




数据
df.to_csv('traffic1.txt', header=None, index=None)
df

数据为每小时记录一次的交通流量数据,每周有几天出现早高峰。
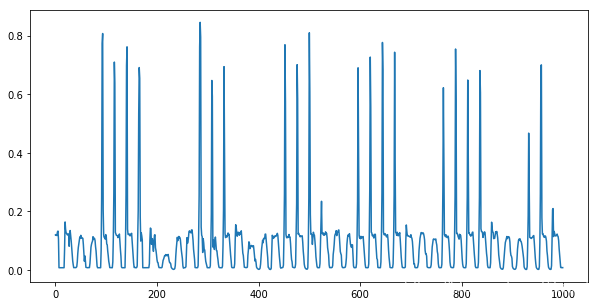
dataset
import torch
import numpy as np;
from torch.autograd import Variable
def normal_std(x):
return x.std() * np.sqrt((len(x) - 1.)/(len(x)))
class Data_utility(object):
# train and valid is the ratio of training set and validation set. test = 1 - train - valid
def __init__(self, file_name, train, valid, cuda, horizon, window, normalize = 2):
self.cuda = cuda;
self.P = window;
self.h = horizon
fin = open(file_name);
self.rawdat = np.loadtxt(fin,delimiter=',')
if(len(self.rawdat.shape)) == 1:
self.rawdat = self.rawdat.reshape(len(self.rawdat), -1)
self.dat = np.zeros(self.rawdat.shape)
self.n, self.m = self.dat.shape;
self.normalize = 2
self.scale = np.ones(self.m);
self._normalized(normalize);
self._split(int(train * self.n), int((train+valid) * self.n), self.n);
self.scale = torch.from_numpy(self.scale).float();
tmp = self.test[1] * self.scale.expand(self.test[1].size(0), self.m);
if self.cuda:
self.scale = self.scale.cuda();
self.scale = Variable(self.scale);
self.rse = normal_std(tmp);
self.rae = torch.mean(torch.abs(tmp - torch.mean(tmp)));
def _normalized(self, normalize):
#normalized by the maximum value of entire matrix.
if (normalize == 0):
self.dat = self.rawdat
if (normalize == 1):
self.dat = self.rawdat / np.max(self.rawdat);
#normlized by the maximum value of each row(sensor).
if (normalize == 2):
for i in range(self.m):
self.scale[i] = np.max(np.abs(self.rawdat[:,i]));
self.dat[:,i] = self.rawdat[:,i] / np.max(np.abs(self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 234
234










 到【灌水乐园】发言
到【灌水乐园】发言









