



01
AI大模型「国外五强专题」评测榜单说明
【关于海外五强】上期测了基模五强,国产大模型“基模五强”硬核对决:旗舰性能、领域专精与价格厮杀!今天,我们将聚焦国外Google、OpenAI、Meta、Anthropic、XAI(关注文末说明)这五家海外top机构,通过评测数据解析它们的模型布局策略、价格竞争、旗舰性能以及在各个领域的应用能力。
【评测目标】以评促优、以评促用、以评促享
【评测模型】海外五强文本大模型
【评测集】8大领域、300+维度评估,2025最新题集,低污染度,大模型“闭卷”考试实测;为便于各领域横向对比,本次评分机制细分领域、总分均为为百分制;
【评测方式】海外五强(系列大模型)官方API
【更多评测资讯】https://nonelinear.com
【备注】文中输出价格计算均为¥RMB / Million tokens;即每百万tokens的人民币价格
#关键数据,先睹为快
-
Google
Gemini Pro以84.9分占据教育领域最高分,免费Gemma-3-4b总分38.2分。
-
Meta
Llama-4-Maverick以4.35元成本达成医疗领域77.8分(当前最佳),FP8量化技术使70B模型成本降至2.2元。
-
OpenAI
o4-mini以91分列数学推理首位,法律领域最高分(GPT-4.1)为56.7分。
-
Anthropic
Claude-sonnet-thinking以86分居语言指令领域第一,单价108.75元为四家中最高。
02
AI大模型「国外五强专题」评测关键发现
一、模型布局策略:百花齐放,各有所长
从模型家族的构成来看,四大机构采取了不同的发展路径。
各家模型、输出价格、评分总览
