






本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。

“大模型在训练过程中学习了人类几乎所有已知的知识,但是大模型为什么不会输出一些不健康的文字呢?”
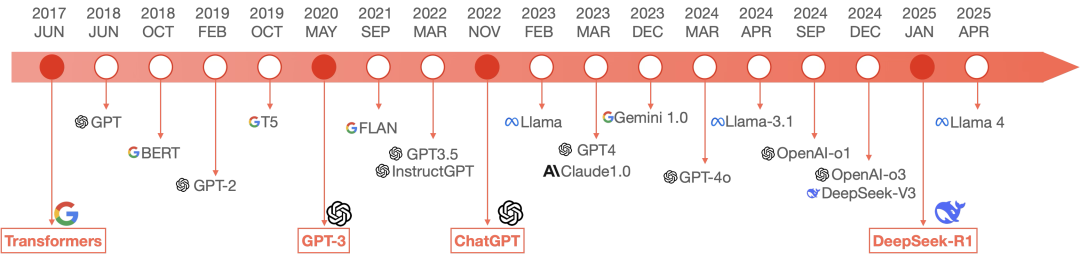
图 大语言模型发展简史
无论哪家的大模型产品,它的回答输出内容都很阳光健康、积极向上、通情达理,没有任何的不合时宜的文字,从不输出带有暴力、歧视性的语言,“情商”极高。那它们的情商是从哪里来的呢?
在ChatGPT之前,大语言模型已经出现了很长时间,只不过一直存在于研究机构,并未向大众开放。比如OpenAI公司早在2022年3月就研究出了具有“涌现”能力的逻辑性很强的GPT3.5,但是直到2022年11月才推出了面向公众的产品ChatGPT,让“阳春白雪”走向了普通大众。这7个月的时间,OpenAI为了让普通大众使用大模型,为了让大模型从“实验品”成为真正的“产品”,OpenAI做了一件很重要的事情,那就是RLHF。
什么是RLHF
RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)是一种结合强化学习(Reinforcement Learning, RL)与人类主观判断的机器学习方法,旨在通过人类反馈优化模型输出,使其更符合人类的价值观和偏好。它被广泛应用于大语言模型(LLM)的训练(如DeepSeek、ChatGPT等),显著提升了模型输出的安全性、逻辑性和人性化程度。
也就是说,大模型在“出厂”之前必须要通过RLHF方法进行“教育”,如果输出不和谐的信息就“惩罚”,输出健康的信息就“奖励”,以杜绝大模型输出不友好的内容,其目标是为了确保AI机器与人类的意图和价值观保持一致,能够理解人类的真实意图及隐含意图。
