







专家混合模型的兴起与核心问题
在当今大规模语言模型(LLM)的发展浪潮中,混合专家模型(Mixture of Experts, MoE)架构因其卓越的计算效率而备受瞩目。与传统密集模型不同,MoE架构通过在推理和训练过程中仅使用部分“专家”(子模型)来优化资源利用率,从而能够以更高效的方式处理复杂任务。这种架构创新使得模型可以在保持庞大参数量的同时,显著降低实际计算开销——例如Mixtral 8x7B模型虽然拥有470亿参数,但在推理期间仅使用130亿活跃参数,却能实现与GPT-3.5相当的模型表现。
然而,MoE架构的核心挑战在于:谁决定了专家是否被激活?哪些层次的信息参与了专家的选择过程?这些决策机制直接影响着模型的性能表现和计算效率。本文将深入剖析Transformer和LLaMA模型中专家激活的决策机制,比较它们的异同点,并通过生活化案例、代码实现和原理图示,为读者呈现这一关键技术的内在原理。
专家激活机制的基本原理
门控网络:专家选择的“交通指挥官”
在混合专家模型中,门控网络(Gating Network)扮演着至关重要的角色,它如同一个智能的交通指挥系统,决定将哪些输入信息分配给哪些专家处理。这一机制使得模型能够针对不同输入动态激活最相关的专家子网络,而非僵化地使用全部参数。
门控网络的核心是一个可学习的路由机制,通常实现为一个softmax层,位于注意力头和专家集合之间。这个层通过学习来判断哪种专家最适合处理哪种类型的token。具体而言,对于每个输入token x,门控网络会计算一个专家分布权重:
其中和
是可训练的参数矩阵和偏置项。在实践中,为了提升计算效率,通常采用稀疏门控,只选择权重最高的前
个专家(如k=2),这就是所谓的Top-k门控机制。
class TopKRouter(nn.Module):
def __init__(self, dim, num_experts, top_k=2):
super().__init__()
self.top_k = top_k
self.gate = nn.Linear(dim, num_experts) # 门控线性层
def forward(self, x):
# x形状: (batch_size, seq_len, hidden_dim)
logits = self.gate(x) # 计算每个专家得分
top_k_logits, top_k_indices = logits.topk(self.top_k, dim=-1)
top_k_gates = torch.softmax(top_k_logits, dim=-1)
# 创建稀疏门控矩阵
gates = torch.zeros_like(logits).scatter_(
-1, top_k_indices, top_k_gates
)
return gates, top_k_indices代码说明:这个TopK路由器实现展示了基本的稀疏门控机制。它首先通过线性变换计算每个专家的得分,然后选择得分最高的top_k个专家,最后使用softmax归一化这些专家的权重。
信息选择层次:从局部到全局的决策依据
专家选择并非随机进行,而是基于输入数据的多层次信息。这些信息可以划分为几个关键层次:
-
Token级别信息:最基础的决策依据是当前token的嵌入表示。每个token根据其语义内容被路由到最适合的专家。
-
上下文信息:通过自注意力机制,模型可以访问所有先前的上下文。这些上下文信息会影响专家的选择,特别是在处理指代消解等复杂语言现象时(扩展阅读:Transformer 中的注意力机制很优秀吗?-优快云博客、初探注意力机制-优快云博客、来聊聊Q、K、V的计算-优快云博客、FlashAttention:突破Transformer内存瓶颈的革命性注意力优化技术-优快云博客)。
