




本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:【即插即用涨点模块】GSConv混合标准卷积与深度可分离卷积:轻量化同时确保精度与速度提升【附源码】
论文信息

在这里插入图片描述
论文地址:https://arxiv.org/abs/2206.02424
源码地址:https://github.com/alanli1997/slim-neck-by-gsconv
摘要
实时目标检测在工业和研究领域至关重要。传统轻量化模型依赖深度可分离卷积(DSC)但牺牲精度,而大模型难以满足边缘设备实时性需求。本文提出新型轻量卷积技术GSConv,通过混合标准卷积(SC)与DSC的特征输出,在保持精度的同时显著降低计算成本。基于GSConv进一步设计「瘦颈」(Slim-Neck, SNs)架构,通过20+组对比实验验证其优越性:在Tesla T4上以~100FPS实现SODA10M数据集70.9% AP50,达到SOTA性能。
方法
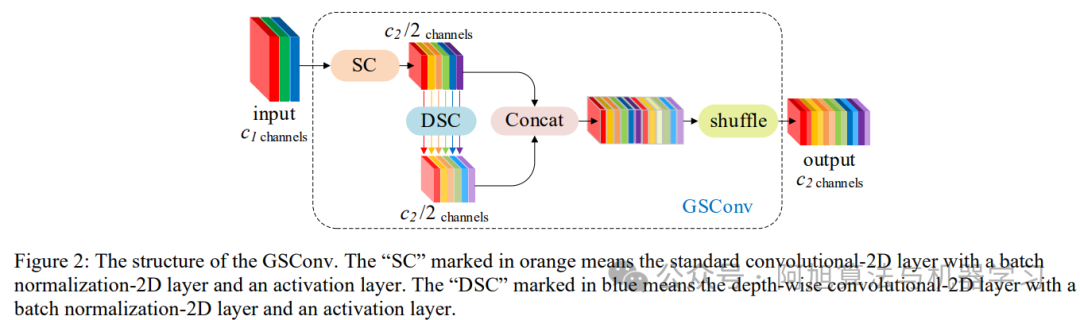
在这里插入图片描述
-
GSConv混合策略:主分支采用3x3 SC捕捉通道关联,辅助分支采用5x5 DSC提取空间特征,通过均匀混洗(shuffle)融合两类特征。
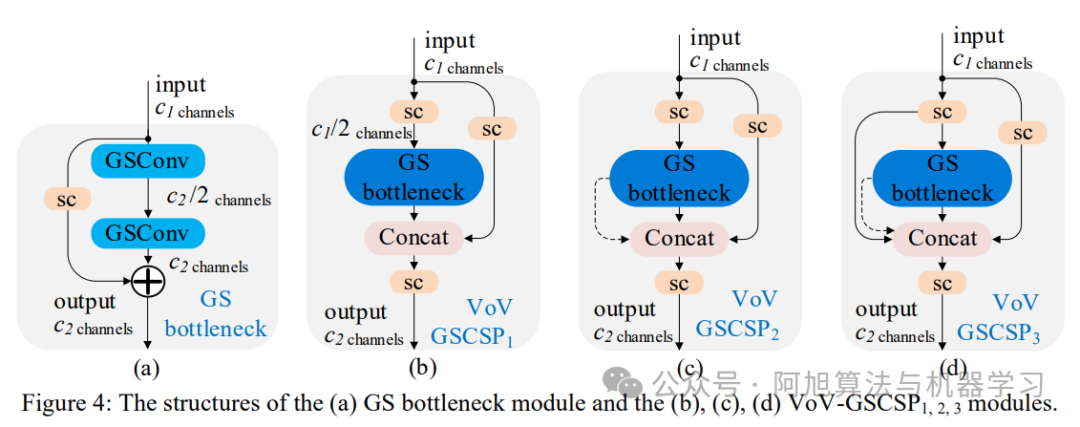
-
VoV-GSCSP模块:基于GSConv设计跨阶段部分网络,三种结构中以VoV-GSCSP1性价比最高。
-
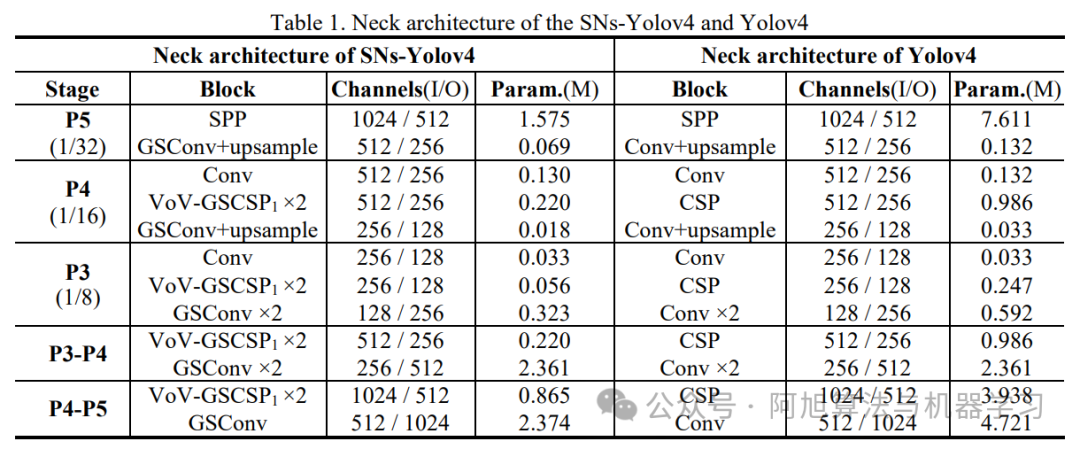
瘦颈架构(SNs):仅在颈部使用GSConv,主干保留SC,平衡精度与速度。
-
注意力机制优化:在主干末端插入CA模块,头部入口嵌入SPPF。
-
