







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Scrapy框架爬取腾讯招聘网的职位信息,详细阐述了从创建Scrapy项目、设置爬虫、解析网页到运行爬虫的全过程。同时,还展示了如何分析数据并生成词云图,包括数据清洗、分词和词云图的制作技巧。
本文介绍了如何使用Scrapy框架爬取腾讯招聘网的职位信息,详细阐述了从创建Scrapy项目、设置爬虫、解析网页到运行爬虫的全过程。同时,还展示了如何分析数据并生成词云图,包括数据清洗、分词和词云图的制作技巧。
文章目录
一、Scrapy框架概述
(一)网络爬虫
- 网络爬虫:在本质上就是模拟用户在浏览器上操作,发送请求,接收响应,然后分析并保存数据,只不过这个过程通过代码实现了大量的自动化操作。

- 爬虫基本流程
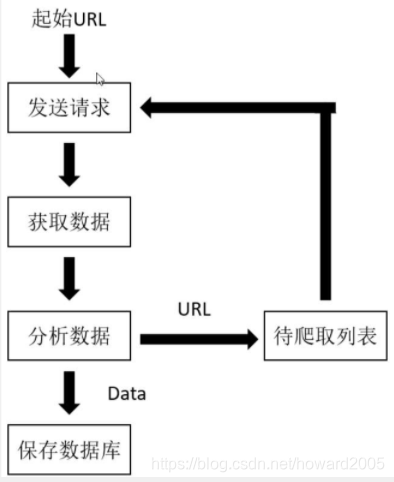
爬虫学习笔记:爬取单张图片
(二)Scrapy框架
- Scrapy是一个使用Python实现的,为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。只需要定制开发几个模块就可以轻松地实现一个爬虫,用来抓取网页内容以及各种图片,非常方便。Scrapy使用了Twisted异步网络框架来处理网络通信,可以加快下载速度,并且包含各种中间件接口,可以灵活地完成各种需求。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











