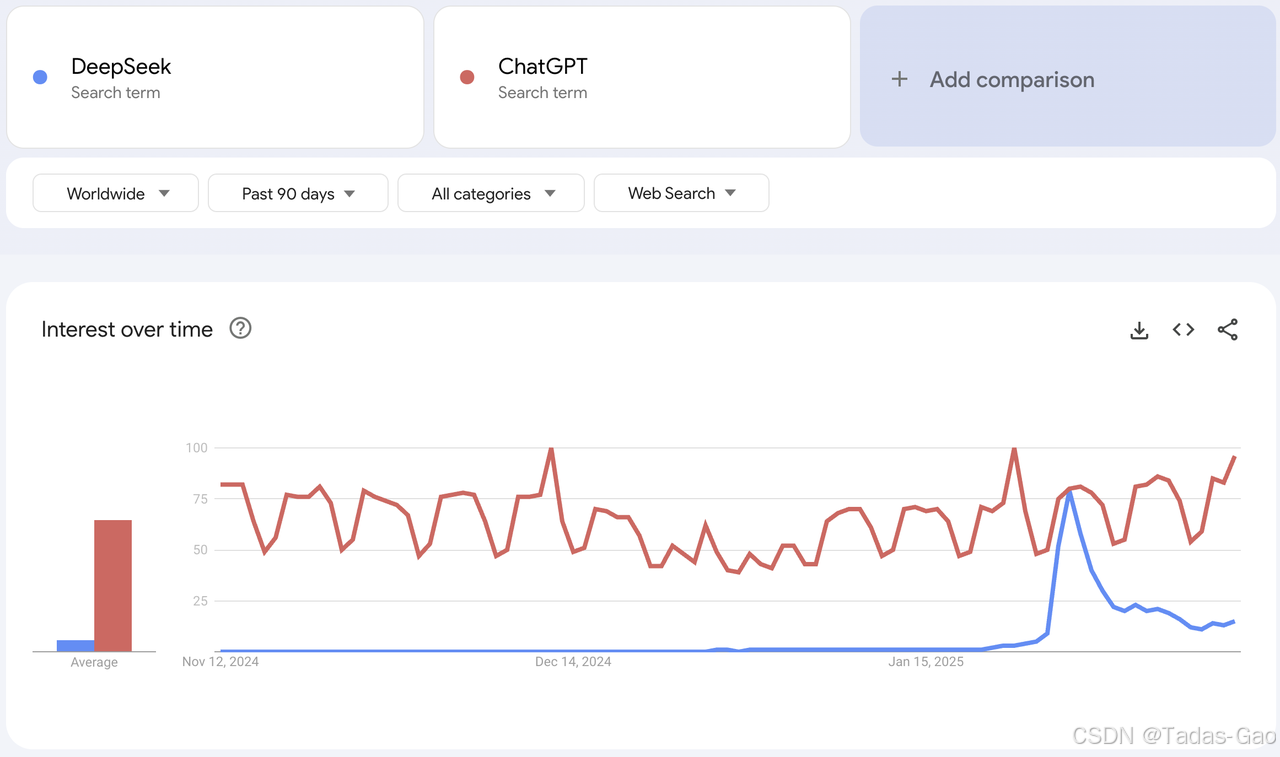

1. ChatGPT 的早期优势(2024年11月-12月)
-
ChatGPT 作为 OpenAI 的旗舰产品,在2024年11月至12月期间仍然占据市场主导地位,尤其是在欧美市场,其搜索指数保持较高水平。
-
OpenAI 在2024年11月发布了 GPT-4 Turbo 版本,进一步巩固了其市场地位。
-
谷歌 Gemini(原 Bard)的推出对 ChatGPT 构成一定竞争,但 ChatGPT 仍被视为行业标杆。
2. DeepSeek 的崛起(2025年1月-2月)
-
2025年1月20日,DeepSeek 发布 DeepSeek-R1 模型,引发全球AI行业关注,搜索指数开始迅速攀升。
-
2025年2月初,DeepSeek 的访问量激增 614%,甚至超越谷歌 Gemini,成为全球第二大受欢迎的 AI 对话机器人(仅次于 ChatGPT)。
-
DeepSeek 的 开源策略 和 低成本推理(仅为 OpenAI 的 1/50)使其在开发者社区迅速流行。
-
2025年2月6日,OpenAI 宣布 ChatGPT 搜索功能免费开放,试图应对 DeepSeek 的竞争,但 DeepSeek 的增长势头仍然强劲。
3. 关键趋势对比
| 时间 | ChatGPT 趋势 | DeepSeek 趋势 | 关键事件 |
|---|---|---|---|
| 2024年11月 | 高(GPT-4 Turbo 发布) | 低(尚未爆发) | OpenAI 巩固市场 |
| 2024年12月 | 稳定 | 小幅上升 | DeepSeek 开始引起关注 |
| 2025年1月 | 小幅下滑 | 大幅增长 | DeepSeek-R1 发布 |
| 2025年2月 | 明显下滑(竞争加剧) | 峰值(访问量超 Gemini) | OpenAI 开放免费搜索 |
从幻方量化到 DeepSeek

幻方量化(High Flyer)由梁文锋于2015年在杭州创立,是一家专注于量化投资的对冲基金公司,核心业务是通过数学建模、统计学方法及人工智能技术优化投资策略。
幻方量化在2016年首次上线AI交易策略,2017年实现投资策略全面AI化,技术实力在金融领域处于领先地位。不同于高频交易员通过提前几毫秒下单来获取优势,幻方量化更专注于中频交易,即持仓时间较长的交易方式。

深度求索(DeepSeek)成立于2023年7月,是幻方量化孵化的全资子公司,专注于通用人工智能(AGI)和大模型研发。
DeepSeek 在 AI 研发方面的策略——用更少的团队、更少的资金和更少的芯片做更多的事情——让我们想起了量化交易员的做法。他们似乎专注于从相对较少的数据中提取大量信号,这与量化交易的精神非常相似。
从幻方量化到DeepSeek的发展历程,是中国量化投资与人工智能(AI)技术深度融合的典型案例,展现了金融科技向通用人工智能(AGI)领域的延伸与突破。
以下是两者的关联、发展路径及行业影响的分析:
1. 起源:幻方量化的AI基因
幻方量化是中国头部量化私募之一,早在2017年就全面转向深度学习驱动的量化投资策略,并投入数十亿元建设“萤火”系列AI算力集群。其核心优势包括:
-
算力储备:2023年前已拥有1万张NVIDIA A100显卡,与百度、腾讯、阿里等并列国内第一梯队。
-
AI量化实践:在ChatGPT 3.5问世前,幻方已采用AI模型优化交易策略,并推出多只AI量化基金,如中证500、1000指数增强产品。
-
技术沉淀:在高频数据处理、因子挖掘、预测模型等领域积累深厚,为后续孵化DeepSeek奠定基础。
2. DeepSeek的孵化与独立发展
2023年7月,幻方量化核心团队孵化成立DeepSeek(深度求索),专注于大语言模型(LLM)研发。其发展路径如下:
-
2023年11月:发布首个开源代码模型DeepSeek Coder,支持编程辅助。
-
2024年5月:推出DeepSeek-V2(2360亿参数MoE架构),推理成本降至1元/百万token。
-
2024年12月:发布DeepSeek-V3(6710亿参数),训练成本仅557.6万美元(对比LLaMA-3节省90%算力)。
-
2025年1月:推出DeepSeek-R1,性能对标OpenAI o1,并登顶美区App Store免费榜第六。
关键转折点:
DeepSeek从幻方的金融AI团队独立,专注于通用AI而非量化策略,形成“技术溢出”模式。两者共享算法与算力基础设施,但业务完全分离:
-
幻方:继续优化AI量化3.5模型,管理规模近百亿美元。
-
DeepSeek:聚焦开源大模型,成为全球AI领域的重要竞争者。
3. 技术协同与差异化
| 维度 | 幻方量化 | DeepSeek |
|---|---|---|
| 核心技术 | 高频交易预测、因子挖掘 | MoE架构、FP8训练、多模态AI |
| 应用场景 | 量化资管(如指数增强基金) | 通用AI(代码生成、对话、推理) |
| 商业模式 | 私募基金收益分成 | 开源模型+商业API |
| 行业影响 | 推动AI量化成为资管新范式 | 挑战ChatGPT,降低大模型门槛 |
4. 行业影响与未来趋势
-
AI量化普及:幻方和DeepSeek的成功促使国内15家百亿量化私募加速AI布局。
