 通用大模型演进、挑战与未来方向
通用大模型演进、挑战与未来方向





本文回顾了通用大模型的发展历程,梳理关键技术节点,从早期基于规则的系统和传统机器学习模型,到深度学习的崛起,再到Transformer架构,以及GPT系列及国内外通用大模型的进展。尽管GLMs在多个领域取得了显著进展,但其发展也面临诸多挑战,包括计算资源需求、数据偏见与伦理问题及模型的解释性与透明性。分析了这些挑战,并探讨了GLMs未来发展的5个关键方向:模型优化、多模态学习、具情感大模型、数据与知识双驱动以及伦理与社会影响。通过这些策略,通用大模型有望在未来实现更广泛和深入的应用,推动人工智能技术的持续进步。
随着人工智能技术的飞速发展,通用大模型(general large models,GLMs)已经成为人工智能领域的重要研究方向,通常具备以下特点。

1)大规模。通用大模型通常拥有大量的参数,从几十亿至上千亿参数不等,通过大规模数据进行训练,从而具备强大的学习和推理能力。
2)预训练—微调。通用大模型通常采用预训练和微调的策略。首先在大规模未标注数据上进行无监督或自监督预训练,然后通过有监督的微调适应特定任务。
3)通用性。通用大模型具备广泛的适用性,可以处理不同类型的数据和任务,如文本、图像、音频等。
4)多模态。一些通用大模型能够处理多种模态的数据,如文本与图像结合,体现了广泛的应用潜力(图1)。
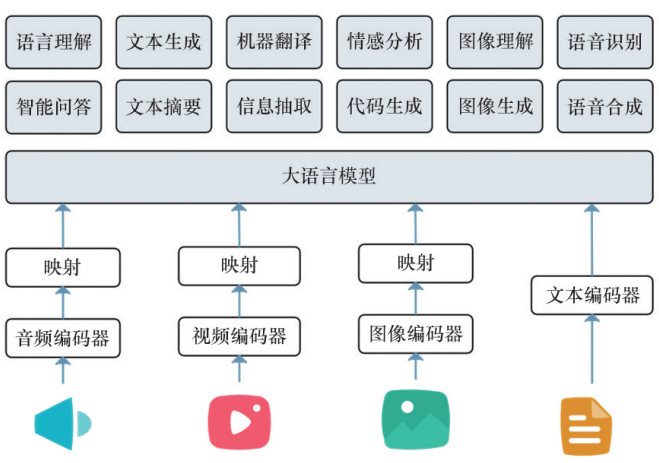
图1 多模态通用大模型
5)高度复杂。由于拥有大量参数和复杂的架构,通用大模型具备强大的表现力和学习能力,但是,同时也面临着计算资源需求高、模型解释性差等挑战。
通用大模型为实现更高级的理解、交互和生成任务提供了可能,被广泛认为是推动人工智能技术向通用智能发展的关键因素。自生成式预训练变换器(generative pre-trained transformer,GPT)系列模型问世以来,这一领域取得了长足的进步。随着以GPT为代表的大模型不断涌现,研究人员已深刻认识到通用大模型不仅代表着当今人工智能技术的前沿,更预示着未来智能系统的发展方向。
通用大模型的发展得益于深度学习的进步以及计算能力的提升。Transformer架构的引入,打破了传统循环神经网络在处理长序列任务时的瓶颈,开启了大规模预训练模型的时代。GPT系列模型进一步展现了通过大规模预训练来学习通用知识的潜力,为实现通用人工智能(artificial general intelligence,AGI)奠定了基础。
本文探讨通用大模型的演进路线,分析其发展历程、面临的挑战及未来可能的方向。
通用大模型的发展
早期模型
在通用大模型崭露头角之前,人工智能领域主要依赖于基于规则的系统和早期的机器学习模型。这些模型包括决策树、支持向量机(SVM)及朴素贝叶斯分类器等。虽然这些方法在特定任务上取得了一定的成功,但它们在处理复杂语言任务和大规模数据时显得力不从心。随着数据量的增大,简单的机器学习模型逐渐难以应对。
深度学习的崛起为通用大模型的发展奠定了基础。循环神经网络(RNN)和卷积神经网络(CNN)是深度学习的两大支柱。RNN擅长处理序列数据,被广泛应用于语言建模和语音识别等任务,而CNN则在图像处理方面表现出色。然而,这两类模型都存在固有的局限性:RNN难以处理长序列数据,存在梯度消失和梯度爆炸的问题;CNN在捕捉全局特征时效率较低。
Transformer架构的出现
Transformer架构的出现彻底改变了这一领域。Vaswani等在2017年提出的Transformer架构,通过自注意力机制解决了RNN在处理长序列任务时的瓶颈问题。自注意力机制使得模型可以关注输入序列中的不同部分,从而有效地捕捉全局信息。Transformer的另一大优势在于并行计算能力。传统的RNN需要逐步处理序列数据,而Transformer则能同时处理整个序列,极大提升了计算效率。此后,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2245
2245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