损失函数与激活函数:采用EIoU提升边框回归精度,Mish激活函数增强非线性。
对应图表:
-
GSConv结构:
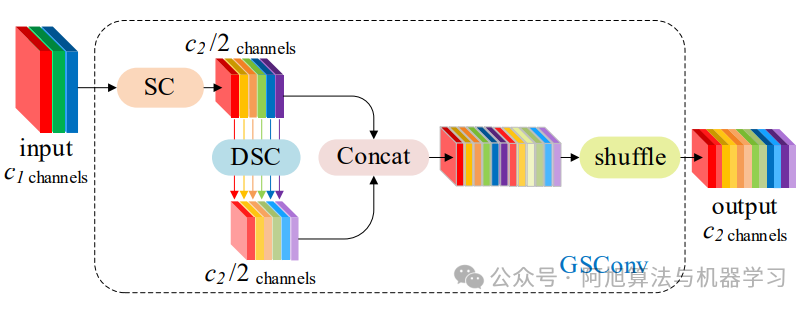
-
特征可视化对比:
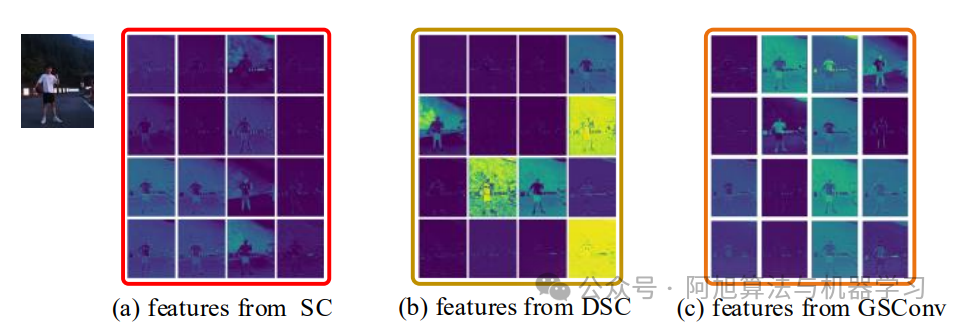
-
VoV-GSCSP设计:
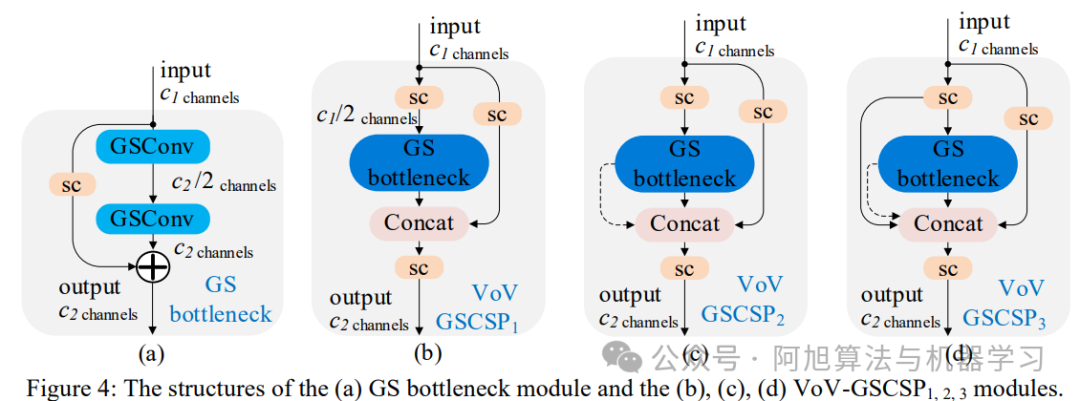
创新点
-
GSConv技术:首创SC与 DSC的特征混洗机制,以50%计算量实现接近SC的表示能力。
-
硬件友好设计:支持线性运算混洗作为转置操作的替代方案,适配边缘设备。
-
颈部轻量化范式:首次提出「仅瘦颈」设计,相比全模型轻量化提升6.3% AP50。
-
工程优化组合:验证EIoU+Mish在轻量化模型中的最佳实践。
GSConv核心作用
-
特征融合:通过混洗打破DSC的通道隔离,保留空间-通道关联。
-
计算优化:FLOPs仅为SC的50%,参数量减少36%。
-
扩展性强:支持大核(17x17)辅助分支扩展感受野。
-
精度保障:在WiderPerson上使轻量化模型AP50提升14.3%。
对应图表:
-
不同卷积方法对比:
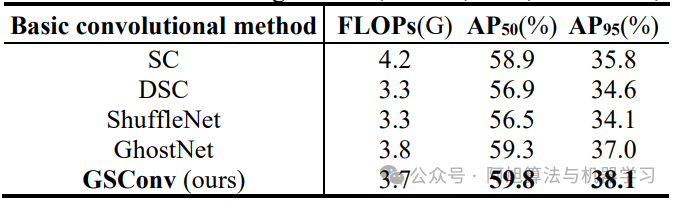
总结
GSConv通过优雅的混合策略解决了轻量化卷积的表示瓶颈,SNs架构将其优势聚焦于检测器颈部。实验表明该方法在边缘设备上实现精度与速度的帕累托最优,为实时检测提供新范式。未来可扩展至低光检测、遥感图像等场景。
源码
class GSConv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, g=1, act=True):
"""
初始化GSConv模块
:param c1: 输入通道数
:param c2: 输出通道数
:param k: 卷积核大小
:param s: 步长
:param g: 分组卷积的组数
:param act: 是否使用激活函数
"""
super().__init__()
# 将输出通道数分成两半
c_ = c2 // 2
# 第一个普通卷积层
self.cv1 = Conv(c1, c_, k, s, None, g, act)
# 第二个深度可分离卷积层,卷积核大小为5x5
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
def forward(self, x):
# 第一次卷积操作
x1 = self.cv1(x)
# 对第一次卷积的结果进行第二次卷积,并将两个结果在通道维度拼接
x2 = torch.cat((x1, self.cv2(x1)), 1)
# 获取张量形状:batch_size, channels, height, width
b, n, h, w = x2.data.size()
# 将batch和channel维度合并以便后续处理
b_n = b * n // 2
# 改变张量形状并进行维度置换
y = x2.reshape(b_n, 2, h * w)
y = y.permute(1, 0, 2)
y = y.reshape(2, -1, n // 2, h, w)
# 最终将两个分组在通道维度拼接,恢复通道顺序
return torch.cat((y[0], y[1]), 1)THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 3650
3650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