-
算力高效化:DeepSeek的MoE+FP8训练技术重塑行业标准,证明大模型可低成本训练。
-
生态竞争:DeepSeek-R1接入微信等超级App,而OpenAI被迫免费开放GPT-5标准版应对竞争。
从性能看 DeepSeek


| 测试集名称 | 领域 | 主要聚焦能力 |
| MMLU Pro | 多任务语言理解 | 复杂推理、多学科知识整合 |
| GPQA-Diamond | STEM学科 | 研究生水平的深度科学推理、专业领域知识应用 |
| MATH-500 | 数学 | 综合数学解题能力(代数/几何/数论等) |
| AIME2024 | 数学竞赛 | 高难度数学问题解决(竞赛级题目) |
| CodeForces | 编程竞赛 | 算法设计与实现、实时编程问题解决 |
| SWE-Bench Verified | 软件工程 | GitHub Issue处理、单元测试通过率、代码稳定性维护 |
-
DeepSeek-V3 在开源模型中领先,接近闭源顶级模型(如 Claude-3.5-Sonnet)。
-
GPT-4o-0513 表现较强,但不如 DeepSeek-V3 在部分任务中的表现。
-
DeepSeek-V3 在复杂推理任务上表现优异,甚至超越部分闭源模型。
-
GPT-4o 在 GPQA 上表现一般,可能因其更偏向通用任务而非深度推理。
-
DeepSeek-V3 在数学推理上具有显著优势,可能得益于其 MoE 架构 和 多令牌预测(MTP) 优化。
-
GPT-4o 数学能力较强,但不如 DeepSeek-V3 专精。
-
DeepSeek-V3 在竞赛级数学题目上表现卓越,可能是目前最强的数学推理 AI 模型之一。
-
GPT-4o 在 AIME 上表现不佳,可能因其更偏向通用推理而非数学竞赛优化。
-
DeepSeek-V3 在算法编程竞赛中表现极强,可能得益于 强化学习优化 和 高质量代码数据蒸馏。
-
GPT-4o 编程能力优秀,但 DeepSeek-V3 更具竞争力。
-
DeepSeek-V3 在工程代码任务上接近 Claude-3.5-Sonnet,显示其强大的实际开发能力。
从价格看 DeepSeek

| 象限 | 代表模型 | 特点 |
|---|---|---|
| 左上(高性价比) | DeepSeek-R1 | 性能强,价格低 |
| 右上(高性能高成本) | GPT-4o、Claude 3.5 | 性能顶尖,但价格昂贵 |
| 左下(低性能低成本) | Llama-3.1 | 开源免费,但能力有限 |
| 右下(低性价比) | 部分早期闭源模型 | 性能一般,价格高 |

-
DeepSeek-V3 的 API 价格仅为 GPT-4o 的 1/30,性价比极高。
-
Claude 3.5 价格较高,但推理能力较强,适合企业级应用。
-
Mistral & Llama 价格较低,但性能稍逊于 DeepSeek-V3。
DeepSeek 一夜爆火的核心原因
1. 强大:性能比肩国际顶尖模型
DeepSeek 在多个 AI 基准测试中表现卓越,甚至超越 OpenAI 的 GPT-4o 和 o1 模型:
-
数学推理:在 MATH-500 测试中,DeepSeek-R1 得分 97.3%,与 OpenAI-o1 相当。
-
代码生成:HumanEval 测试准确率达 87.3%,超过 GPT-4 基线。
-
推理优化:采用 强化学习(RL)+ 冷启动数据,减少对标注数据的依赖,提升推理能力。
-
多模态支持:不仅能处理文本,还支持图像、音频、视频,满足多样化需求。
2. 便宜:API 价格仅为 OpenAI 的 1/30
DeepSeek 的 超低 API 定价 使其成为企业级 AI 的首选:
-
输入 tokens:1 元/百万(缓存命中),4 元/百万(未命中)。
-
输出 tokens:16 元/百万,仅为 OpenAI-o1 的 3.7%。
-
训练成本仅 557.6 万美元,而 OpenAI o1 高达 5 亿美元,成本优势显著。
3. 开源:共享开放,推动 AI 普惠化
DeepSeek 坚持 完全开源,包括模型权重、训练框架和数据管道:
-
开发者可自由下载、修改、商业化,降低 AI 技术门槛。
-
开源策略吸引全球开发者,GitHub 星标数 3 个月突破 2.4 万。
-
促进生态繁荣,已有 127 个社区优化版本,加速技术迭代。
4. 免费:普通用户零成本体验顶级 AI
-
Web 端 & 移动端完全免费,用户无需订阅即可使用高性能 AI。
-
相比 OpenAI 的 GPT-5 标准版收费,DeepSeek 的免费策略更具吸引力。
-
春节期间,DeepSeek 凭借 走心回答 赢得用户情感共鸣,进一步扩大用户基础。
5. 联网:实时获取最新信息
DeepSeek-R1 具备 联网搜索能力,可实时查询网络最新数据,适用于:
-
新闻查询:提供最新资讯,避免传统 AI 的知识滞后问题。
-
学术研究:快速检索论文、行业报告等专业内容。
-
市场调研:动态分析商业数据,辅助决策。
6. 本土:国产 AI 的突破性崛起
DeepSeek 由中国团队自主研发,打破国外技术垄断:
-
无海外背景,完全自主可控,符合国产化替代趋势。
-