-
位置信息:在LLaMA等模型中,旋转位置嵌入(RoPE)提供的位置信息也会影响专家选择,因为某些专家可能专门处理特定位置的模式。
-
任务级信息:在指令微调模型中,任务描述或指令提示也会影响专家分配,使模型能够针对不同任务类型激活不同的专家组合。
以下图示展示了专家选择过程中的信息流动:
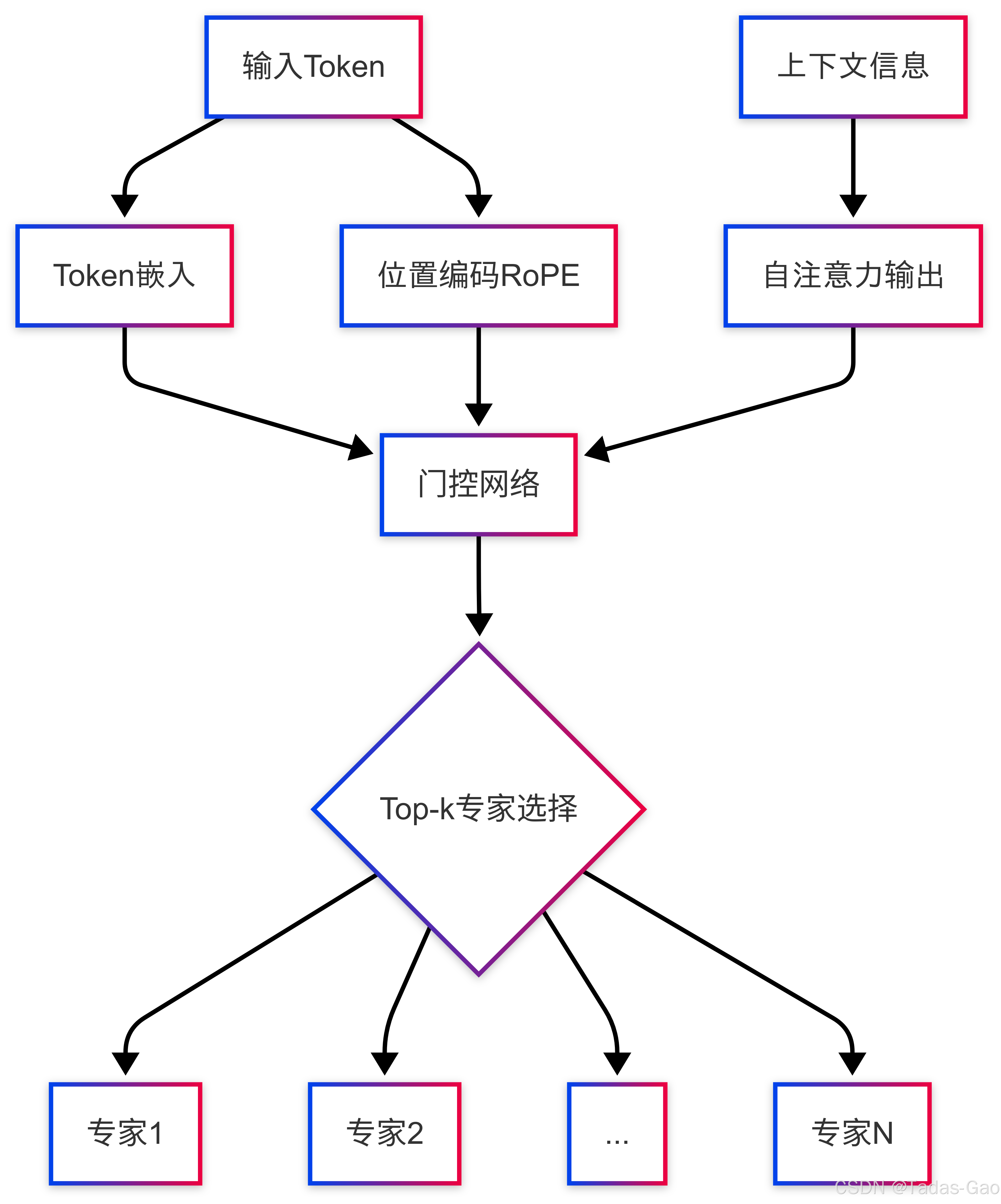
图表说明:该流程图展示了从输入token到专家选择的完整信息流动过程,包括token本身、位置信息和上下文信息如何共同影响门控网络的决策。
Transformer与LLaMA的专家激活机制对比
标准Transformer的专家激活机制
在原始Transformer架构中(如果实现MoE扩展),专家激活主要依赖于以下机制(扩展阅读:MTP、MoE还是 GRPO 带来了 DeepSeek 的一夜爆火?-优快云博客、聊聊DeepSeek V3中的混合专家模型(MoE)-优快云博客):
-
后置层归一化(Post-LN):传统Transformer采用后置归一化,即在子层(自注意力和前馈网络)输出之后进行归一化。这种设计可能导致训练初期的梯度不稳定问题,特别是在大型MoE模型中。
-
基于ReLU/GELU的激活函数:标准Transformer通常使用ReLU或GELU作为激活函数,这些函数在专家网络中的表现相对简单直接。
-
绝对位置编码:传统Transformer使用绝对位置编码(如正余弦编码)来表示位置信息,这种编码方式在专家路由中可能无法充分捕捉相对位置关系。
标准Transformer中的专家选择更倾向于依赖局部token信息和绝对位置,而上下文信息主要通过自注意力机制的输出间接影响专家选择(扩展阅读:初探 Transformer-优快云博客)。
LLaMA的专家激活机制创新
LLaMA模型对Transformer架构进行了多项关键改进,这些改进显著影响了专家激活机制:
前置层归一化(Pre-normalization):LLaMA采用前置归一化策略,在每个子层的输入之前进行层归一化。这种设计提高了训练稳定性,特别是在MoE架构中,使得专家门控决策更加可靠。
RMSNorm归一化:LLaMA使用RMSNorm替代传统LayerNorm,这种方法只关注方差而不调整均值,计算更高效且更适合大型MoE模型(扩展阅读:深度学习归一化技术全景解析:从传统方法到RMSNorm的创新演进-优快云博客、为什么Llama选择RMSNorm:LayerNorm的进化与替代逻辑的深度解析-优快云博客)。RMSNorm公式如下:
SwiGLU激活函数:LLaMA将FFN层的激活函数更换为SwiGLU,这是一种基于Swish的GLU变体,提供了更好的梯度流动和更精细的专家门控能力。SwiGLU的表达式为:
旋转位置嵌入(RoPE):LLaMA采用RoPE代替传统位置编码,通过旋转矩阵将位置信息编码到注意力机制中。这使得专家选择能更灵活地考虑相对位置关系。RoPE的关键实现代码如下:
def precompute_freqs_cis(dim: int, end: int, theta: float = 10000.0):
# 预计算频率张量用于复数指数(旋转矩阵)
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
t = torch.arange(end, device=freqs.device) # 位置序列
freqs = torch.outer(t, freqs).float() # 外积得到位置*频率矩阵
