 LSTNet:深度学习时间序列预测
LSTNet:深度学习时间序列预测








代码
https://github.com/laiguokun/LSTNet
论文
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks.
LSTNet
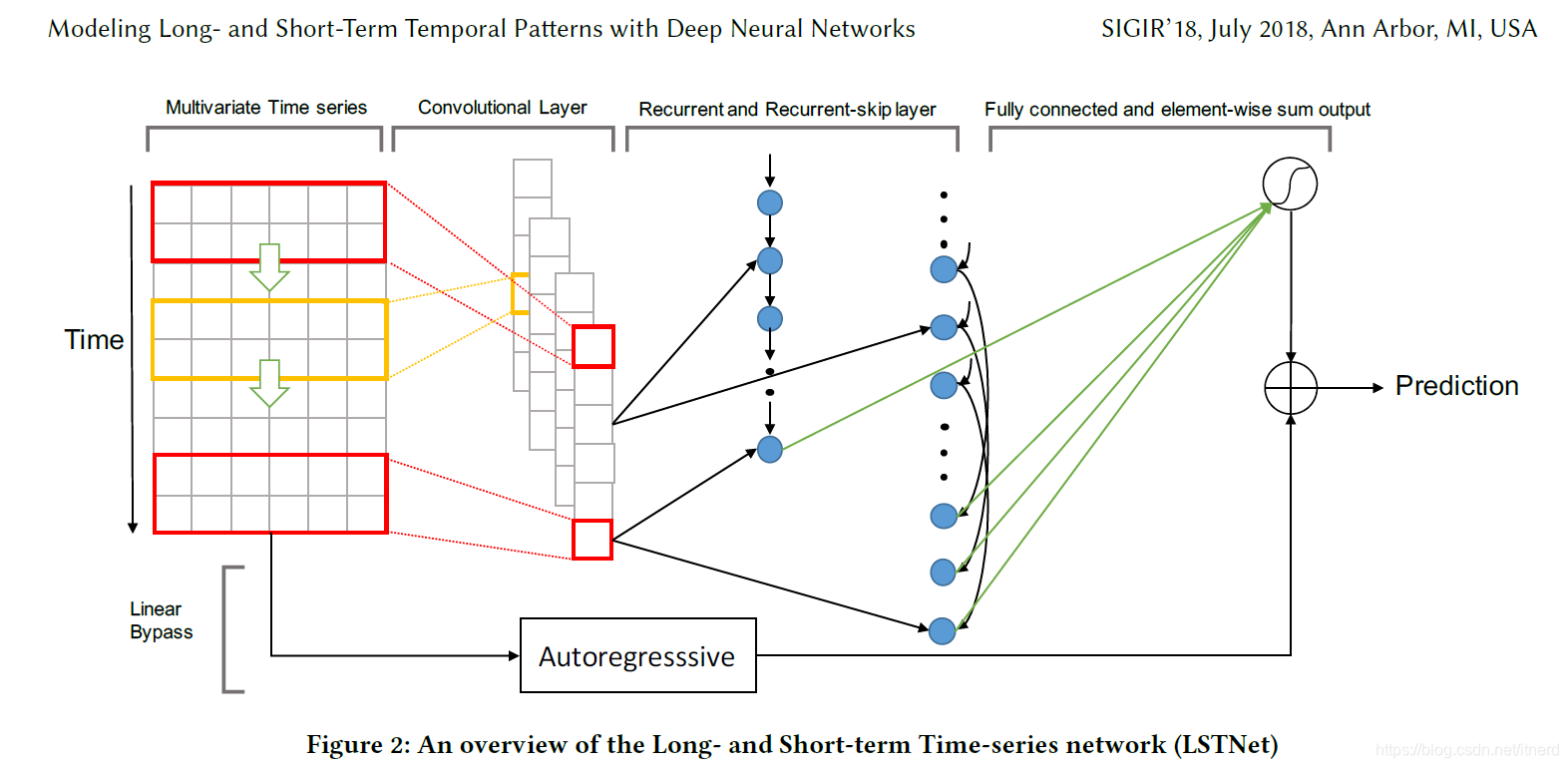
部分参数解释
| 参数 | 默认值 | 解释 |
|---|---|---|
| model(str) | ‘LSTNet’ | |
| hidCNN(int) | 100 | number of CNN hidden units |
| hidRNN(int) | 100 | number of RNN hidden units |
| window(int) | 24 * 7 | window size |
| CNN_kernel(int) | 6 | the kernel size of the CNN layers |
| highway_window(int) | 24 | The window size of the highway component |
| clip(float) | 10. | gradient clipping |
| epochs(int) | 100 | upper epoch limit |
| batch_size(int) | 32 | batch size |
| dropout(float) | 0.2 | dropout applied to layers (0 = no dropout) |
| seed(int) | 54321 | random seed |
| gpu(int) | None | |
| log_interval(int) | 2000 | report interval |
| save(str) | ‘model/model.pt’ | path to save the final model |
| cuda(str) | True | |
| optim(str) | ‘adam’ | |
| lr(float) | 0.001 | |
| horizon(int) | 12 | |
| skip(float) | 24 | |
| hidSkip(int) | 5 | |
| L1Loss(bool) | True | |
| normalize(int) | 2 | |
| output_fun(str) | ‘sigmoid’ |
model
这是作者提供的
import torch
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self, args, data):
super(Model, self).__init__()
self.use_cuda = args.cuda
self.P = args.window # 输入窗口大小
self.m = data.m # 列数,变量数
self.hidR = args.hidRNN
self.hidC = args.hidCNN # 卷积核数
self.hidS = args.hidSkip
self.Ck = args.CNN_kernel # 卷积核大小
self.skip = args.skip;
self.pt = (self.P - self.Ck)//self.skip
self.hw = args.highway_window
self.conv1 = nn.Conv2d(1, self.hidC, kernel_size = (self.Ck, self.m));
self.GRU1 = nn.GRU(self.hidC, self.hidR);
self.dropout = nn.Dropout(p = args.dropout);
if (self.skip > 0):
self.GRUskip = nn.GRU(self.hidC, self.hidS);
self.linear1 = nn.Linear(self.hidR + self.skip * self.hidS, self.m);
else:
self.linear1 = nn.Linear(self.hidR, self.m);
if (self.hw > 0):
self.highway = nn.Linear(self.hw, 1);
self.output = None;
if (args.output_fun == 'sigmoid'):
self.output = F.sigmoid;
if (args.output_fun == 'tanh'):
self.output = F.tanh;
def forward(self, x):
batch_size = x.size(0); # x: [batch, window, n_val]
# CNN
c = x.view(-1, 1, self.P, self.m) # c: [batch, 1, window, n_val]
c = F.relu(self.conv1(c)) # c: [batch, hidCNN, window-kernelsize+1, 1]
c = self.dropout(c)
c = torch.squeeze(c, 3) # c: [batch, hidCNN, window-kernelsize+1]
# RNN
r = c.permute(2, 0, 1).contiguous() # c: [window-kernelsize+1, batch, hidCNN]
_, r = self.GRU1(r) # r: [1, batch, hidRNN]
r = self.dropout(torch.squeeze(r,0)) # r: [batch, hidRNN]
# skip-rnn
if (self.skip > 0):
s = c[:,:, int(-self.pt * self.skip):].contiguous() # s: [batch, hidCNN, pt*skip]
