




在评估大语言模型的性能时,一种主流的途径就是选择不同的能力维度并且构建对应的评测任务,进而使用这些能力维度的评测任务对模型的性能进行测试与对比。由大型机构或者研究院所排出榜单。
评测指标
不同评测任务有不同的评指标,衡量模型的能力,也需要使用不同的评测方法。常见评测指标如下:
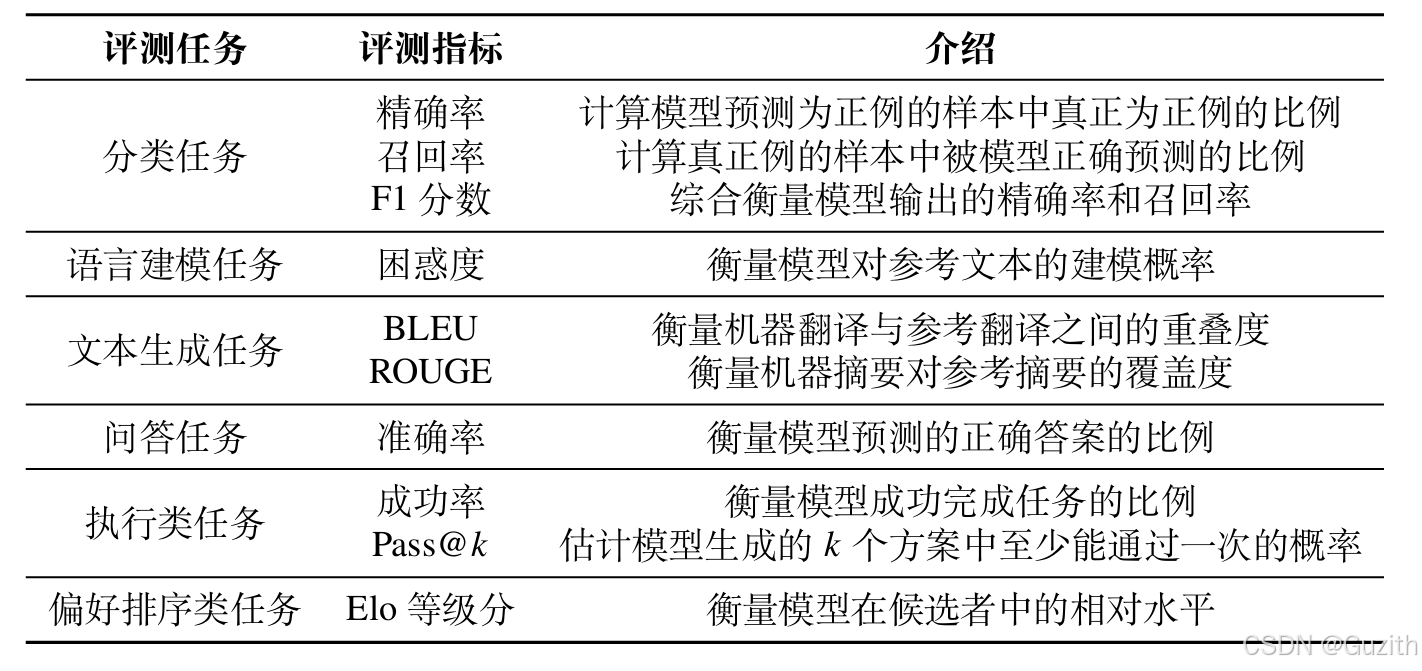
评测方法
根据评测方式及指标的不同,就需要不同评测方法。例如在偏高和排序类任务中,衡量的使用模型在候选者中的相对水平,模型之间做比较,那么就需要人类参与,真人评估。因此针对上述能力维度的评估方法可以分为三种方式:
- 基于评测基准评估
- 基于人类评估
- 基于模型评估
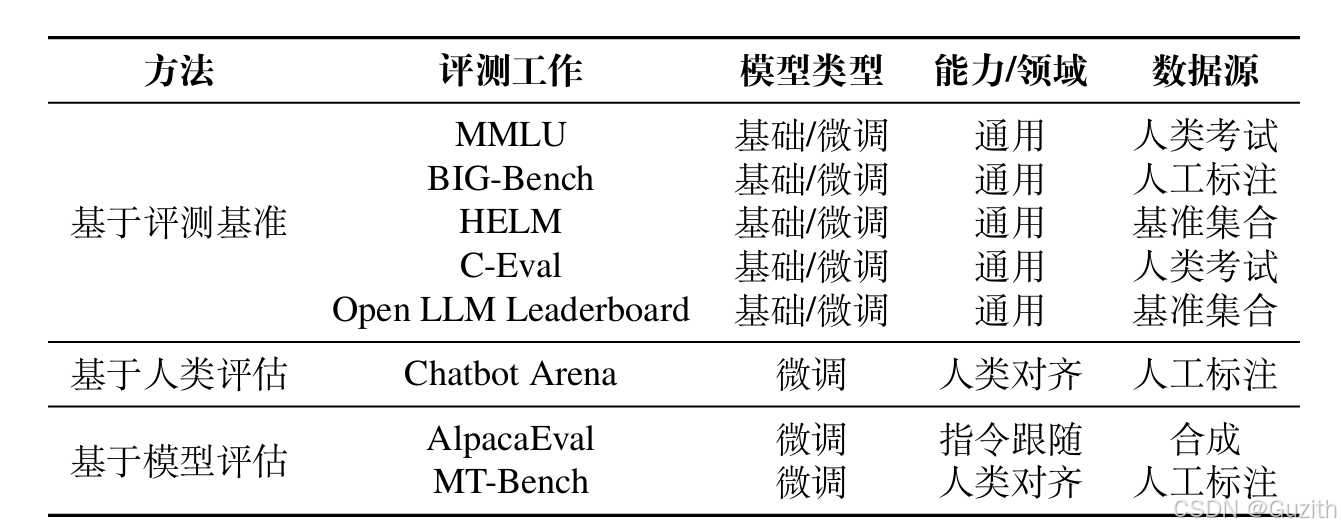
这三种评测方法都有知名的评测榜单。
评测需要考核题目也就是数据集。有面向知识的评测数据集如MMLU、C-Eval侧重于评估大语言模型对现实世界知识的理解和应用;有面向推理的评测数据集如GSM8K、BBH和MATH考察模型在解决复杂推理问题时的表现。此外,一些综合评测体系如OpenCompass平台尝试将这两类评测任务相结合,更全面地评估大语言模型的综合能力。数据集详细介绍可查看大模型评测方法(三)_知识库大模型测试集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3297
3297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









