 107个大模型综合能力实测横评排行
107个大模型综合能力实测横评排行





本期汇总各个大模型综合能力的评测数据,综合能力得分类目为:医疗、教育、金融、法律、行政公务、心理健康、推理与数学计算、语言与指令遵从共8个领域得分的平均值。同时,大模型的通用能力、垂直行业应用等领域不同类型、不同阶段、不同维度的评测,都在爆肝输出中,敬请期待。
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
我们的目标是:
通过评测为大家透视化呈现,各个大模型的能力边界,以支持大家高效使用!
以下是本期107个大模型的评测综合得分和排名,以及涉及推理、商用、开源、价格、参数量等不同细分类型和维度的大模型排行榜。目录如下:
一、综合能力排行榜(图)
1.1 推理类模型排行榜(表)
1.2 商用大模型排行榜(含开源模型的付费API)
(1)输出价格30元及以上(表)
(2)输出价格5~30元(表)
(3)输出价格1~5元(表)
(4)输出价格1元以下(表)
1.3 开源大模型排行榜
(1)5B以下(表)
(2)5B~20B(表)
(3)20B以上(表)
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
一、综合能力排行榜(图)
绿色(闭源),蓝色(开源)
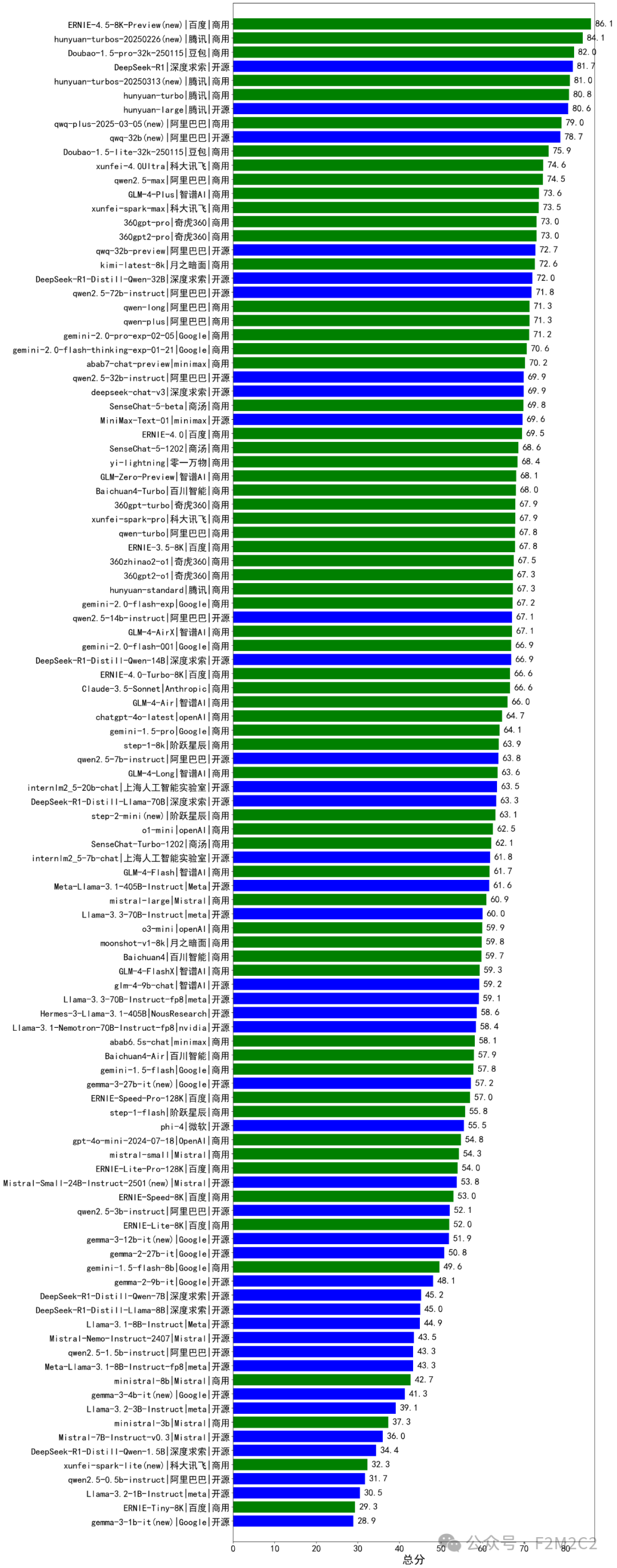
完整评测题集及结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
1.1 推理类模型排行榜
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