采用 PTX 编程,绕过英伟达 CUDA 限制,降低对美系 GPU 依赖。
-
政策支持:进入央采目录,获政府、国企青睐,加速行业落地。
这种 “极致性价比+开放生态+本土优势” 的组合,使 DeepSeek 迅速成为全球 AI 领域的标杆,甚至倒逼 OpenAI 调整商业模式(如免费开放 ChatGPT 搜索)。未来,DeepSeek 能否持续领跑,取决于其 商业化落地能力 和 生态建设深度,但目前的爆发已证明——AI 的未来,不再只是硅谷的独角戏。
解析 DeepSeek 的发展
| 日期 | 版本 | 核心技术 | 主要特点及结论 |
| 2024年1月 | DeepSeek LLM | 预训练、SFT、DPO | 67B dense 密集模型;HAI-LLM 训练框架。初步在密集模型验证了 Scale law |
| 2024年1月 | DeepSeek MoE(V1) | MoE | 2B/16B/145B;精细分割、共享专家隔离,减少知识冗余。初步在混合专家模型上验证了Scale law |
| 2024年1月 | DeepSeek Coder | NTP;FIM | 1.3B到33B;提升代码和数学推理能力 |
| 2024年2月 | DeepSeek Math | GRPO;RL | 7B模型,提升数学推理任务 |
| 2024年3月 | DeepSeek VL | 混合视觉编码 | 1.3B、7B,验证多模态训练策略 |
| 2024年5月 | DeepSeek V2 | MoE;MLA | 236B 总参数,21B 激活参数;通过 MLA 显著减少 KV 缓存 |
| 2024年5月 | DeepSeek Prover | 合成数据 | 基于Math-7B,提升形式化定理证明能力;合成数据 |
| 2024年6月 | DeepSeek Coder V2 | MoE;GRPO | 16B激活2.4B、236B激活21B;显著增强了编码和数学推理能力 |
| 2024年7月 | ESFT | PEFT/ESFT | 专家专业化微调,提高训练效率和效果 |
| 2024年8月 | DeepSeek Prover V1.5 | GRPO;RMaxTS | 强化学习和 CoT 对模型能力显著提升;RMaxTS 蒙特卡洛树搜索算法的探索策略提高证明成功率 |
| 2024年10月 | Janus | 视觉编码解耦;统一多模态框架 | 视觉编码解耦;自回归变换器架构 |
| 2024年11月 | Janus Flow | Rectified Flow;表示对齐 | 图像理解和生成统一,增强了模型多模态理解能力 |
| 2024年12月 | DeepSeek VL2 | MoE;MLA;动态平铺视觉编码 | 3个尺寸,27B激活4.1B;提升多模态能力 |
| 2024年12月 | DeepSeek V3 | MoE;MLA;MTP;FP8混合精度训练 | 671B 总参数,37B 激活参数;训练、推理高效 |
| 2025年1月 | DeepSeek R1 | RL;GRPO;知识蒸馏 | 671B推理模型;蒸馏为1.5B~70B小模型;验证强化学习增强推理能力 |
| 2025年1月 | Janus Pro | 视觉编码解耦;统一多模态框架 | 1B、7B模型;统一多模态理解和文本生成图像 |
上面的表格可以看出 DeepSeek 在发展过程中逐步引入的技术(扩展阅读:从碳基羊驼到硅基LLaMA:开源大模型家族的生物隐喻与技术进化全景-优快云博客)。
接下来,我们挑几个技术来扩展一下。
关于MoE,可以先回顾一下:聊聊DeepSeek V3中的混合专家模型(MoE)-优快云博客
MHA vs. GQA vs. MQA vs. MLA
下图中的几种技术都是为了提高大模型的推理效率:

| 机制 | 全称 | 核心思想 | 优势 | 劣势 | 典型应用 |
|---|---|---|---|---|---|
| MHA | 多头注意力 (Multi-Head Attention) | 每个注意力头独立计算 Q/K/V,增强特征多样性 | 表达能力最强,适合复杂任务 | 计算和内存开销大,KV Cache 占用高 | Transformer 原始架构 |
| MQA | 多查询注意力 (Multi-Query Attention) | 所有查询头 共享一组 K/V,大幅减少参数 | 推理速度最快,内存占用极低 | 性能下降明显,训练不稳定 | PaLM、StarCoder |
| GQA | 分组查询注意力 (Grouped-Query Attention) | 查询头 分组共享 K/V,平衡效率与性能 | 接近 MQA 的速度,性能接近 MHA | 需调优分组数 | LLaMA-2/3、ChatGLM |
| MLA | 多头潜在注意力 (Multi-head Latent Attention) | 引入 低秩潜在空间 压缩 KV Cache,动态增强头间差异 | 内存效率最高,性能接近 MHA | 实现复杂,兼容性要求高 | DeepSeek-V2 |
1. 多头注意力 (MHA)
特点:每个头都有自己的 Q、K、V,完全独立。
举例: 你有 8 个朋友(8个头),每个人分别问你“今晚吃啥?”,然后各自去翻菜单(各自的 K),最后各自给你推荐一道菜(各自的 V)。最后你把 8 个推荐综合起来决定。
