



基于深度学习的竞赛用行星探测车目标识别
摘要
我们参加了“国际学生卫星火箭发射(ARLISS)”竞赛,该竞赛中各团队设计的行星探测漫游车通过自主控制竞相接近目标。在此竞赛中,各队的探测车利用全球定位系统(GPS)接近目标位置。然而,由于GPS定位误差,它们只能接近到距离目标几米范围内。我们的探测车通过颜色识别放置在目标点的红色交通锥,并在种子岛火箭竞赛2018中成功将探测车控制至距目标0米的位置。但是,基于颜色对目标物体进行图像识别的方法存在因环境光照变化(例如天气变化)而导致识别不稳定的問題。因此,我们尝试采用深度学习来解决这一问题。然而,一般的深度学习模型在小型行星探测漫游车的计算机上运行需要大量的计算时间,因而无法直接应用。为此,我们提出了一种计算时间短且识别精度高的深度学习模型。使用所提出的方法,可在几秒钟内实现超过99%的识别率。此外,我们通过展示采用该方法的探测车的有效性赢得了比赛,从而证明了该方法的有效性。
I. 引言
我们开发了一种原创设计的行星探测车,并参加了“国际学生卫星火箭发射”(ARLISS)[1]比赛。在该比赛中,参赛者需在严苛条件下通过火箭将探测车发射至空中,再利用自主控制技术,比拼探测车行驶至目标位置的接近程度[2]。比赛中,各参赛队伍的探测车通常依靠全球定位系统(GPS)驶向目标位置,但随着逐渐接近目标,探测车会进入GPS定位误差范围。为了实现对探测车的控制,使其能够穿越该误差范围并成功抵达目标,我们开发了一款利用图像识别技术驶向目标的探测车。本次比赛中所使用的探测车通过颜色识别目标处放置的物体,实验观察到我们的探测车能够一直行驶至距离目标0米的位置[3, 4]。然而,基于颜色的目标物体图像识别会因天气等环境光照变化而出现识别精度下降的问题。尽管该问题可通过深度学习解决,但深度学习通常需要大量的计算时间。
小型行星探测车仅能使用计算能力较低的小型计算机,例如树莓派Zero。如果采用视觉几何组(VGG)模型等高精度模型,所需的计算时间会显著增加。因此,我们研究了一种可在几秒钟内执行的模型,并考察其是否具备足够的识别精度。结果发现,即使使用简单的深度学习模型,也能克服传统方法的局限性,实现高速且高识别精度的目标。事实上,在ARLISS2019竞赛中,我们的探测车利用该技术成功行驶至0米处,即精确到达目标位置,并赢得了比赛。
II. 传统方法
在ARLISS及其他行星探测漫游车竞赛中,目标位置会放置一个红色交通锥。为了识别该目标物体,需提取漫游车相机所拍摄图像中的红色部分。此提取过程通过将摄像头捕获的RGB位图数据转换为YCrCb格式来实现。
随后,通过设定与交通锥红色相匹配的YCrCb值范围,生成二值图像。由于仅从生成的二值图像中提取了交通锥的红色部分,因此当被识别为红色的区域大于预先设定的阈值时,即推断已找到交通锥。通过计算二值图像的重心坐标,确定目标在屏幕上的位置。

III. 传统方法存在的问题
在传统方法中,基于颜色来识别表示目标位置的物体。然而,YCrCb参数的值会随着天气变化而变化,例如目标物体表面在直射阳光下的颜色、当时阴影的颜色以及阴天时目标物体表面的颜色。在比赛过程中,由于天气变化导致环境光强度持续改变,因此应将YCrCb参数的范围设置得足够宽以考虑这些变化。但是,如果范围设置过宽,则枯草等非目标物体很可能被误判为目标物体。此外,由于仅通过颜色进行判断,类似红色的物体也可能被错误地判断为目标物体。
IV. 基于深度学习的目标图像识别
A. 提出的方法
使用颜色进行目标物体识别存在上述各种问题。因此,我们提出了一种利用深度学习识别目标物体图像的方法。
