




本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/vI4d7AqzB0NQFOO6odvamw
支付宝行业智能体介绍
支付宝经过十余年的发展,已经完成了从单一的“支付工具”到服务亿万用户的“数字生活服务”平台的升级。在AI时代,支付宝正积极推进行业智能体(Industry Agents)的建设,旨在将人工智能深度融入到政务、出行、就业等核心行业场景中,为用户提供真正能“办成事”的智能化体验。

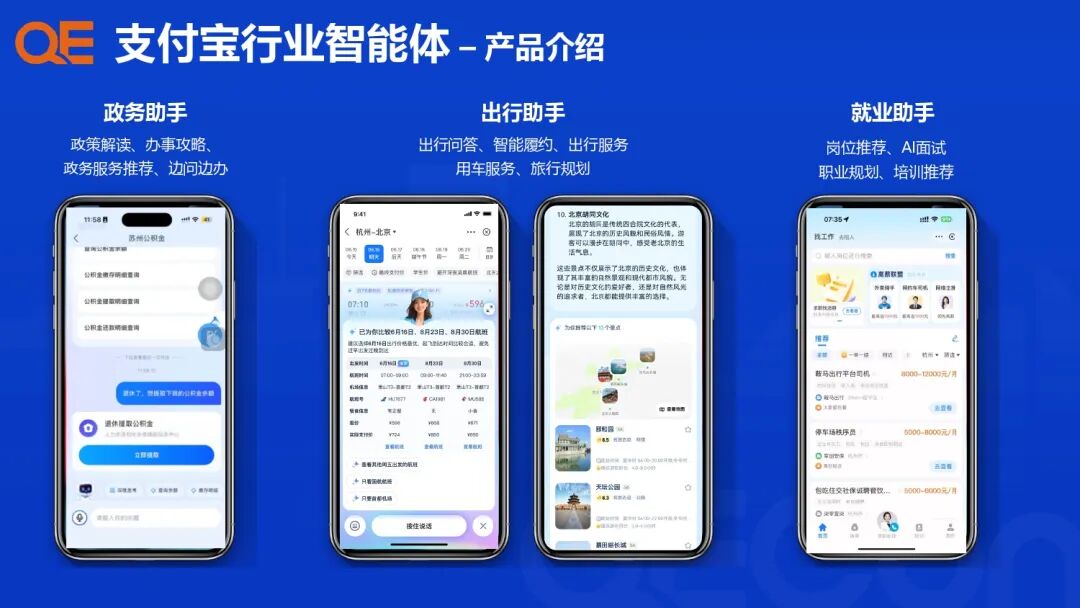
具体的产品形态包括:
-
就业助手: 提供岗位推荐、AI面试、职业规划及培训推荐等服务。
-
政务助手: 专注于政策解读、办事攻略、政务服务推荐以及支持“边问边办”的流程。
-
出行助手: 提供出行问答、智能履约、出行服务、用车服务和旅行规划等。
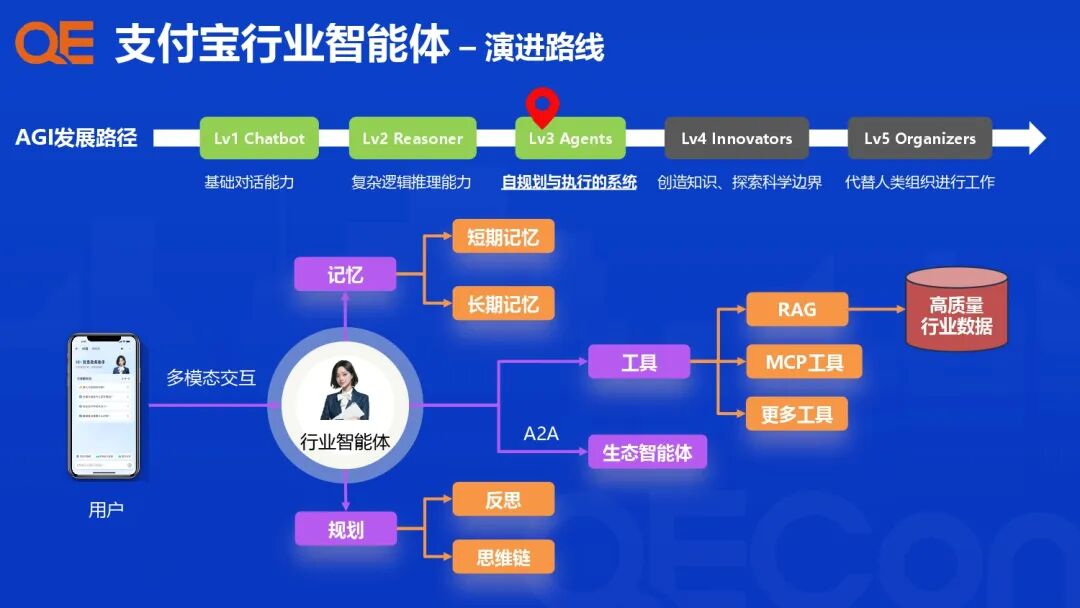
行业智能体的演进路线遵循AGI的发展路径,从基础的Chatbot (Lv1) 能力,逐步向具备复杂逻辑推理 (Lv2) 和自规划与执行 (Lv3 Agents) 的系统发展。在技术架构上,行业智能体结合了基础模型(如GPT、DeepSeek、Qwen等),并通过记忆(短期与长期)、规划(思维链、反思)、RAG(检索增强生成)以及多步骤协同(MCP)工具等模块进行增强和迭代。
评测的重要性与对象

