



【V。❤️】ai-xiao-mi-shu,➡️专业👗,保持与行业前沿同步!!!
近年来,大语言模型(LLM)在专业领域的推理能力成为技术迭代的核心方向。2025年4月15日发布的 Doubao-1.5-thinking-pro 凭借长思维链和强化学习技术,在医疗、教育、金融等8大类别中展现了突出的推理性能。时隔两个月,其升级版 doubao-seed-1-6-thinking-250615 于6月15日正式推出,进一步优化了模型架构。
本文将从 医疗、教育、金融、法律、行政公务、心理健康、推理与数学计算、语言与指令遵从 8个维度,对比新旧版本的性能变化,分析升级模型的优势与潜在改进空间,为技术从业者和行业应用者提供参考。
01 整体分析
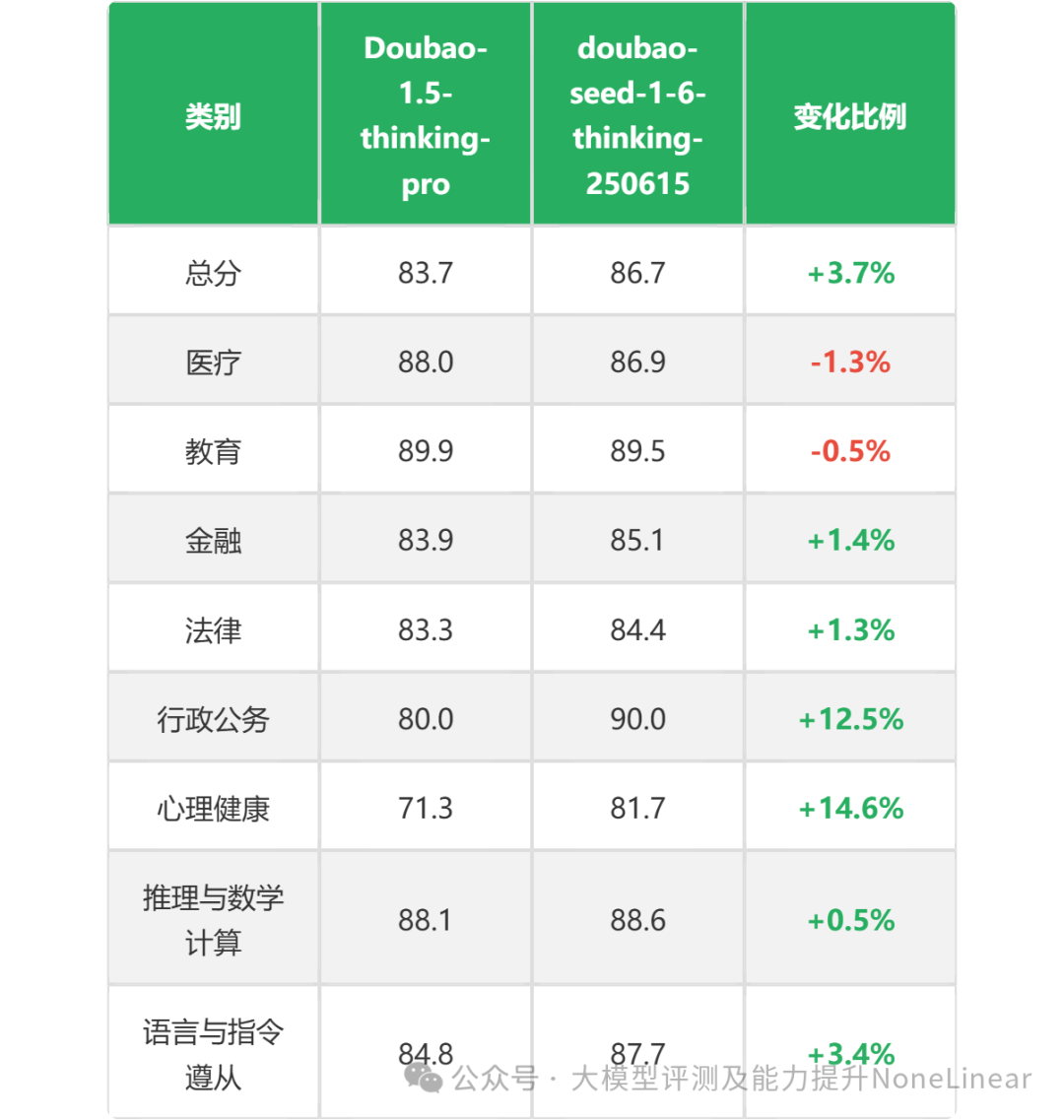
*数据来源:ReLE中文大模型能力评测
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
分析结论:
-
显著提升的类别:
-
行政公务(+12.5%)和 心理健康(+14.6%)提升幅度最大,可能是新版本针对这些领域进行了专项优化。
-
语言与指令遵从(+3.42%)和 总分(+3.66%)也表现较好,说明整体能力增强。
-
金融、法律、推理与数学计算有小幅提升(1%~1.5%)。
-
-
轻微下降的类别:
-
