







 超级会员免费看
超级会员免费看
 本文详细记录了使用Scrapy框架创建MaoyanCrawler项目,爬取猫眼电影TOP100榜单的过程。内容包括创建项目、生成爬虫框架、分析网址规律、获取电影信息、定义数据字段、处理数据并存储至CSV和MySQL数据库。爬取信息包含电影名称、主演和上映时间,同时处理了猫眼验证问题。
本文详细记录了使用Scrapy框架创建MaoyanCrawler项目,爬取猫眼电影TOP100榜单的过程。内容包括创建项目、生成爬虫框架、分析网址规律、获取电影信息、定义数据字段、处理数据并存储至CSV和MySQL数据库。爬取信息包含电影名称、主演和上映时间,同时处理了猫眼验证问题。
文章目录
一、提出任务
猫眼电影TOP100榜(https://maoyan.com/board/4)总共有10页共100部电影,如下图所示:

- 创建Scrapy框架,用于抓取猫眼电影TOP100榜电影
- 要抓取的信息包括电影名称、主演、上映时间
- 数据存入csv文件和MySQL数据库
- 注意:频繁请求会导致美团验证,此时需要在浏览器中进行手动验证
二、实现任务
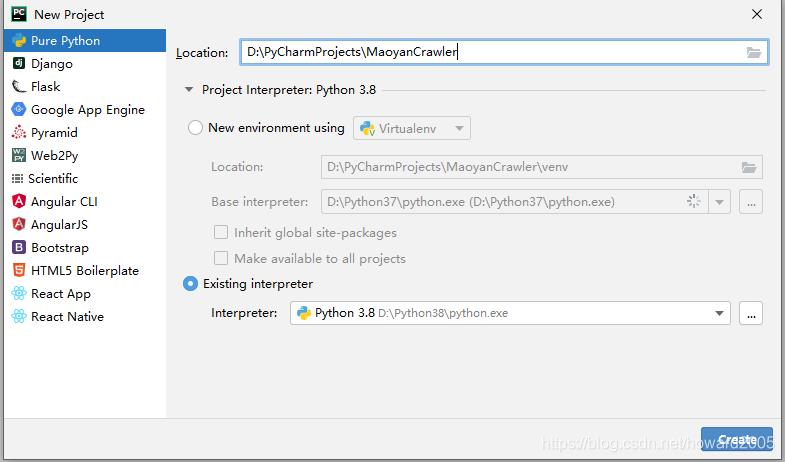
(一)创建PyCharm项目 - MaoyanCrawler
猫眼电影TOP100榜(https://maoyan.com/board/4)总共有10页共100部电影,如下图所示:
 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