注:RLHF在许多领域都有应用,包括但不限于个性化推荐、客户服务、教育和游戏开发。通过结合人类直觉和机器学习的强大能力,RLHF为创建更加智能和用户友好的系统提供了一种有前景的方法。这种方法特别适用于训练智能系统,尤其是那些需要与人类用户进行交互并根据用户反馈进行优化的系统。
RLHF的工作流程
监督微调:将预训练模型适应到具体的任务中。在这一阶段,模型会在利用标注过的数据集上进行训练,通过调整模型参数来优化在特定任务上的能力。
强化学习训练迭代:初始模型的生成结果需要不断发送给奖励模型进行评估,并根据奖励模型的反馈,生成其更为认可的响应。这个过程需要不断迭代,模型的性能不断提高。
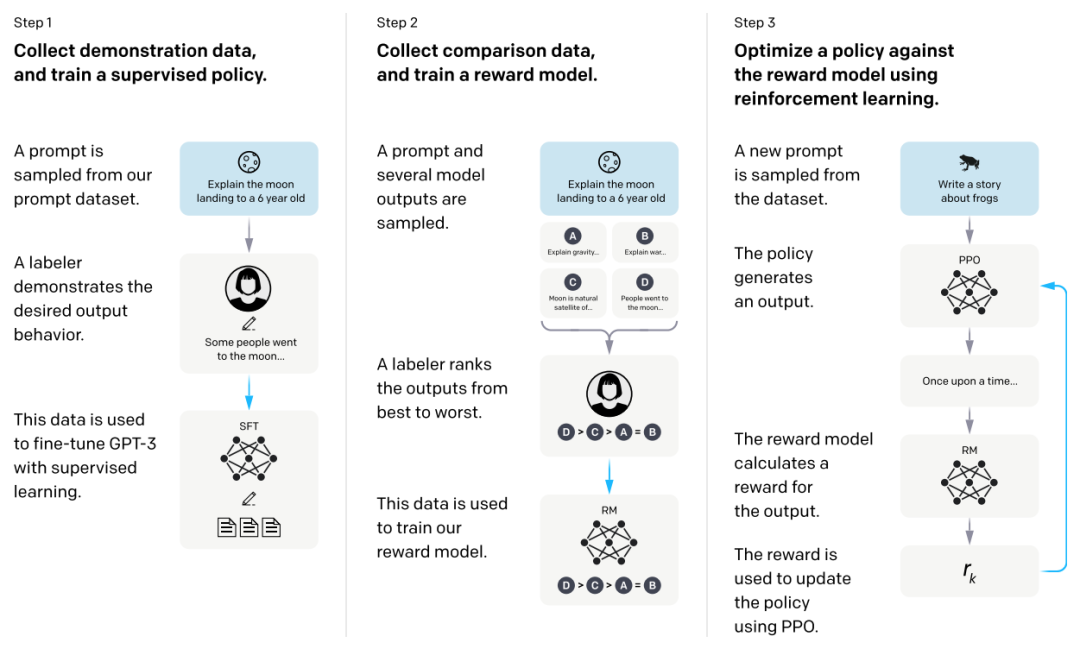
图片源自:https://arxiv.org/pdf/2203.02155
如果把大模型比作人类的成长,可以分为家庭教育、教师培训、学校教育三个阶段:
1.家庭教育:预训练大模型+有标签数据监督微调
预训练大模型:
在预训练阶段是模型知识注入的最重要的阶段,通过无监督学习从这些海量文本数据中提取语言知识,大模型模型可以基于语料学习知识,学习语言结构等。例如,对于ChatGPT来说它的预训练大模型就是GPT-3。大模型先通过大量数据自学(比如读遍互联网的文本),学会基本技能,比如生成句子或识别图片。这时的大模型就像还没有上学的幼儿园新生,能做题但可能答非所问。
有标签数据的监督微调:
将预训练模型适应到具体的任务中。在这一阶段,模型会利用标注过的数据集进行训练,通过调整模型参数来优化在特定任务上的能力。把人类的偏好(例如“有礼貌”“不说废话”)变成明确的“评分标准”。也就是人类当“考官”打分,就是人工给问题(prompt)写示范回答(demonstration),然后给大模型学习:
-
排序对比:让大模型生成10个答案,人工标出哪个最好、哪个最差。