优点:全方位多角度分析,效果最好。
缺点:计算量大(8 个人忙活,当然累)。
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
"""
多头注意力 (MHA) 初始化
:param d_model: 输入特征维度(如 512)
:param num_heads: 注意力头数(如 8,需满足 d_model % num_heads == 0)
"""
super().__init__()
self.d_model = d_model # 模型总维度
self.num_heads = num_heads # 注意力头数量
self.head_dim = d_model // num_heads # 每个头的维度(如 512/8=64)
# 初始化投影矩阵(每个头独立)
self.W_q = nn.Linear(d_model, d_model) # Query 投影矩阵
self.W_k = nn.Linear(d_model, d_model) # Key 投影矩阵
self.W_v = nn.Linear(d_model, d_model) # Value 投影矩阵
self.W_o = nn.Linear(d_model, d_model) # 输出投影矩阵
def forward(self, x):
"""
:param x: 输入张量,形状为 [batch_size, seq_len, d_model]
:return: 注意力输出,形状与输入相同 [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.shape
# 1. 计算 Q/K/V 并分割多头
# 公式:Q = XW_q, K = XW_k, V = XW_v
# [batch, seq_len, d_model] -> [batch, seq_len, num_heads, head_dim] -> [batch, num_heads, seq_len, head_dim]
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
K = self.W_k(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
V = self.W_v(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 2. Scaled Dot-Product Attention 计算
# 公式:Attention(Q,K,V) = softmax(QK^T/sqrt(d_k))V
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5) # [batch, num_heads, seq_len, seq_len]
attn = torch.softmax(scores, dim=-1) # 注意力权重 [batch, num_heads, seq_len, seq_len]
# 3. 加权求和
output = torch.matmul(attn, V) # [batch, num_heads, seq_len, head_dim]
# 4. 合并多头输出
# [batch, num_heads, seq_len, head_dim] -> [batch, seq_len, num_heads, head_dim] -> [batch, seq_len, d_model]
output = output.transpose(1, 2).contiguous() # contiguous() 确保内存连续
output = output.view(batch_size, seq_len, -1) # 拼接所有头的输出
# 5. 输出投影
return self.W_o(output) # [batch, seq_len, d_model]2. 分组查询注意力 (GQA)
核心:减少计算量
特点:分组共享 K 和 V,是 MHA 和 MQA 的折中方案。
举例: 8 个朋友分成 4 组(比如 2 人一组),每组共享一本菜单(K 和 V),但组和组之间的菜单不同。这样既省力(只用 4 本菜单),又比 MQA 多样。
优点:平衡速度和效果(比如 Llama-2)。
import torch
import torch.nn as nn
class GroupedQueryAttention(nn.Module):
def __init__(self, d_model, num_heads, num_groups):
"""
分组查询注意力 (GQA) 初始化
:param d_model: 输入特征维度(如 512)
:param num_heads: 注意力头数(如 8)
:param num_groups: K/V 的分组数(如 4,需满足 num_heads % num_groups == 0)
"""
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.num_groups = num_groups
