




 本文深入解析了Q-Learning算法在MountainCar-v0环境中的应用,通过离散化状态空间,实现对连续环境的有效控制。文章详细介绍了关键参数设置、离散化处理方法、Q表更新策略及算法优化技巧,最后展示了算法的实际运行效果。
本文深入解析了Q-Learning算法在MountainCar-v0环境中的应用,通过离散化状态空间,实现对连续环境的有效控制。文章详细介绍了关键参数设置、离散化处理方法、Q表更新策略及算法优化技巧,最后展示了算法的实际运行效果。
周老师课程推荐的程序解析
一、关键点
一、关于eta
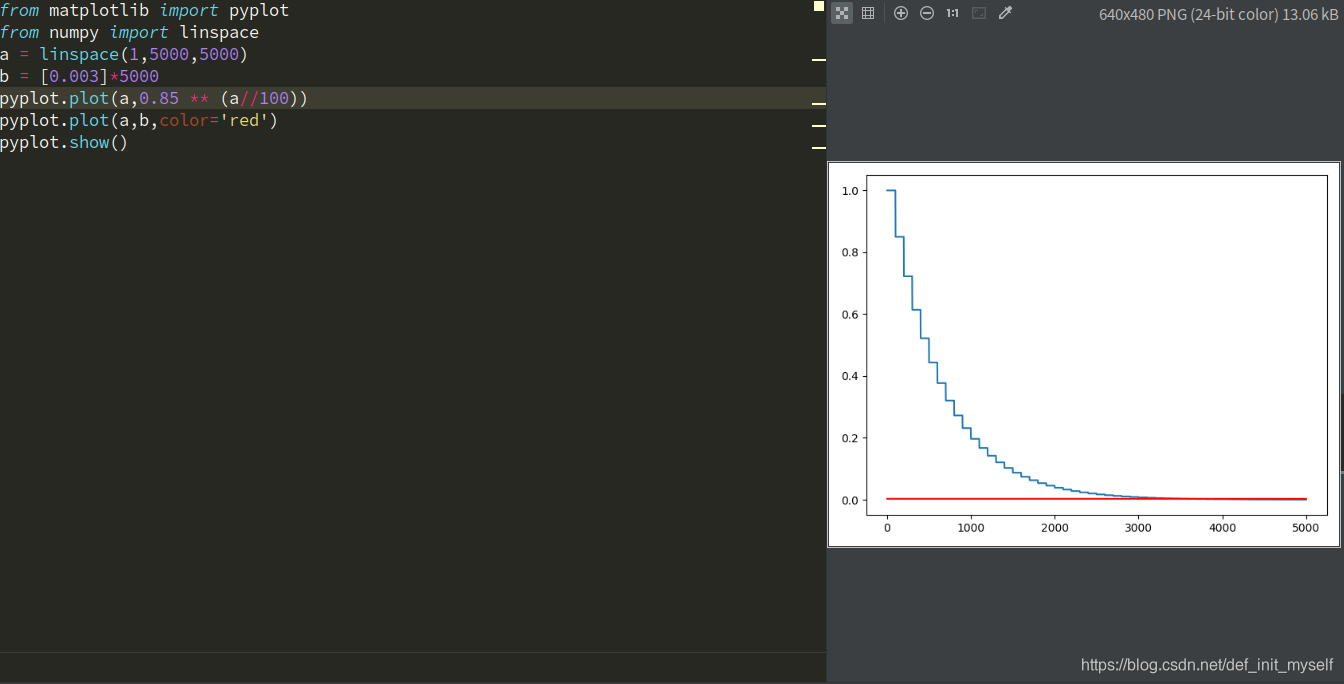
二、关于离散化
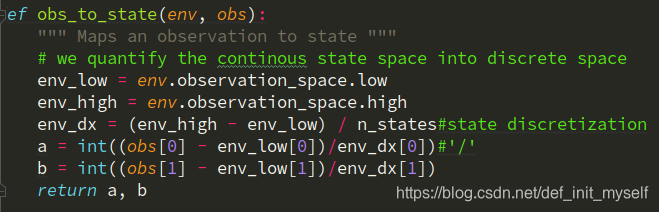 离散为40个状态(二维)
离散为40个状态(二维)
三、关于_
表示某个变量是临时的或无关紧要的
四、关于列表解析
solution_policy_scores = [run_episode(env, solution_policy, False) for _ in range(100)]
二、代码块
import numpy as np
import gym
from gym import wrappers
off_policy = True # if True use off-policy q-learning update, if False, use on-policy SARSA update
n_states = 40 # Discrete value
iter_max = 5000
initial_lr = 1.0 # Learning rate
min_lr = 0.003
gamma = 1.0
t_max = 10000
eps = 0.1
测试策略函数
def run_episode(env, policy=None, render=False):
obs = env.reset()#reset env
total_reward = 0
step_idx = 0
for _ in range(t_max):#we know it can end the game in 10000 step
if render:
env.render()#fresh env
if policy is None:
action = env.action_space.sample()
else:
a,b = obs_to_state(env, obs 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