freqs_cis = torch.polar(torch.ones_like(freqs), freqs) # 转为复数形式
return freqs_cis代码说明:这段代码展示了RoPE位置编码的预计算过程,通过将位置信息编码为旋转矩阵,使模型能够更有效地捕捉序列元素间的位置关系,进而影响专家选择。
关键差异对比表
| 特性 | 标准Transformer | LLaMA | 对专家激活的影响 |
|---|---|---|---|
| 归一化方式 | 后置归一化(Post-LN) | 前置归一化(Pre-LN) | LLaMA训练更稳定,专家门控更可靠 |
| 归一化函数 | LayerNorm | RMSNorm | LLaMA计算更高效,适合大规模专家网络 |
| 激活函数 | ReLU/GELU | SwiGLU | LLaMA专家门控更精细,表达能力更强 |
| 位置编码 | 绝对位置编码 | 旋转位置嵌入(RoPE) | LLaMA能更好处理相对位置,影响专家选择 |
| 注意力机制 | 标准多头注意力 | Grouped Query Attention | LLaMA计算效率更高,可支持更多专家 |
表格说明:此表总结了标准Transformer与LLaMA在关键架构上的差异,以及这些差异对专家激活机制的影响。
生活化案例解释:想象标准Transformer和LLaMA就像两家不同的快递公司。标准Transformer像一家使用固定路线的传统公司,快递员(专家)按照固定区域分配包裹(token),不考虑实时交通状况(上下文)。而LLaMA像一家智能物流公司,使用实时GPS数据(RoPE)、智能分拣系统(SwiGLU)和动态路线优化(Pre-LN),根据包裹内容、目的地和当前交通状况,动态选择最合适的快递员和最优路线,大幅提高了配送效率。
专家激活的实践挑战与解决方案
训练不稳定性与专家负载均衡
MoE模型虽然高效,但在训练过程中面临诸多挑战,首当其冲的便是训练不稳定性问题。由于每个输入样本仅触发部分专家(Top-k),导致不同专家的梯度更新频率不均衡。这种不平衡可能导致:
-
专家过度专门化:某些专家被频繁选择,成为“热门专家”,而其他专家则很少被激活,造成资源浪费。
-
梯度更新不一致:热门专家获得更多梯度更新,进步更快,而冷门专家则进步缓慢,形成马太效应。
解决方案包括:
-
负载均衡损失:在训练目标中添加额外的损失项,鼓励各专家的使用频率均匀分布:
其中表示变异系数,
是平衡超参数。
-
噪声门控:在门控网络中添加可调节的噪声,增加探索性,防止过早收敛到少数专家。如Noisy Top-k Gating机制:
其中 是可控噪声。
class NoisyTopKRouter(nn.Module):
def __init__(self, dim, num_experts, top_k=2, noise_std=0.01):
super().__init__()
self.top_k = top_k
self.noise_std = noise_std
self.gate = nn.Linear(dim, num_experts)
def forward(self, x):
logits = self.gate(x)
if self.training: # 只在训练时添加噪声
noise = torch.randn_like(logits) * self.noise_std
logits = logits + noise
top_k_logits, top_k_indices = logits.topk(self.top_k, dim=-1)
top_k_gates = torch.softmax(top_k_logits, dim=-1)