self.head_dim = d_model // num_heads # 每个头的维度(如 512/8=64)
# 初始化投影矩阵
self.W_q = nn.Linear(d_model, d_model) # 独立投影 Q(每个头独立)
self.W_k = nn.Linear(d_model, num_groups * self.head_dim) # 分组投影 K(输出维度=组数*头维度)
self.W_v = nn.Linear(d_model, num_groups * self.head_dim) # 分组投影 V
self.W_o = nn.Linear(d_model, d_model) # 输出投影
def forward(self, x):
"""
:param x: 输入张量,形状为 [batch_size, seq_len, d_model]
:return: 注意力输出,形状同输入
"""
batch_size, seq_len, _ = x.shape
# 1. 计算 Q (Query)
# [batch, seq_len, d_model] -> [batch, num_heads, seq_len, head_dim]
Q = self.W_q(x) # 线性投影
Q = Q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 2. 计算 K (Key) - 分组共享
# [batch, seq_len, d_model] -> [batch, seq_len, num_groups, head_dim]
K = self.W_k(x).view(batch_size, seq_len, self.num_groups, self.head_dim)
# 扩展为 [batch, seq_len, (num_heads//num_groups), num_groups, head_dim] -> reshape合并
K = K.unsqueeze(2) # 插入分组维度
K = K.expand(-1, -1, self.num_heads // self.num_groups, -1, -1) # 复制分组
K = K.reshape(batch_size, seq_len, self.num_heads, self.head_dim) # 合并为多头
# 3. 计算 V (Value) - 同 K 的分组逻辑
V = self.W_v(x).view(batch_size, seq_len, self.num_groups, self.head_dim)
V = V.unsqueeze(2).expand(-1, -1, self.num_heads // self.num_groups, -1, -1)
V = V.reshape(batch_size, seq_len, self.num_heads, self.head_dim)
# 4. 注意力计算
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5) # [batch, num_heads, seq_len, seq_len]
attn = torch.softmax(scores, dim=-1) # 注意力权重
output = torch.matmul(attn, V) # 加权求和 [batch, num_heads, seq_len, head_dim]
# 5. 合并多头输出
output = output.transpose(1, 2) # [batch, seq_len, num_heads, head_dim]
output = output.contiguous().view(batch_size, seq_len, -1) # 拼接所有头
return self.W_o(output) # 输出投影 [batch, seq_len, d_model]3. 多查询注意力 (MQA)
核心:提高计算效率
特点:多个头共享同一份 K 和 V,但 Q 是独立的。
举例: 还是 8 个朋友问你“今晚吃啥?”,但这次大家共用同一本菜单(共享 K 和 V)。每个人根据菜单选出自己觉得最好的菜。
优点:省计算量(只用一本菜单),速度比 MHA 快。
缺点:信息多样性不如 MHA(毕竟菜单都一样)。
import torch
import torch.nn as nn
class MultiQueryAttention(nn.Module):
def __init__(self, d_model, num_heads):
"""
多查询注意力 (MQA) 初始化
:param d_model: 输入特征维度(如 512)
:param num_heads: 注意力头数(如 8,需满足 d_model % num_heads == 0)
"""
super().__init__()
self.d_model = d_model # 模型总维度
self.num_heads = num_heads # 注意力头数量
self.head_dim = d_model // num_heads # 每个头的维度(如 512/8=64)
