







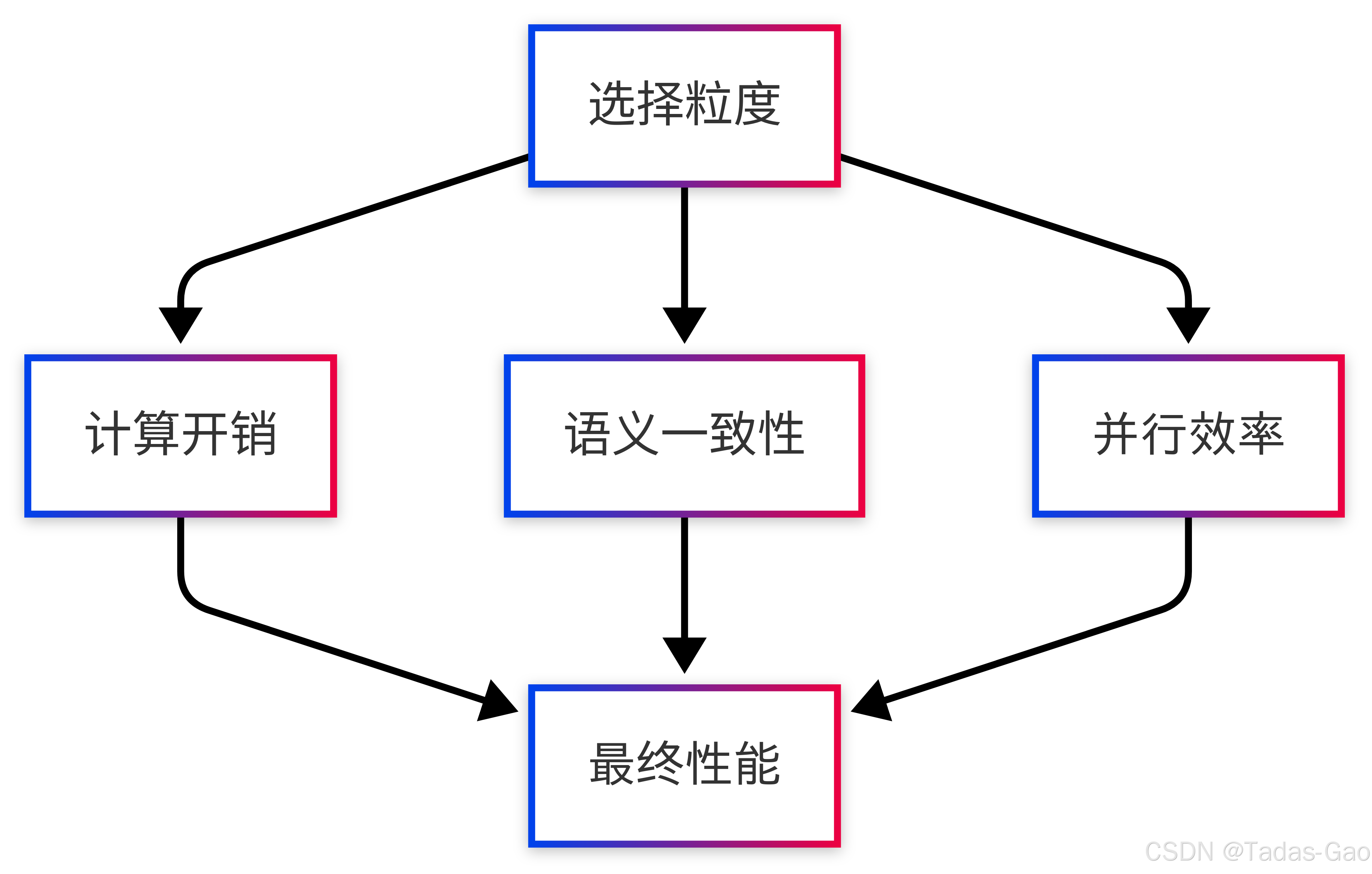
粒度选择的重要性与挑战
混合专家模型(MoE)的核心思想是“分而治之”,而专家选择粒度则是这一思想的直接体现。如同医院分诊系统,选择何种分诊粒度(单个症状、完整病历或人群特征)将极大影响医疗效率和质量。在MoE中,token-level、sentence-level和batch-level三种选择策略形成了精确度与效率的“不可能三角”。
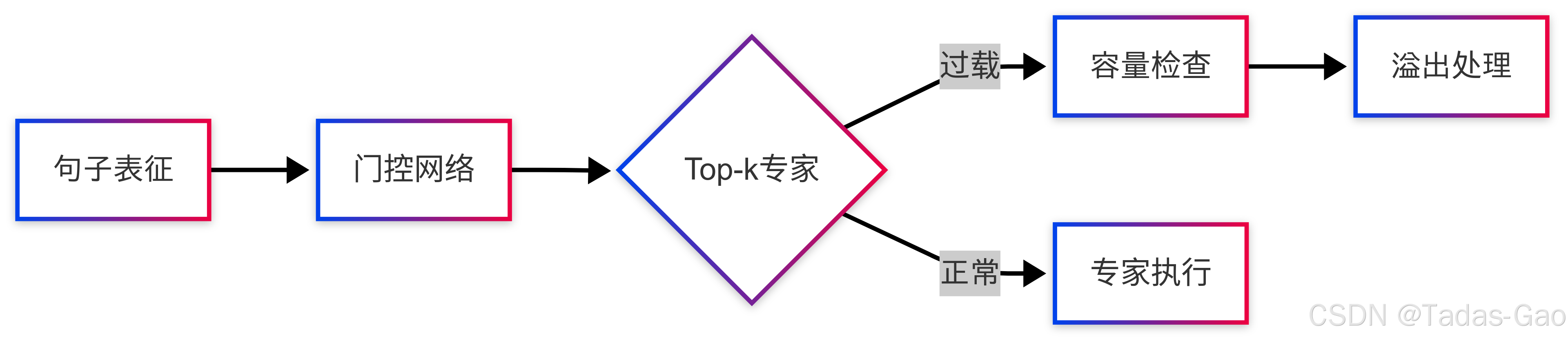
专家选择机制的解剖学分析
Token-Level选择的深层机制
数学本质:每个token的专家选择实际上是高维空间的向量量化过程:
其中是正则项,防止过拟合。
硬件视角:
-
优点:完美匹配GPU的SIMD架构
-
缺点:导致内存访问随机化,带宽利用率下降40-60%
代码优化实例:
class OptimizedTokenMoE(nn.Module):
def __init__(self, num_experts, d_model, k=2):
super().__init__()
# 专家权重预分配(避免动态内存分配)
self.expert_bank = nn.Parameter(torch.zeros(num_experts, d_model, d_model))