# 计算负载均衡损失
expert_counts = torch.bincount(
top_k_indices.flatten(),
minlength=self.gate.out_features
).float()
balance_loss = torch.var(expert_counts) / (torch.mean(expert_counts)**2 + 1e-10)
gates = torch.zeros_like(logits).scatter_(
-1, top_k_indices, top_k_gates
)
return gates, top_k_indices, balance_loss代码说明:这个NoisyTopK路由器实现增加了噪声和负载均衡机制。噪声在训练时添加,促进探索;负载均衡损失鼓励均匀使用专家,防止专家过度专门化。
显存与计算资源管理
MoE模型的另一个关键挑战是显存需求。虽然计算时只激活部分专家,但所有专家都需要加载到内存中,这对硬件提出了更高要求。例如,一个拥有数千专家的MoE层可能需要数百GB的显存。
解决方案包括:
-
专家分片(Expert Sharding):将专家分布在不同设备上,通过分布式计算降低单设备显存需求。
-
专家缓存:根据专家使用频率,将热门专家常驻显存,冷门专家存储在主机内存或SSD中,按需加载。
-
梯度检查点:在训练时只保留部分中间结果,通过重计算减少显存占用。
以下图示展示了专家分片策略:
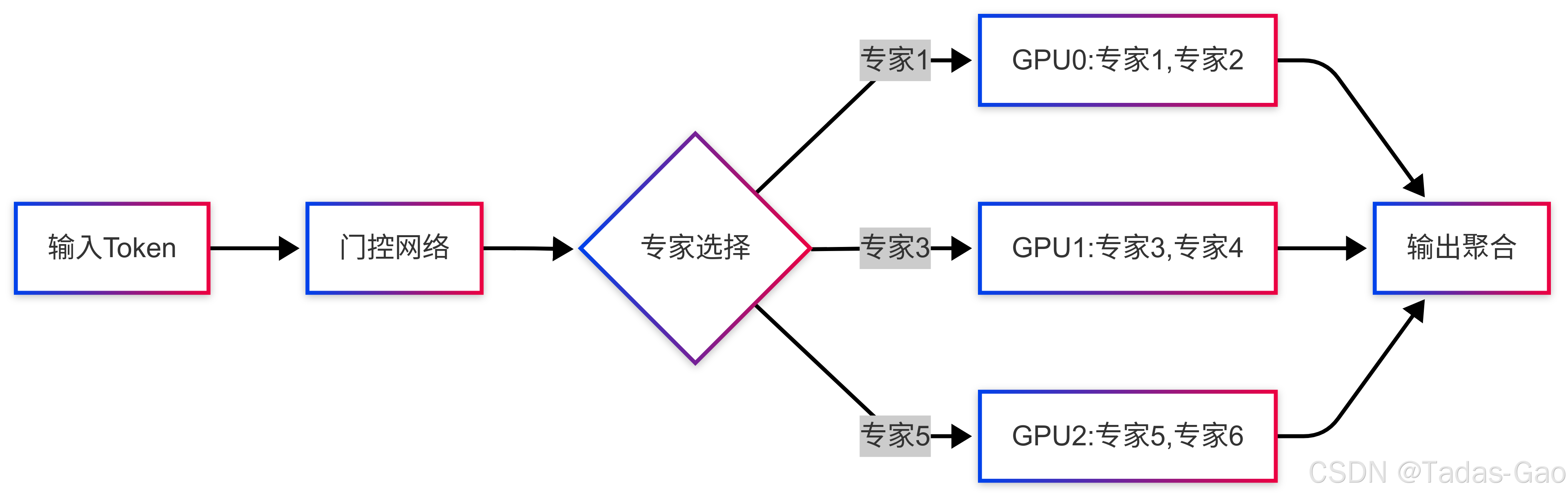
图表说明:该图展示了如何将不同专家分布在不同GPU设备上,通过分片策略降低单设备显存需求,同时通过聚合网络合并各设备的输出结果。
生活化案例解释:MoE模型的显存管理就像一家大型医院的专科门诊系统。所有专科(专家)的设备和药品(参数)都需要准备就绪,但不可能全部同时运转(激活)。医院(模型)根据患者(token)症状,动态调度相应的专科医生(专家)接诊,其他专科则处于待命状态。为了优化资源,医院将不同专科分布在不同楼层(设备),并建立高效的转诊系统(分布式通信),确保资源利用率最大化。
实际应用案例分析
行业应用:谷歌Gemini与Mixtral的MoE实现
谷歌Gemini 1.5采用了混合专家(MoE)架构,使其在训练和服务方面更加高效。Gemini将请求路由到一组较小的“专家”神经网络,因此响应更快且质量更高。这种设计使得Gemini 1.5 Pro(中型多模态模型)能够达到与1.0 Ultra相当的性能,同时保持更高的计算效率。
Mixtral 8x7B则采用稀疏混合专家(SMoE)架构,每一层由八个前馈模块(专家)组成。对于每个token,在每一层中,路由网络选择两个专家处理当前状态并合并它们的输出。这种设计使得模型虽然拥有470亿参数,但推理期间仅使用130亿活跃参数,实现了高效计算。
# Mixtral风格的MoE层实现示例
class MixtralMoELayer(nn.Module):
def __init__(self, dim, num_experts=8, expert_capacity=64):
super().__init__()
self.num_experts = num_experts
self.expert_capacity = expert_capacity # 每个专家处理的token数上限
# 初始化多个专家网络
self.experts = nn.ModuleList([
nn.Sequential(
nn.Linear(dim, dim * 2),
SwiGLU(), # 使用SwiGLU激活