# 初始化投影矩阵
self.W_q = nn.Linear(d_model, d_model) # Query 投影矩阵(每个头独立)
self.W_k = nn.Linear(d_model, self.head_dim) # Key 投影矩阵(共享,输出维度=head_dim)
self.W_v = nn.Linear(d_model, self.head_dim) # Value 投影矩阵(共享)
self.W_o = nn.Linear(d_model, d_model) # 输出投影矩阵
def forward(self, x):
"""
:param x: 输入张量,形状为 [batch_size, seq_len, d_model]
:return: 注意力输出,形状与输入相同 [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.shape
# 1. 计算 Q (Query) - 每个头独立
# [batch, seq_len, d_model] -> [batch, seq_len, num_heads, head_dim] -> [batch, num_heads, seq_len, head_dim]
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 2. 计算 K/V (Key/Value) - 所有头共享
# 先投影为 [batch, seq_len, 1, head_dim],再扩展为 [batch, seq_len, num_heads, head_dim]
K = self.W_k(x).view(batch_size, seq_len, 1, self.head_dim).expand(-1, -1, self.num_heads, -1)
V = self.W_v(x).view(batch_size, seq_len, 1, self.head_dim).expand(-1, -1, self.num_heads, -1)
# 3. Scaled Dot-Product Attention 计算
# 公式:Attention(Q,K,V) = softmax(QK^T/sqrt(d_k))V
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5) # [batch, num_heads, seq_len, seq_len]
attn = torch.softmax(scores, dim=-1) # 注意力权重 [batch, num_heads, seq_len, seq_len]
# 4. 加权求和
output = torch.matmul(attn, V) # [batch, num_heads, seq_len, head_dim]
# 5. 合并多头输出
# [batch, num_heads, seq_len, head_dim] -> [batch, seq_len, num_heads, head_dim] -> [batch, seq_len, d_model]
output = output.transpose(1, 2).contiguous() # contiguous() 确保内存连续
output = output.view(batch_size, seq_len, -1) # 拼接所有头的输出
# 6. 输出投影
return self.W_o(output) # [batch, seq_len, d_model]4. 多头潜在注意力 (MLA)
特点:不同头关注不同粒度的信息(比如有的看局部,有的看全局)。
举例: 8 个朋友分工明确:2 人看菜品细节(比如“红烧肉要不要加辣椒”),2 人看菜系分类(比如“川菜还是粤菜”),剩下 4 人看整体搭配(比如“荤素平衡”)。
优点:适合处理多尺度数据(如图像、长文本)。
缺点:设计复杂。
import torch
import torch.nn as nn
class MultiHeadLatentAttention(nn.Module):
def __init__(self, d_model, num_heads, latent_dim=64):
"""
多头潜在注意力 (MLA) 初始化
:param d_model: 输入特征维度(如 512)
:param num_heads: 注意力头数(如 8,需满足 d_model % num_heads == 0)
:param latent_dim: 潜在空间维度(默认 64,远小于 d_model)
"""
super().__init__()
self.d_model = d_model # 模型总维度
self.num_heads = num_heads # 注意力头数量
self.head_dim = d_model // num_heads # 每个头的维度(如 512/8=64)
self.latent_dim = latent_dim # 潜在空间压缩维度
# 初始化投影矩阵
self.W_q = nn.Linear(d_model, d_model) # Query 投影矩阵(保持高维)
self.W_k = nn.Linear(d_model, latent_dim) # Key 低维投影(压缩到潜在空间)