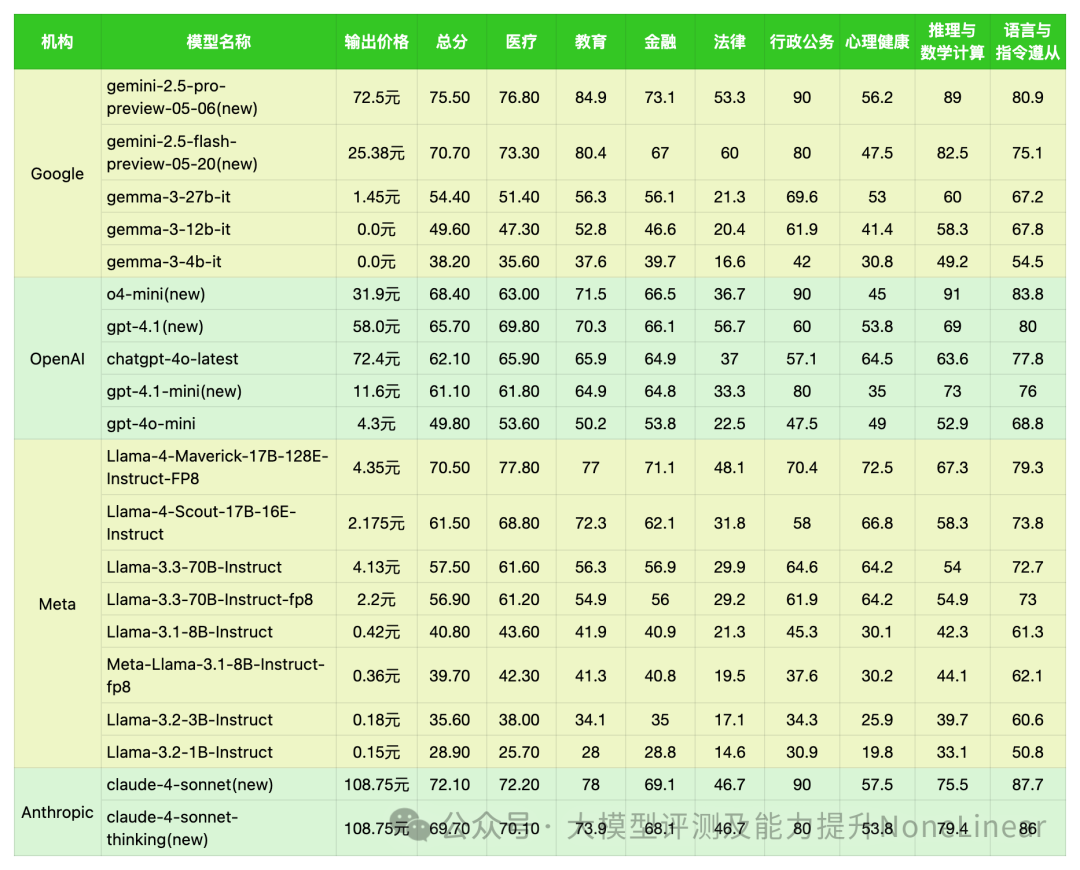
*数据来源:ReLE中文大模型能力评测
#核心结论
- Google
模型策略是典型的“多点开花”。既有定位高端的旗舰模型如
gemini-2.5-pro-preview-05-06(new),又有注重效率和成本的“flash”版本。更值得关注的是其Gemma系列,提供了从27B到4B不同参数规模的模型,甚至包含免费版本。这表明Google致力于覆盖从顶尖科研到轻量级应用的全场景,满足不同用户群体的需求。 - OpenAI
同样采取了多层次布局。除了备受瞩目的
o4-mini(new)、gpt-4.1(new)和chatgpt-4o-latest等旗舰级模型,还推出了更轻量化的“mini”版本。这显示出OpenAI在追求极致性能的同时,也在积极拓展模型的适用范围,努力在性能与资源消耗之间找到平衡点。 - Meta
则以其Llama系列独树一帜。从Maverick、Scout到Llama 3.x系列,Meta的版本迭代清晰可见,并且推出了多个参数规模(如1B、3B、8B、17B、70B)的模型,其中不乏开源或半开源版本。这种策略更强调开放性和社区协作,旨在降低大模型的使用门槛,加速整个生态系统的发展和创新。
- Anthropic
相比之下,Anthropic在表格中仅展示了
claude-4-sonnet系列模型。这或许暗示其倾向于**“精兵策略”**,专注于少数但高质量、高能力的模型研发,可能更侧重于为特定行业或企业级用户提供深度定制和高价值的解决方案。
二、价格竞争:高端与普惠并存
模型价格是用户选择的关键考量,四大机构在定价上呈现出显著差异。
各家模型输出价格总览