-
直接修正:人类动手修改AI的错误回答(比如“这句表达不合适,应改成……”)。
-
人类给大模型的表现打分。
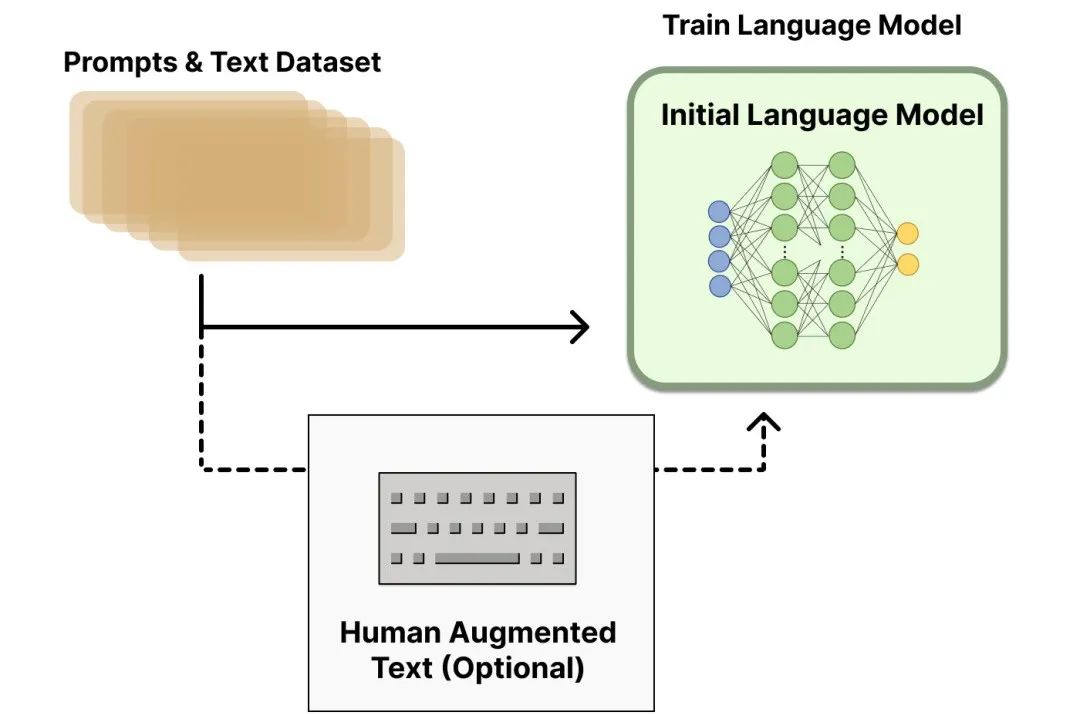
图片源自:https://huggingface.co/blog/zh/rlhf
2.教师培训:训练奖励模型RM(大模型的“金牌教练”)
我们需要一个模型来定量评判模型输出的回答在人类看来是否质量不错,即输入[提示(prompt),模型生成的回答],奖励模型输出一个能表示回答质量的量化标准。奖励模型可以在没有人类干预的情况下对初始模型的生成结果进行打分。
对一个或多个模型生成结果提供反馈,根据生成的质量或正确性进行排名。通过PPO(Proximal Policy Optimization)算法对模型进行微调,生成奖励模型。
奖励模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。可以用端到端的方式用基础大模型建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。比如:
生成“您好,有什么可以帮您?” → 奖励值+10分
生成“自己不会查吗?” → 奖励值-5分
用人类的打分数据训练一个奖励模型,它像一位严格教练,能自动评估大模型的回答是否符合人类偏好。
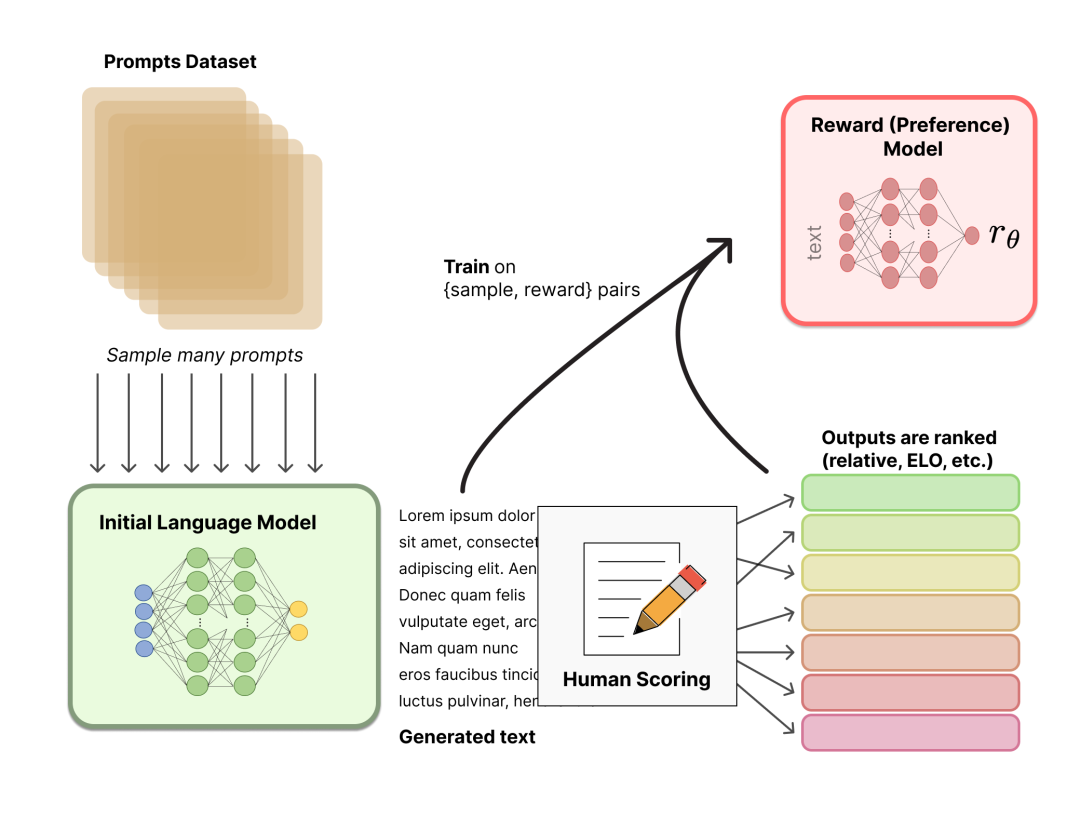
图片源自:https://huggingface.co/blog/zh/rlhf
3.学校教育:通过强化学习训练语言模型
基于强化学习去优化调整语言模型。利用奖励模型输出的奖励,用强化学习方式微调优化基础大模型。例如:
尝试说“我理解您的困扰”→ 奖励+8分 → 记住这个方向。
尝试说“这个问题很蠢”→ 奖励-10分 → 避免再犯。