self.W_v = nn.Linear(d_model, latent_dim) # Value 低维投影
self.W_l = nn.Linear(latent_dim, num_heads * self.head_dim) # 潜在空间到多头的重建
self.W_o = nn.Linear(d_model, d_model) # 输出投影矩阵
def forward(self, x):
"""
:param x: 输入张量,形状为 [batch_size, seq_len, d_model]
:return: 注意力输出,形状与输入相同 [batch_size, seq_len, d_model]
"""
batch_size, seq_len, _ = x.shape
# 1. 计算 Q (Query) - 保持原始维度
# [batch, seq_len, d_model] -> [batch, seq_len, num_heads, head_dim] -> [batch, num_heads, seq_len, head_dim]
Q = self.W_q(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 2. 计算 K (Key) - 通过潜在空间压缩
# 步骤:
# (1) 先压缩到低维潜在空间: [batch, seq_len, d_model] -> [batch, seq_len, latent_dim]
# (2) 再重建为多头格式: [batch, seq_len, latent_dim] -> [batch, seq_len, num_heads, head_dim]
# (3) 调整维度: [batch, num_heads, seq_len, head_dim]
K = self.W_k(x) # 低维投影
K = self.W_l(K) # 重建为多头维度
K = K.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 3. 计算 V (Value) - 同 Key 的处理流程
V = self.W_v(x)
V = self.W_l(V)
V = V.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# 4. Scaled Dot-Product Attention 计算
# 公式:Attention(Q,K,V) = softmax(QK^T/sqrt(d_k))V
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.head_dim ** 0.5) # [batch, num_heads, seq_len, seq_len]
attn = torch.softmax(scores, dim=-1) # 注意力权重
# 5. 加权求和
output = torch.matmul(attn, V) # [batch, num_heads, seq_len, head_dim]
# 6. 合并多头输出
# [batch, num_heads, seq_len, head_dim] -> [batch, seq_len, num_heads, head_dim] -> [batch, seq_len, d_model]
output = output.transpose(1, 2).contiguous() # contiguous() 确保内存连续
output = output.view(batch_size, seq_len, -1)
# 7. 输出投影
return self.W_o(output) # [batch, seq_len, d_model]MQA 和 GQA 是在缓存多少数量KV的思路上进行优化:直觉是如果我缓存的KV个数少一些,显存就占用少一些,大模型能力的降低可以通过进一步的训练或者增加规模来弥补。
如果想进一步降低KV缓存的占用,从数量上思考已经不行了,那就势必得从KV本身思考,有没有可能每个缓存的KV都比之前小?这就是 DeepSeek V2 中推出的 MLA 解法。
KV Cache 需求:MHA > GQA > MQA ≈ MLA
推理速度:MQA > GQA > MLA > MHA
模型质量:MHA ≈ MLA > GQA > MQA
简单例子来理解 MHA、GQA、MQA、MLA。
MHA:公司开会,每个人自由发言讨论(各自提意见)。
GQA:分小组讨论,每组派代表汇总(平衡效率和多样性)。
MQA:老板一个人说方案,其他人只提修改意见(老板垄断了信息源)。
MLA:有人管战略,有人管细节,有人管执行(分工明确)。
扩展阅读:初探注意力机制-优快云博客、来聊聊Q、K、V的计算-优快云博客、Transformer 中的注意力机制很优秀吗?-优快云博客
MTP

一句话总结 MTP:普通模型像“挤牙膏”,一次只预测1个词;MTP 像“连珠炮”,一次蹦出多个词,大幅加速文本生成。
普通模型
你问:“今天天气怎...?” 模型:“么”(停住)→ “样”(停住)→ “?”(停住)。 每次只憋出1个词,像结巴说话,慢!