(price unit: ¥RMB / Million tokens)
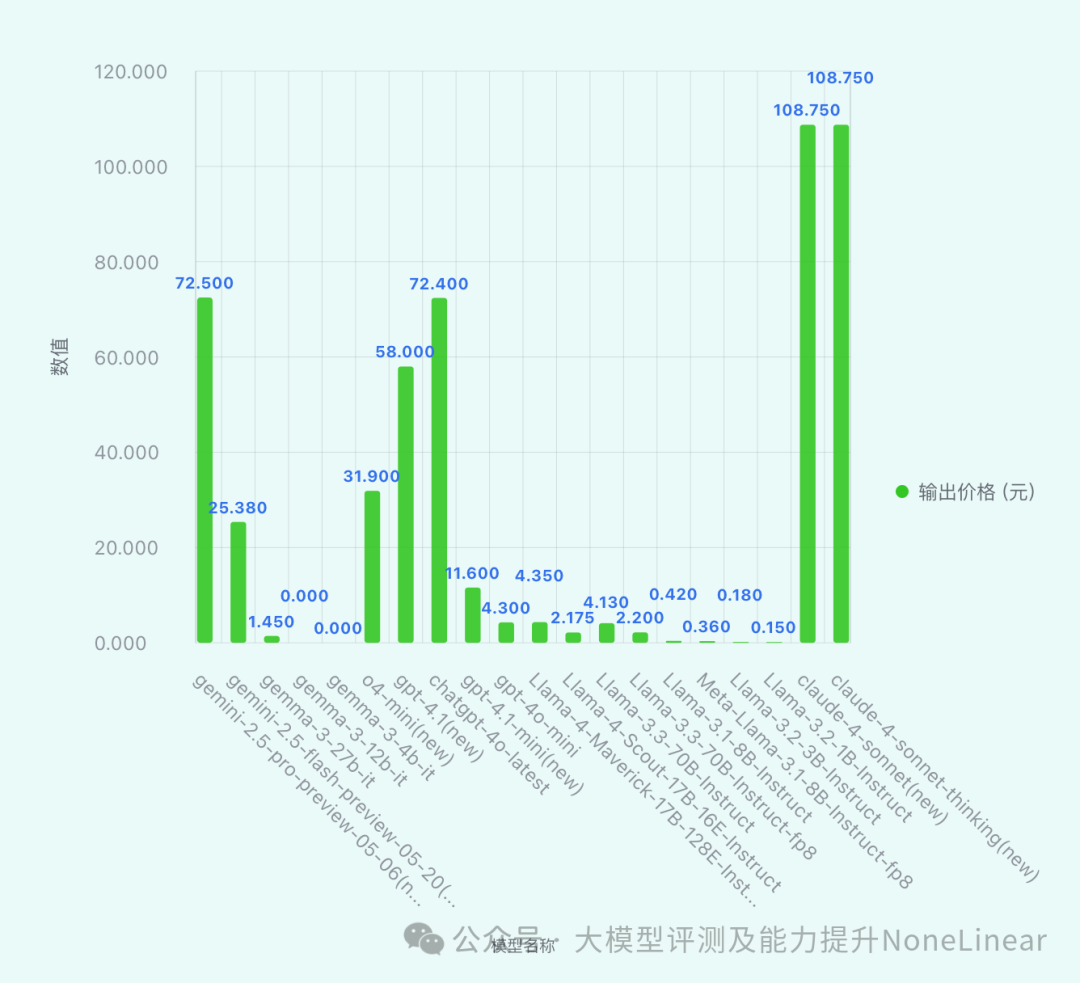
*数据来源:ReLE中文大模型能力评测
#核心结论
- Anthropic
Anthropic的
claude-4-sonnet系列模型以108.75元的输出价格,在这四家机构中位居榜首。这一定价策略表明其产品定位高端,主要面向对性能和可靠性要求极高、对价格敏感度较低的企业级或专业用户。 - Google 与 OpenAI
这两家机构的旗舰模型价格相对较高,如Google的
gemini-2.5-pro-preview-05-06(new)为72.5元,OpenAI的chatgpt-4o-latest为72.4元。这反映了它们在技术研发上的投入和模型的领先地位。然而,两家也提供了价格更低的轻量级或非旗舰模型,例如Google的Gemma系列甚至有免费版本,OpenAI的gpt-4o-mini定价4.3元。这显示出在高端市场竞争的同时,也通过多元定价策略争取更广泛的用户。 - Meta
Meta的Llama系列模型价格普遍较低,旗舰模型
Llama-4-Maverick-17B-128E-Instruct-FP8定价仅为4.35元,许多模型的定价都在几元甚至零元。这与Meta积极推动开源、降低技术门槛的战略高度契合,旨在让更多开发者和研究者能够接触和使用其模型。
三、旗舰性能:Google综合实力领先,OpenAI推理能力突出
旗舰模型代表了各机构的顶尖实力。在总分维度,各家表现如下:
各家旗舰模型、输出价格、评分总览
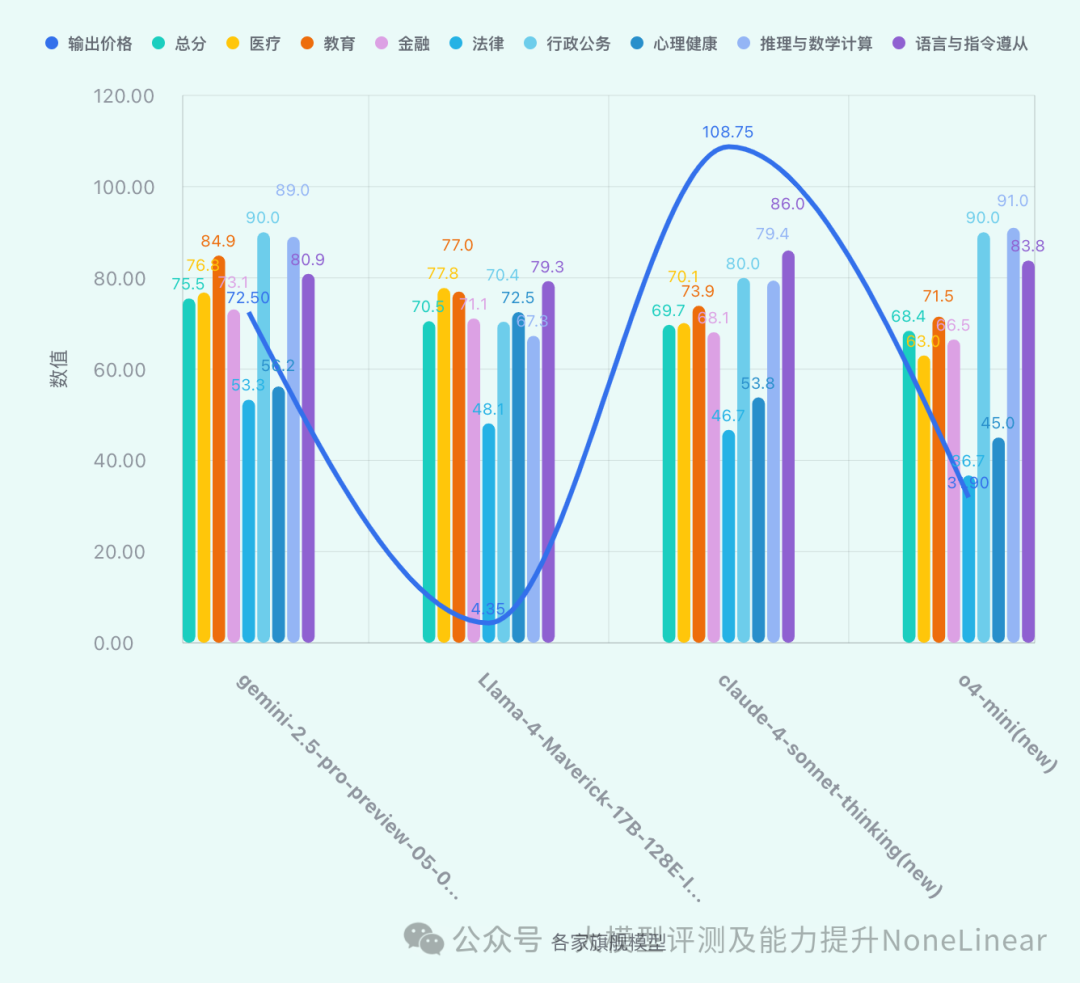
*数据来源:ReLE中文大模型能力评测
