






MountainCarContinuous-v0 是一个经典的强化学习环境,主要用于测试连续动作空间的算法。它是 OpenAI Gym 中的一个环境,模拟了一个小车在一个山谷中的运动,目标是通过控制小车的加速度,使其能够爬上山顶。
环境描述
-
状态空间:环境的状态空间是连续的,包括两个变量:
- 车的位置
- 车的速度
-
动作空间:动作空间也是连续的,表示为一个区间 [−1,1][-1, 1][−1,1],代表对小车施加的加速度。
-
奖励函数:奖励设计得比较特殊:
- 小车到达目标位置(即山顶)时会得到一个较高的奖励(例如 +100)。
- 每个时间步会有一个负的奖励,鼓励尽快达到目标。
-
目标:在最短的时间内将小车移动到山顶。
-
结束条件:
- 小车达到目标位置(通常是 x≥0.45)。
- 达到最大步数(例如 999 步)
使用PPO算法
核心:
DAE优势函数
state正则化 影响很大
adv正则化 影响很大
无需要修改reward奖励机制,100个回合完成,需要多跑几次,有可能探索失败
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torch.nn.functional as F
def orthogonal_init(layer, gain=1.0):
nn.init.orthogonal_(layer.weight, gain=gain)
nn.init.constant_(layer.bias, 0)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.mu_head = nn.Linear(128, action_dim)
self.log_std = nn.Parameter(torch.zeros(action_dim)) # 使用nn.Parameter定义log_std
orthogonal_init(self.fc1)
orthogonal_init(self.fc2)
orthogonal_init(self.mu_head, gain=0.01)
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
mu = torch.tanh(self.mu_head(x)) # 输出均值在[-1, 1]之间
std = torch.exp(self.log_std)
return mu, std
def get_dist(self, s):
mean,std = self.forward(s)
# log_std = self.log_std.expand_as(mean) # To make 'log_std' have the same dimension as 'mean'
# std = torch.exp(log_std) # The reason we train the 'log_std' is to ensure std=exp(log_std)>0
dist = torch.distributions.Normal(mean, std) # Get the Gaussian distribution
return dist
# 定义Critic网络
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, 1)
orthogonal_init(self.fc1)
orthogonal_init(self.fc2)
orthogonal_init(self.fc3)
def forward(self, x):
x = torch.tanh(self.fc1(x))
x = torch.tanh(self.fc2(x))
value = self.fc3(x)
return value
class RunningMeanStd:
# Dynamically calculate mean and std
def __init__(self, shape): # shape:the dimension of input data
self.n = 0
self.mean = np.zeros(shape)
self.S = np.zeros(shape)
self.std = np.sqrt(self.S)
def update(self, x):#动态更新平均值和标准差可以用到在线算法(online algorithm),其中最常见的方法是Welford的算法
x = np.array(x)
self.n += 1
if self.n == 1:
self.mean = x
self.std = x
else:
old_mean = self.mean.copy()
self.mean = old_mean + (x - old_mean) / self.n
self.S = self.S + (x - old_mean) * (x - self.mean)
self.std = np.sqrt(self.S / self.n)
class Normalization:
def __init__(self, shape):
self.running_ms = RunningMeanStd(shape=shape)
def __call__(self, x, update=True):
# Whether to update the mean and std,during the evaluating,update=False
if update:
self.running_ms.update(x)
x = (x - self.running_ms.mean) / (self.running_ms.std + 1e-8)
return x
# PPO Agent
class PPOAgent:
def __init__(self, state_dim, action_dim, lr=3e-4, gamma=0.99, clip_epsilon=0.2):
self.actor = Actor(state_dim, action_dim)
self.critic = Critic(state_dim)
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=lr)
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=lr)
self.lr= lr
self.gamma = gamma
self.K_epochs = 10
self.clip_epsilon = clip_epsilon
self.epsilon = clip_epsilon
self.entropy_coef = 0.01
# 同步actor和old_actor的参数
def select_action(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
mu, std = self.actor(state)
dist = torch.distributions.Normal(mu, std)
action = dist.sample()
action = torch.clamp(action, -1, 1) # 限制动作在[-1, 1]之间
return action.cpu().numpy().flatten(), dist.log_prob(action).sum(axis=-1).item()
def update(self,replay_buffer,ep):
s, a, a_logprob, r, s_, dw, done = replay_buffer.numpy_to_tensor() # Get training data
adv = []
gae = 0
with torch.no_grad(): # adv and v_target have no gradient
vs = self.critic(s)
vs_ = self.critic(s_)
deltas = r + self.gamma * (1.0 - dw) * vs_ - vs
for delta, d in zip(reversed(deltas.flatten().numpy()), reversed(done.flatten().numpy())):
gae = delta + self.gamma * 0.95 * gae * (1.0 - d)
adv.insert(0, gae)
adv = torch.tensor(adv, dtype=torch.float).view(-1, 1) #tensor [2048,1]
v_target = adv + vs #tensor[2048,1]