s = s.view(batch_size, self.hidC, self.pt, self.skip) # s: [batch, hidCNN, pt, skip]
s = s.permute(2,0,3,1).contiguous() # s: [pt, batch, skip, hidCNN]
s = s.view(self.pt, batch_size * self.skip, self.hidC) # s: [pt, batch * skip, hidCNN]
_, s = self.GRUskip(s) # s: [1, batch * skip, hidSkip]
s = s.view(batch_size, self.skip * self.hidS) # s: [batch, skip * hidSkip]
s = self.dropout(s)
r = torch.cat((r,s),1) # r: [batch, skip * hidSkip + hidRNN]
res = self.linear1(r) # res: [batch, n_val]
# highway
if (self.hw > 0):
z = x[:, -self.hw:, :] # z: [batch, hw, n_val]
z = z.permute(0,2,1).contiguous().view(-1, self.hw) # z: [batch*n_val, hw]
z = self.highway(z) # z: [batch*n_val, 1]
z = z.view(-1,self.m) # z: [batch, n_val]
res = res + z # res: [batch, n_val]
if (self.output):
res = self.output(res)
return res
代码中用到 GRU 作为 RNN 单元
r
=
σ
(
W
i
r
x
+
b
i
r
+
W
h
r
h
+
b
h
r
)
z
=
σ
(
W
i
z
x
+
b
i
z
+
W
h
z
h
+
b
h
z
)
n
=
tanh
(
W
i
n
x
+
b
i
n
+
r
∗
(
W
h
n
h
+
b
h
n
)
)
h
′
=
(
1
−
z
)
∗
n
+
z
∗
h
\begin{array}{ll} r = \sigma(W_{ir} x + b_{ir} + W_{hr} h + b_{hr}) \\ z = \sigma(W_{iz} x + b_{iz} + W_{hz} h + b_{hz}) \\ n = \tanh(W_{in} x + b_{in} + r * (W_{hn} h + b_{hn})) \\ h' = (1 - z) * n + z * h \end{array}
r=σ(Wirx+bir+Whrh+bhr)z=σ(Wizx+biz+Whzh+bhz)n=tanh(Winx+bin+r∗(Whnh+bhn))h′=(1−z)∗n+z∗h
Inputs: input,
h
0
h_0
h0
- input of shape
(seq_len, batch, input_size): tensor containing the features of the input sequence. The input can also be a packed variable length sequence. - h_0 of shape
(num_layers * num_directions, batch, hidden_size): tensor containing the initial hidden state for each element in the batch. Defaults to zero if not provided. If the RNN is bidirectional, num_directions should be 2, else it should be 1.
Outputs: output, h n h_n hn
- output of shape
(seq_len, batch, num_directions * hidden_size): tensor containing the output features h_t from the last layer of the GRU, for each t. If a :class:torch.nn.utils.rnn.PackedSequencehas been given as the input, the output will also be a packed sequence. For the unpacked case, the directions can be separated usingoutput.view(seq_len, batch, num_directions, hidden_size), with forward and backward being direction0and1respectively.
Similarly, the directions can be separated in the packed case.
- h_n of shape
(num_layers * num_directions, batch, hidden_size): tensor containing the hidden state fort = seq_len
Like output, the layers can be separated using h_n.view(num_layers, num_directions, batch, hidden_size).
在 代码中,只用到了输出的状态 h n h_n hn


















 1317
1317





 到【灌水乐园】发言
到【灌水乐园】发言