nn.Linear(dim, dim)
) for _ in range(num_experts)]
self.router = NoisyTopKRouter(dim, num_experts, top_k=2)
def forward(self, x):
batch_size, seq_len, hidden_dim = x.shape
x = x.view(-1, hidden_dim) # 展平batch和sequence维度
# 获取门控权重和专家选择
gates, indices, balance_loss = self.router(x)
# 初始化最终输出
final_output = torch.zeros_like(x)
# 处理每个专家
for expert_idx in range(self.num_experts):
# 获取选择当前专家的token索引
expert_mask = (indices == expert_idx).any(dim=-1)
num_tokens = expert_mask.sum().item()
if num_tokens == 0:
continue
# 确保不超过专家容量
if num_tokens > self.expert_capacity:
# 按门控权重排序,选择top-k
_, topk_indices = gates[expert_mask][:, expert_idx].topk(
self.expert_capacity
)
expert_mask[expert_mask] = topk_indices # 更新mask
num_tokens = self.expert_capacity
# 获取当前专家的输入
expert_input = x[expert_mask]
# 专家处理
expert_output = self.experts[expert_idx](expert_input)
# 加权输出
expert_gates = gates[expert_mask, expert_idx].unsqueeze(-1)
weighted_output = expert_output * expert_gates
# 累加到最终输出
final_output[expert_mask] += weighted_output
# 恢复原始形状并返回
return final_output.view(batch_size, seq_len, hidden_dim), balance_loss代码说明:这个Mixtral风格的MoE层实现展示了如何处理动态专家选择、专家容量限制和负载均衡。关键点包括:使用SwiGLU激活的专家网络、NoisyTopK路由器、专家容量控制机制,以及门控加权的输出聚合。
微调实践:LLaMA的MoE微调策略
LLaMA模型的微调需要特别考虑其架构特性。以下是在AWS上微调LLaMA 2模型的示例代码,展示了如何结合MoE特性进行高效微调:
import os
import boto3
from sagemaker.session import Session
from sagemaker.jumpstart.estimator import JumpStartEstimator
# 选择模型版本(7B/13B/70B)
model_id = "meta-textgeneration-llama-2-7b"
# 初始化估计器
estimator = JumpStartEstimator(
model_id=model_id,
environment={"accept_eula": "true"}, # 接受使用协议