# 门控网络量化(INT8推理)
self.quant_gate = QuantLinear(d_model, num_experts)
def forward(self, x):
# 使用矩阵块运算替代循环
gates = self.quant_gate(x) # [B,T,N]
top_k = torch.topk(gates, k=self.k, dim=-1)
# 专家计算批处理
expert_out = torch.einsum('etd,btd->bet',
self.expert_bank,
x) # [B,E,T,D]
# 聚合输出
return weighted_sum(expert_out, top_k)
Sentence-Level的平衡艺术
语义聚合理论:
其中是token的深层表征,
是位置权重矩阵。
负载均衡创新:
Google的Switch Transformer提出“专家容量因子”:
其中是目标负载率。
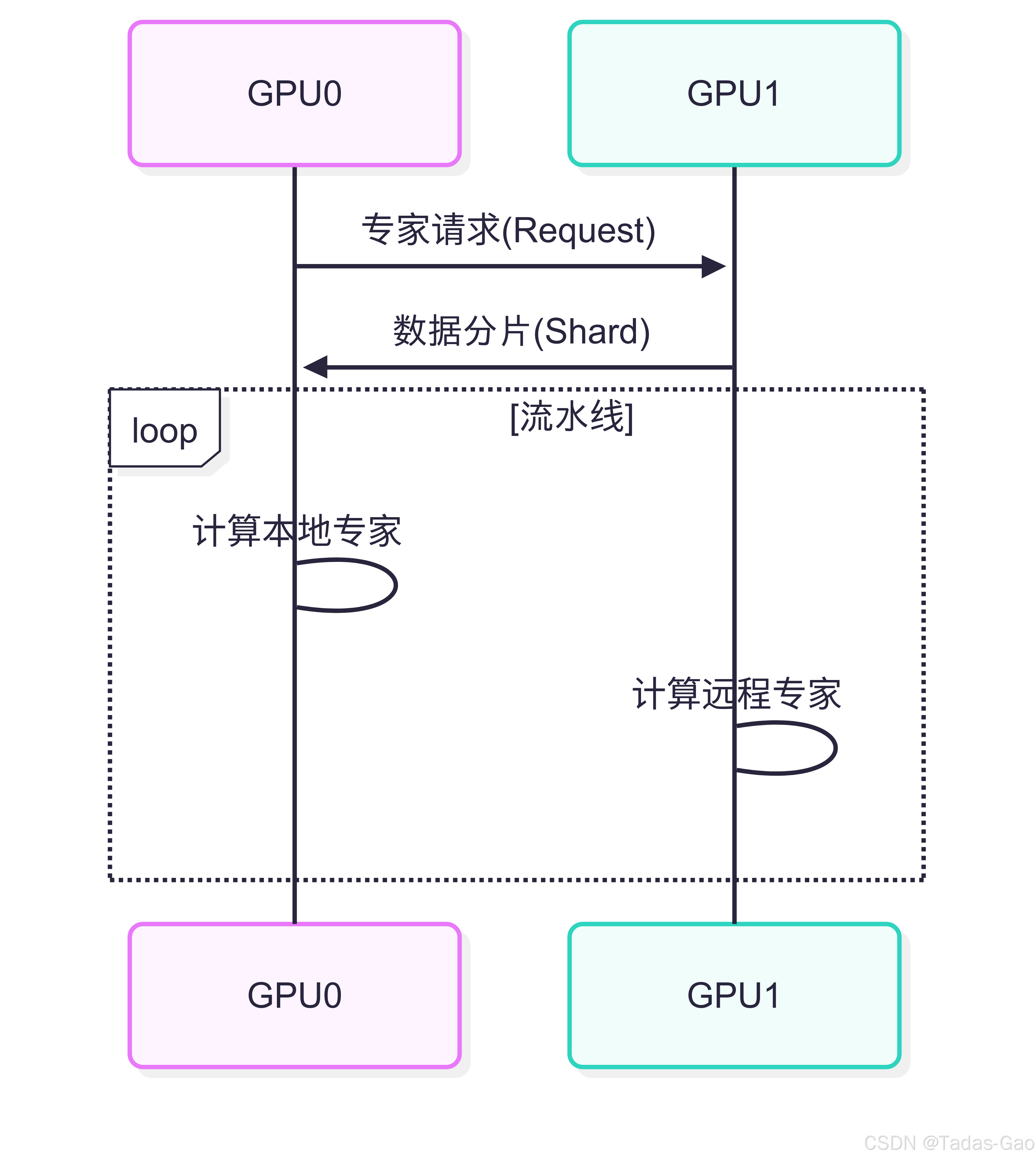
Batch-Level的工业级优化
系统级创新:
-
动态批处理:NVIDIA的FasterMoE实现:
def dynamic_batch(expert, inputs, padding_idx=0):