adv = ((adv - adv.mean()) / (adv.std() + 1e-5))
for _ in range(self.K_epochs):
mu, std = self.actor(s)
dist = torch.distributions.Normal(mu, std)
new_log_probs = dist.log_prob(a).sum(axis=-1,keepdim=True)
ratio = torch.exp(new_log_probs - a_logprob)
surr1 = ratio * adv
surr2 = torch.clamp(ratio, 1 - self.clip_epsilon, 1 + self.clip_epsilon) * adv
dist_entropy = dist.entropy().sum(1, keepdim=True) # shape(mini_batch_size X 1)
actor_loss = -torch.min(surr1, surr2) - torch.FloatTensor([0.01])*dist_entropy
self.actor_optimizer.zero_grad()
actor_loss.mean().backward()
self.actor_optimizer.step()
critic_loss = F.mse_loss(v_target,self.critic(s)).mean()
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# 环境和训练设置
env = gym.make('MountainCarContinuous-v0')
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
agent = PPOAgent(state_dim, action_dim)
max_episodes = 3000
max_steps = 999
batch_size = 64
state_norm = Normalization(shape=state_dim) # Trick 2:state normalization
class ReplayBuffer:
def __init__(self, batch_size,state_dim,action_dim):
self.s = np.zeros((batch_size, state_dim))
self.a = np.zeros((batch_size, action_dim))
self.a_logprob = np.zeros((batch_size, action_dim))
self.r = np.zeros((batch_size, 1))
self.s_ = np.zeros((batch_size, state_dim))
self.dw = np.zeros((batch_size, 1))
self.done = np.zeros((batch_size, 1))
self.count = 0
def store(self, s, a, a_logprob, r, s_, dw, done):
self.s[self.count] = s
self.a[self.count] = a
self.a_logprob[self.count] = a_logprob
self.r[self.count] = r
self.s_[self.count] = s_
self.dw[self.count] = dw
self.done[self.count] = done
self.count += 1
def numpy_to_tensor(self):
s = torch.tensor(self.s, dtype=torch.float)
a = torch.tensor(self.a, dtype=torch.float)
a_logprob = torch.tensor(self.a_logprob, dtype=torch.float)
r = torch.tensor(self.r, dtype=torch.float)
s_ = torch.tensor(self.s_, dtype=torch.float)
dw = torch.tensor(self.dw, dtype=torch.float)
done = torch.tensor(self.done, dtype=torch.float)
return s, a, a_logprob, r, s_, dw, done
replay_buffer = ReplayBuffer(2048,2,1)
# env_evaluate = gym.make("MountainCarContinuous-v0",render_mode="human")
env_evaluate = gym.make("MountainCarContinuous-v0")
treward = []
for episode in range(max_episodes):
state,_ = env.reset()
episode_reward = 0
done = False
ter = False
step = 0
while not done:
step += 1
state = state_norm(state)
action, log_prob = agent.select_action(state)
next_state, reward, done,ter, _ = env.step(action)
epend = 0
episode_reward += reward
dw = False
if done:
dw = True
end = False
if done or ter:
end = True
done = True
replay_buffer.store(state, action, log_prob, reward, next_state, dw, end)
if replay_buffer.count == 2048:
agent.update(replay_buffer,episode)
replay_buffer.count = 0
state = next_state
treward.append(episode_reward)
if episode % 1 == 0:
print(f'Episode {episode}, {step},Reward: {episode_reward}')
if (episode+1) % 100 == 0:
evalreward = 0
for i in range (3):
s, _ = env_evaluate.reset()
er = 0
done1 = False
ss = 0
s = state_norm(s, update=False)
while not done1:
ss +=1
s = torch.FloatTensor(s).unsqueeze(0)
a,_ = agent.actor(s) # We use the deterministic policy during the evaluating
s_, r, done1,ter, _ = env_evaluate.step(a.detach().numpy().flatten())
if ter:
done1 = True
er += r
s_ = state_norm(s_, update=False)
s = s_
evalreward+=r
print(f'evaluate step {ss},episode_reward {er}')
if evalreward/3 > 99 :
break
import matplotlib.pyplot as plt
plt.plot(treward)
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('Total Rewards per Episode in MountainCarContinuous')
plt.show()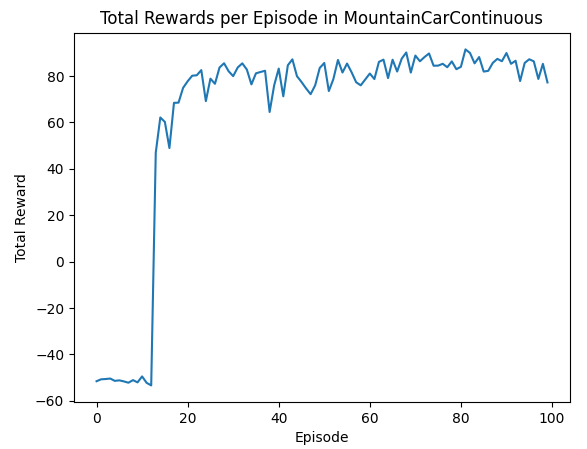
评估数据:
evaluate step 177,episode_reward 95.8164717625224
evaluate step 174,episode_reward 95.12126179418682
evaluate step 285,episode_reward 93.24391279866033
参考:

















 1210
1210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