#核心结论
- Google的
gemini-2.5-pro-preview-05-06(new)以75.5的总分,在四家机构的旗舰模型中名列第一**。这表明Google在模型综合能力上具有领先优势。 -
Anthropic的
claude-4-sonnet(new)以72.1的总分紧随其后。 -
Meta的
Llama-4-Maverick-17B-128E-Instruct-FP8总分为70.5。 -
OpenAI的
o4-mini(new)总分为68.4。
虽然总分有高低,但具体到各个领域,各家旗舰模型的侧重点和优势则更加明显。
四、领域应用能力:各有千秋,深耕细分赛道
大模型能力的最终体现是其在实际应用场景中的表现。
各应用领域Top3排名总览
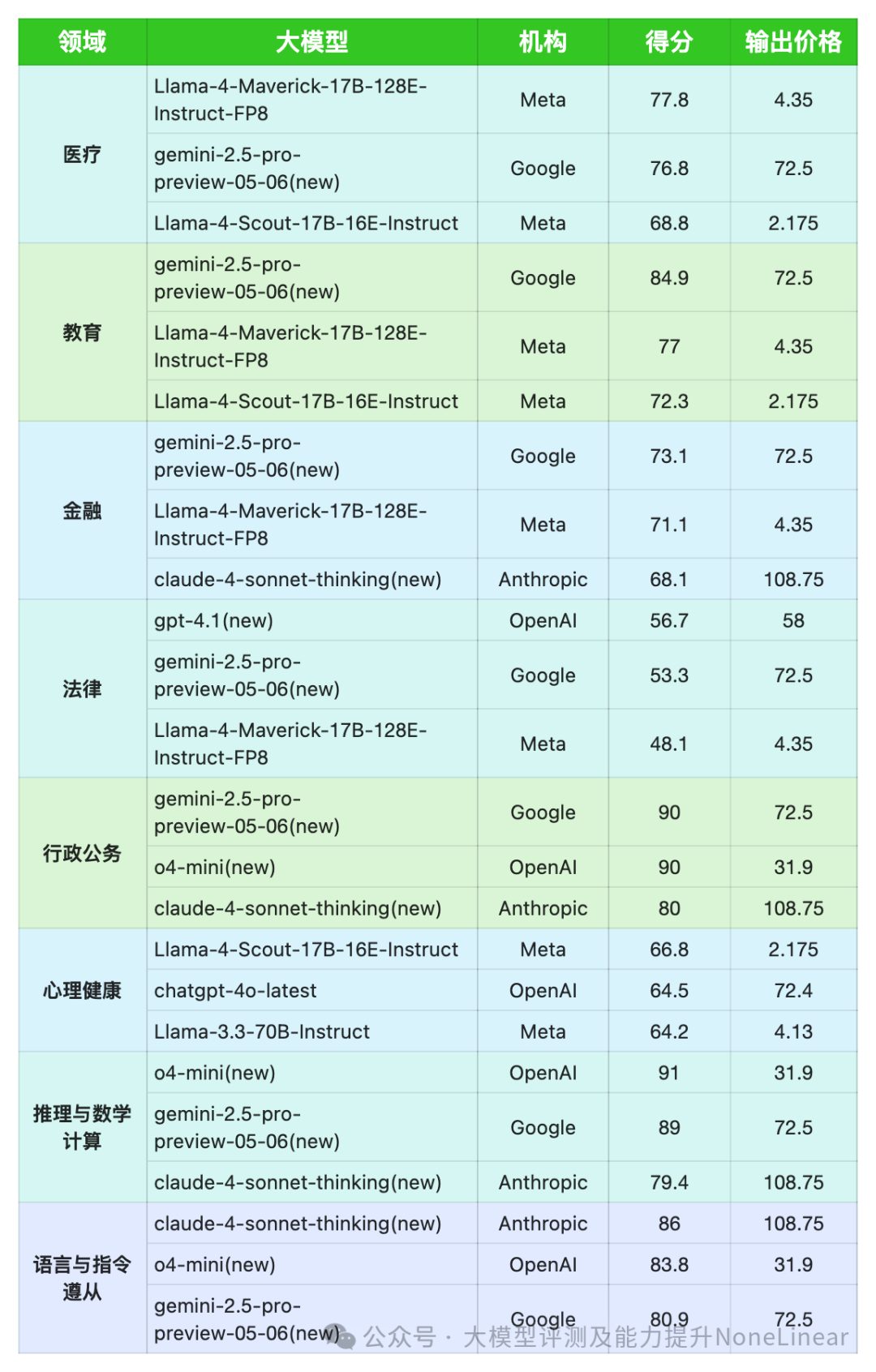
*数据来源:ReLE中文大模型能力评测
#核心结论
- Google
Google的模型在多个领域展现出均衡且出色的能力。尤其在教育(84.9)、**推理与数学计算(89.0)和行政公务(90.0)**领域表现突出。其模型在医疗和金融方面也展现了较强的竞争力,显示出广泛的适用性。
- OpenAI
OpenAI的模型在**推理与数学计算(91.0)和行政公务(90.0)**方面表现强劲,这与其在逻辑分析和任务执行方面的技术积累密不可分。特别是在推理能力上,OpenAI展现出显著优势。
- Meta
Meta的模型在**医疗(77.8)和心理健康(72.5)**领域表现较好。这可能意味着Meta在处理垂直行业数据、理解复杂医疗文本以及情感识别方面具有独特的优势,有望在这些专业领域提供深度支持。
- Anthropic