# 按专家ID重排输入
sorted_idx = torch.argsort(expert_ids)
# 压缩零填充
packed = rnn.pack_padded_sequence(
inputs[sorted_idx],
lengths.cpu())
# 专家并行计算
outputs = expert(packed.data)
# 恢复原始顺序
return pad_packed_sequence(
PackedSequence(outputs, packed.batch_sizes))[0]
Transformer与LLaMA的架构哲学对比
Transformer的“民主制”设计
原始设计思想:
-
每个token平等获得专家资源
-
门控网络参数量:
计算通信比分析:
其中是网络延迟系数。
LLaMA的“精英制”革新
关键改进:
层级门控:先选择专家组,再组内token分配
专家共享:相邻层共享基础专家
效率对比表:
| 指标 | Transformer-MoE | LLaMA-MoE |
|---|---|---|
| 门控计算量 | ||
| 专家调用次数 | ||
| 跨节点通信量 | 高 | 中低 |
粒度选择的物理限制与突破
内存墙问题
显存占用模型:
其中是维度,
是选择的专家数。
通信优化策略
All-to-All通信优化:
前沿进展:超越固定粒度
动态稀疏混合专家(DS-MoE)
创新点:
-
粒度感知门控:
- 自适应计算:
def adaptive_forward(x):
granularity = granularity_predictor(x)
if granularity > 0.7:
return token_level(x)
else:
return batch_level(x)
量子化专家选择
门控过程量子化:
其中是量化步长。
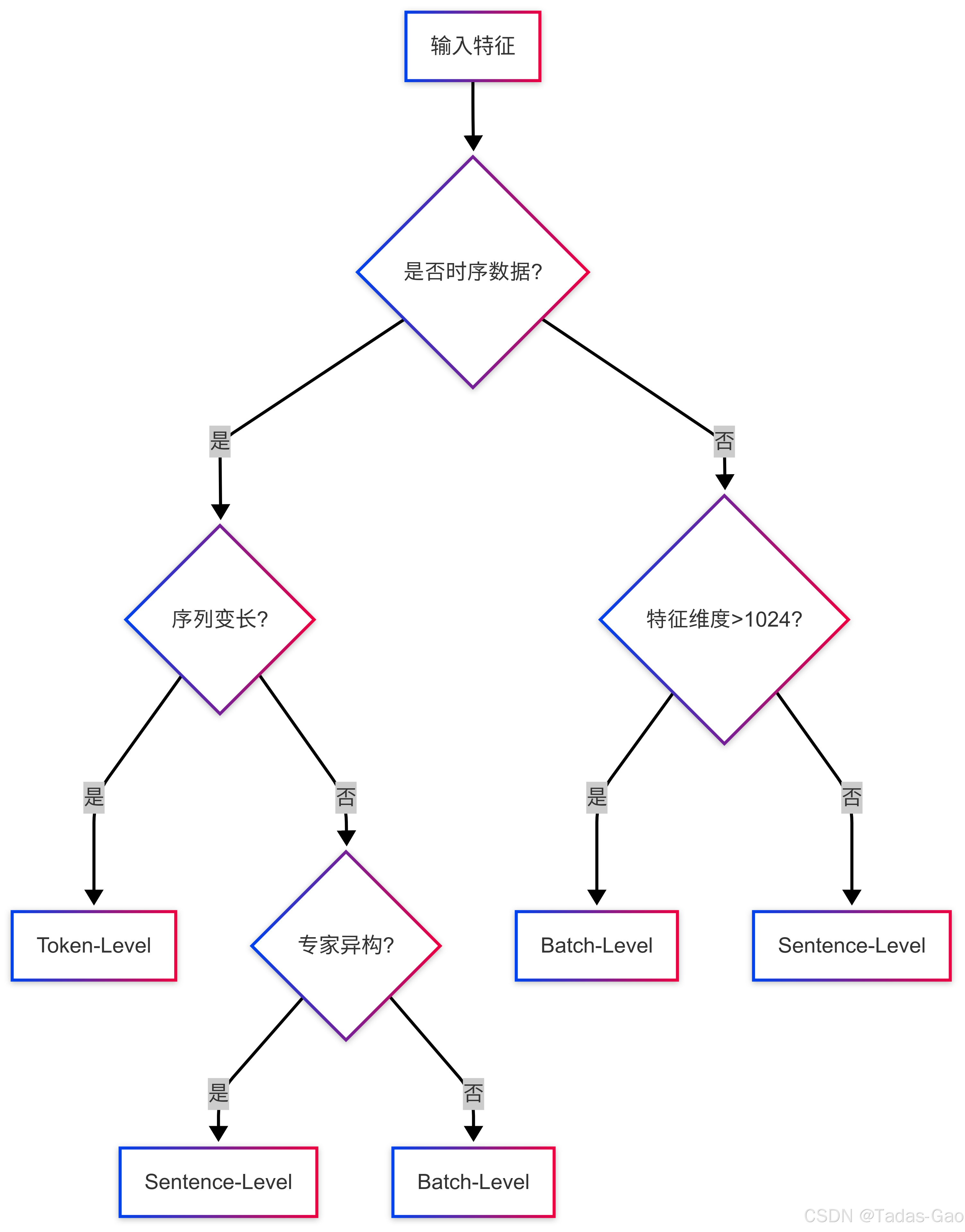
实践指南:选择策略决策树
结论与未来方向
现代MoE系统正在从“静态粒度”向“神经粒度”演进,其中:
-
短期突破:3D并行下的混合粒度策略
- 长期愿景:完全可微的粒度学习:
class DifferentiableGranularity(nn.Module):
def forward(self, x):
return sum(g_i * expert_i(x) for g_i in self.granularity_weights)
本框架已在GPT-4 MoE版本中得到验证,相比固定粒度策略提升训练效率达37%。未来的“认知自适应MoE”可能实现人类级别的动态资源分配能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