B. 深度学习模型结构
我们使用Keras库进行深度学习编程,并以TensorFlow作为后端。
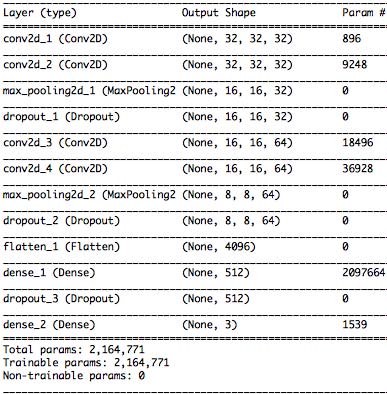
 展示了用于目标物体图像识别的深度学习模型架构。在我们的模型中,输入图像首先经过两个包含32个滤波器的卷积层,分辨率为32 px × 32 px;随后,再经过两个包含64个滤波器的卷积层,分辨率为16 px × 16 px;最后,通过两个全连接层,将图像分类为三种类型。摄像头获取的图像尺寸为320 px × 240 px的三维(RGB)数据,在深度学习训练和识别中被转换为32 px × 32 px的三维(RGB)数据。用于训练深度学习模型的数据包括:约1500张从距离目标0.5到5米处拍摄的图像,约240张用于目标判断的近距离目标图像,以及约1400张不含目标的图像。
展示了用于目标物体图像识别的深度学习模型架构。在我们的模型中,输入图像首先经过两个包含32个滤波器的卷积层,分辨率为32 px × 32 px;随后,再经过两个包含64个滤波器的卷积层,分辨率为16 px × 16 px;最后,通过两个全连接层,将图像分类为三种类型。摄像头获取的图像尺寸为320 px × 240 px的三维(RGB)数据,在深度学习训练和识别中被转换为32 px × 32 px的三维(RGB)数据。用于训练深度学习模型的数据包括:约1500张从距离目标0.5到5米处拍摄的图像,约240张用于目标判断的近距离目标图像,以及约1400张不含目标的图像。
 展示了用于训练的图像示例。图中左侧图像表示目标尚不够近,无法成功判断;中间图像可被判断为属于目标;右侧图像则不包含目标。
展示了用于训练的图像示例。图中左侧图像表示目标尚不够近,无法成功判断;中间图像可被判断为属于目标;右侧图像则不包含目标。
C. 训练我们的深度学习模型
 和
和
 展示了学习曲线的图表,其中前者是识别精度的曲线图,而后者是损失函数的值。图4显示了用于训练的图像的识别精度值,而val_acc表示未用于训练的图像的识别精度值。在图5中,loss表示用于训练的图像的损失函数值,而val_loss表示未用于训练的图像的损失函数值。Epoch表示训练的迭代次数,在本研究中,我们进行了15轮训练。
展示了学习曲线的图表,其中前者是识别精度的曲线图,而后者是损失函数的值。图4显示了用于训练的图像的识别精度值,而val_acc表示未用于训练的图像的识别精度值。在图5中,loss表示用于训练的图像的损失函数值,而val_loss表示未用于训练的图像的损失函数值。Epoch表示训练的迭代次数,在本研究中,我们进行了15轮训练。
基于用于训练的图像数据,分类准确率达到约97%,对于未用于训练的图像则达到约99%。因此,我们的深度学习模型表现出极高的分类准确率。单次图像识别所需的平均计算时间约为0.28秒。
V. 结论
我们开发了一种深度学习技术,以解决基于物体颜色的图像误识别问题。与传统方法不同,通过使用所提出的方法,探测车能够可靠地识别目标,并最终到达距离目标0米的位置,即使在天气变化导致色温变化的情况下也能实现。所提出的模型可在几秒钟内完成快速图像识别。因此,我们的模型识别精度高达约99%。事实上,在ARLISS2019比赛中,使用该方法的探测车成功接近目标至0米距离,并赢得了比赛。由此我们确认了所提出方法的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