Anthropic的模型在行政公务(90.0)、**教育(78.0)以及语言与指令遵从(87.7)**领域表现出色。这暗示其模型在文本生成、理解用户意图以及遵循复杂指令方面具有高精度和高流畅性,非常适合需要高质量内容输出和严格指令遵循的场景。
五、总的来看:
-
模型布局策略:Google和OpenAI皆采取多层次布局,覆盖从高端旗舰到轻量级模型的广泛市场;Meta侧重开源与多参数版本,致力于构建开放生态;而Anthropic则专注于少数高质量模型,走精品路线。
-
价格竞争:Anthropic定价最高,瞄准高端市场;Google和OpenAI旗舰模型价格偏高,但也提供亲民或免费版本;Meta则以相对低价或免费模式,积极推动模型普及。
-
旗舰性能:Google的旗舰模型在总分上表现最佳,综合实力领先;OpenAI在推理与数学计算方面表现卓越;Meta在医疗和心理健康领域具有独特优势;Anthropic则在行政公务和语言指令遵从方面展现高水准。
-
领域应用能力:Google在教育、推理与数学计算、行政公务等多领域表现全面;OpenAI擅长推理和行政公务;Meta在医疗和心理健康等垂直领域有所建树;Anthropic则在文本处理和指令遵循方面表现突出。
等一下!说好的海外五强啊?XAI呢?➡️留个悬念,下次一定!下期实测横评国内基模五强🆚海外五强,感兴趣的宝子们,敬请关注哈!
更多内容
-
如需要更多关于本次「海外五强专题」的更多数据内容,请后台私信:
① 后台私信“海外五强”获取详细评分表单;
② 后台私信/评论获取旗舰模型最新评测集、badcase;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