问题:生成100个词要算100次,效率低。
MTP
你问:“今天天气怎...?” 模型:“么样?”(直接输出3个词)。 一次预测多个词,像连珠炮,快!
关键:同时预测多个词(比如一次输出3~5个词),减少计算次数。
PPO vs. GRPO

一句话总结
-
PPO(近端策略优化)是强化学习的经典算法,让 AI 逐步调整策略,避免“步子迈太大扯着蛋”。
-
GRPO(群组相对策略优化)是 PPO 的升级版,取消价值模型,改用“组内 PK”方式计算奖励,训练更快、更省显存,特别适合大语言模型(LLM)的数学推理优化。
举个简单的例子
PPO(Proximal Policy Optimization)
-
你让 AI 解数学题 “3 + 5 = ?”
-
PPO 会让 AI 生成多个答案(如 “8”、“7”、“9”),然后给每个答案打分(如 1、0、0)。
-
AI 根据评分调整策略,让未来更可能输出 “8” 而不是 “7” 或 “9”。
GRPO(Group Relative Policy Optimization)
-
同样解 “3 + 5 = ?”,GRPO 让 AI 生成多个答案(如 “8”、“7”、“9”)。
-
计算它们的奖励(1、0、0),然后组内归一化(比如 “8” 比组内平均高 0.5 分)。
-
直接用这个相对优势优化策略
1. PPO
步骤1:AI 先瞎猜(初始策略)
-
AI 第一次看到 “3 + 5 = ?”,随机生成3个答案:
-
“7”(错误,奖励=0)
-
“8”(正确,奖励=1)
-
“9”(错误,奖励=0)
-
步骤2:裁判出场
-
PPO 的 Critic 模型 会评估每个答案的“潜在收益”:
比如预测:“7”未来可能得0.2分,“8”得0.9分,“9”得0.1分。
步骤3:限制更新幅度
-
AI 调整策略时,不能一下子完全否定“7”和“9”,而是小幅降低它们的概率,小幅提高“8”的概率。
-
核心:像教小孩,错了就温和纠正,防止“一下子改太猛导致崩溃”。
结果
-
训练多次后,AI 发现 “8” 得分高,最终学会稳定输出 “8”。
2. GRPO
步骤1:AI 同样瞎猜
-
生成3个答案:
-
“7”(错误,奖励=0)
-
“8”(正确,奖励=1)
-
“9”(错误,奖励=0)
-
步骤2:组内直接PK(没有Critic)
-
计算组内平均奖励 = (0+1+0)/3 ≈ 0.33
-
相对优势:
-
“7” = 0 - 0.33 = -0.33(比平均差)
-
“8” = 1 - 0.33 = +0.67(比平均好)
-
“9” = 0 - 0.33 = -0.33(比平均差)
-
步骤3:直接用优势值调整策略
-
AI 看到 “8” 的优势值最高,直接提高“8”的概率,降低其他答案的概率。
-
核心:像班级考试,你只要考得比平均分高就算进步,不用知道具体该得多少分。
结果
-
同样学会稳定输出 “8”,但省去了Critic的计算,训练更快。



















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