大模型通过反复试错优化自己,目标是让奖励模型的打分尽可能高。
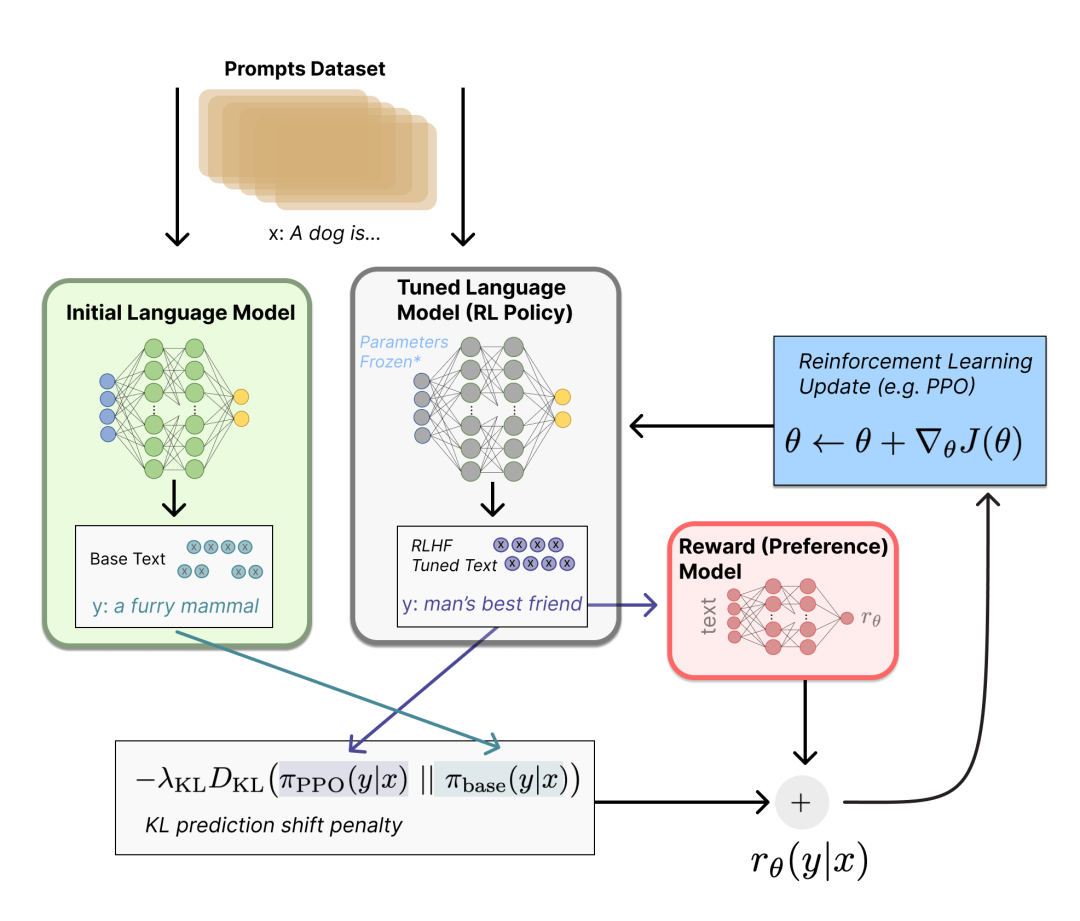
图片源自:https://huggingface.co/blog/zh/rlhf
RLHF优缺点
RLHF让大模型的回答翔实、公正,并拒绝回答不当的问题,拒绝回答知识范围外的问题。主要优缺点有:
1. 优点
-
提升模型对齐:使得模型生成的结果更符合人类的意图和偏好。
-
增强模型理解能力:通过人类的指导,模型可以更好地理解复杂和抽象的概念。
-
减少试错成本:减少了传统强化学习中大量的试错过程。
2.缺点
-
多样性减少:RLHF可能导致模型生成的结果过于集中,减少了输出的多样性。
-
人类反馈的偏差:如果人类反馈存在偏差,那么模型也可能学习到这些偏差。
-
实际应用难度:获取大量一致且高质量的人类反馈是一项挑战。
总结
RLHF提供了一种有效的途径来改善模型的行为和输出质量,尤其是在需要紧密对齐人类意图和偏好的应用场景中。大模型之所以拥有“高情商”,遵纪守法,遵循人类道德规范,甚至是具有一定的情感表达,具有不可思议的“共情”能力,根本原因是在大模型训练的最后阶段,对其进行了深刻而广泛的训练(“教育”)。
通过RLHF强化学习,甚至不惜牺牲一定的性能换取与人类行为“对齐”。
注:经过RLHF强化学习而损失的性能又被称为“对齐税”。
总的来说,大模型的“情商”是经过严格的“奖惩”训练而来的,“高情商”通过RLHF强化学习固化到大模型的参数中。
参考文献:
1.https://arxiv.org/pdf/2203.02155
2.https://huggingface.co/blog/zh/rlhf
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