instance_type="ml.g5.12xlarge", # 使用配备A10G GPU的实例
role=os.environ["SAGEMAKER_ROLE"] # IAM角色
)
# 设置超参数
estimator.set_hyperparameters(
instruction_tuned="True", # 启用指令调优
epoch="5", # 训练轮数
learning_rate="5e-5", # 学习率
moe_expert_count="8", # 每层专家数
moe_top_k="2", # 每个token使用的专家数
moe_balance_loss_weight="0.01" # 负载均衡损失权重
)
# 启动训练
estimator.fit({
"training": "s3://my-bucket/train-data/",
"validation": "s3://my-bucket/val-data/"
})
# 部署微调后的模型
predictor = estimator.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge"
)代码说明:这段AWS SageMaker代码展示了如何在云端微调LLaMA 2 MoE模型。关键设置包括:指定专家数量和top-k值、配置负载均衡损失、选择合适的实例类型等。指令调优(instruction_tuned)特别适合MoE模型,因为它可以帮助专家更好地适应特定任务。
未来发展方向与结论
MoE架构的演进趋势
混合专家模型作为大语言模型高效化的重要路径,未来可能在以下方向继续演进:
-
分层专家结构:当前专家通常为简单前馈网络,未来可能出现更复杂的层级专家结构,如专家本身也是MoE模型,形成深度专家层次。
-
动态专家数量:根据输入复杂度动态调整激活专家数量,而非固定Top-k,实现更精细的计算-精度权衡。
-
多模态专家:专家不仅处理语言,还可能专门处理视觉、听觉等不同模态信息,如Google Gemini已开始探索这一方向。
-
专家-任务对齐:通过更精细的提示工程和指令微调,使特定专家与特定任务对齐,提升任务专用性。
-
知识增强专家:将外部知识图谱与专家选择机制结合,如国网湖北电力研发的知识图谱增强专家信息检索技术,可提升专家在垂直领域的表现。
实践建议与总结
基于本文分析,为大模型架构师提供以下实践建议:
架构选择:
-
对于高吞吐量、多设备场景,MoE架构是理想选择
-
在显存有限的低吞吐量场景中,稠密模型可能更合适
-
考虑LLaMA的改进架构(Pre-LN、RMSNorm、SwiGLU、RoPE)以获得更稳定的专家路由
专家配置:
-
专家数量在256-512之间可能达到收益递减点
-
Top-k通常选择1-2个专家平衡计算与性能
-
使用噪声门控和负载均衡损失防止专家退化
训练策略:
-
采用渐进式训练,初期使用较小k值,后期逐步增加
-
结合指令微调帮助专家专业化
-
监控各专家使用频率,避免资源浪费
部署优化:
-
实施专家分片充分利用分布式资源
-
考虑专家缓存策略优化显存使用
-
对高频查询实现专家预热
总结而言,大模型中的专家激活机制是一门平衡艺术——在计算效率与模型性能、专家专业化与泛化能力、资源分配与负载均衡之间寻求最优解。Transformer与LLaMA的不同选择反映了这一领域的持续创新,而理解这些差异是设计高效MoE系统的关键。随着AI应用场景的不断扩展,如百度文心智能体平台所展示的,专家混合技术将继续演进,为多样化、个性化的智能服务提供强大支持。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