医疗(-1.28%)和 教育(-0.52%)略有退步,可能因模型调整时未优先适配这些领域。
-
总结:新版本在行政公务、心理健康等场景表现突出,总分提升明显,但医疗和教育领域需进一步优化。
02 推理与数学计算
接下来,我们再对“推理与数学计算”做深入分析:
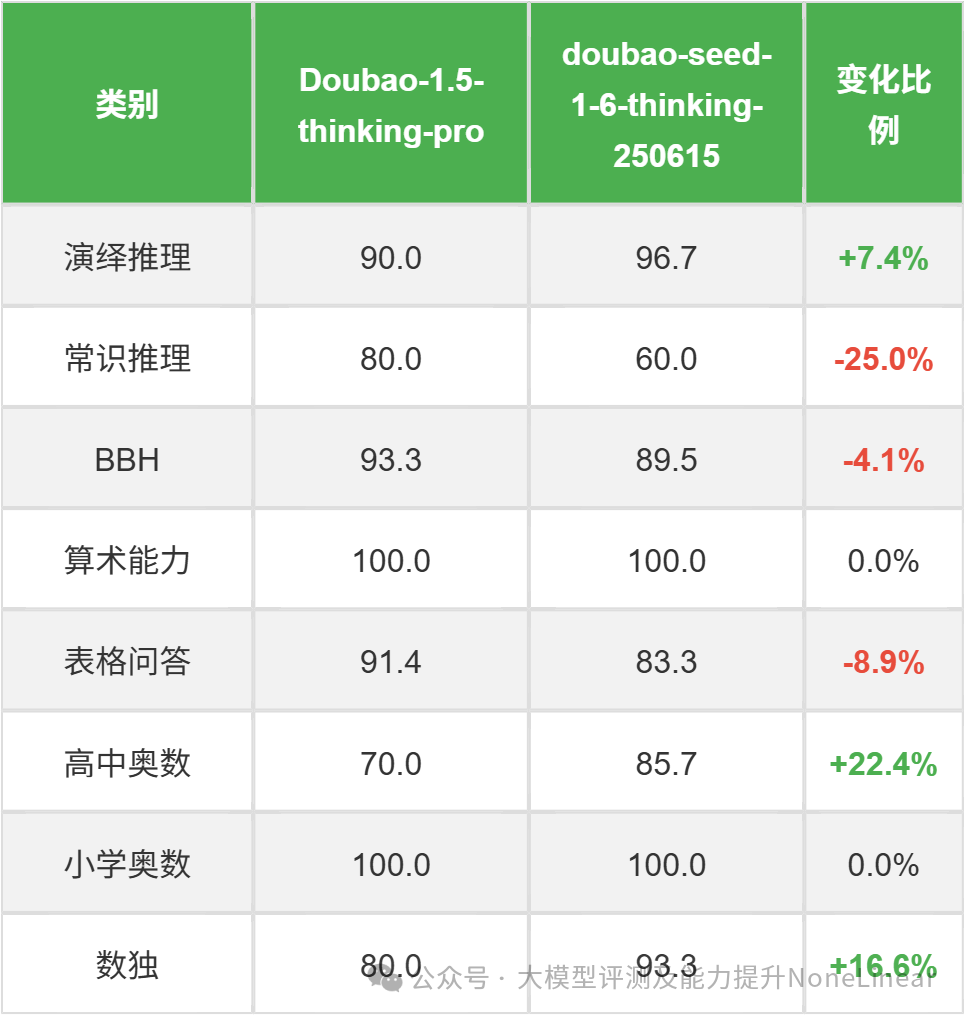
*数据来源:ReLE中文大模型能力评测
更多细分维度结果详见:https://github.com/jeinlee1991/chinese-llm-benchmark
分析结论:
-
显著提高的类别:
-
高中奥数(+22.43%)、演绎推理(+7.44%)、数独(+16.63%)表现明显提升,尤其是高中奥数能力进步突出。
-
小学奥数和算术能力保持满分,未发生变化。
-
-
明显变弱的类别:
-
常识推理(-25.00%)大幅下降,表格问答(-8.86%)和BBH(-4.13%)也有小幅退步。
-
-
可能原因:
-
新版本可能优化了复杂逻辑(如奥数、演绎推理)和结构化问题(如数独)的能力,但牺牲了部分常识关联性任务(常识推理)和表格理解(表格问答)的泛化性。
-
BBH(BIG-Bench Hard)的轻微下降可能反映对复杂多步推理的稳定性略有波动。
-
The end.

















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