在支付宝行业智能体的快速发展中,评测体系的建设至关重要,它扮演着多个核心角色:
-
可量化地跟踪领域进展: 为技术和业务进展提供客观数据。
-
模型效果对抗: 对比和评估不同基础模型和算法模块的实际效果。
-
训练策略验证: 验证新的训练或优化策略是否有效。
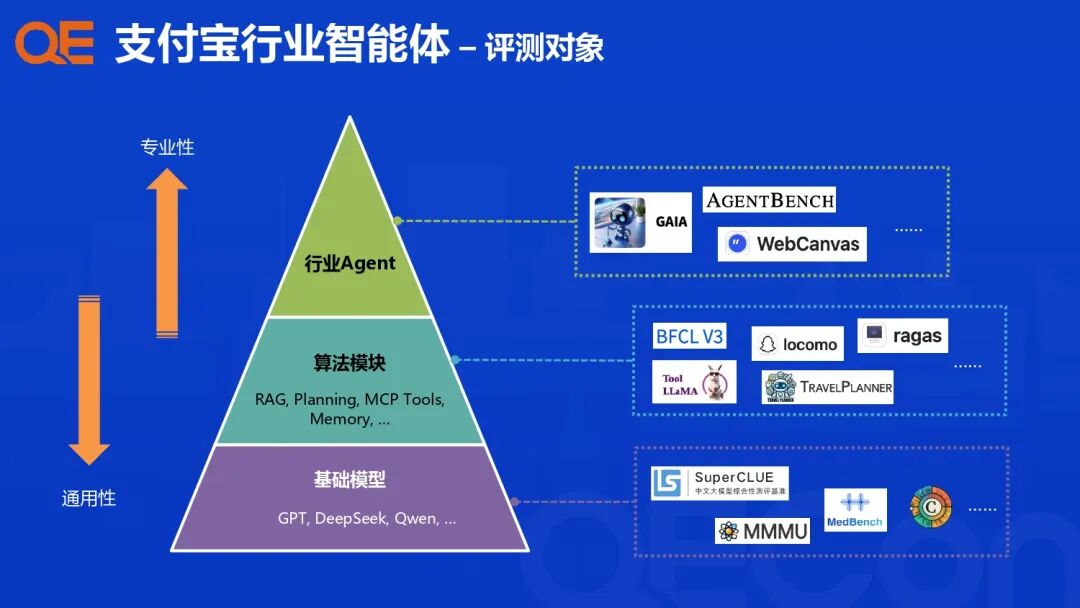
因此,评测需要覆盖智能体的不同层次,主要包括:
| 评测对象 | 核心关注点 | 组成模块示例 |
|---|---|---|
| 基础模型 | 通用性 | GPT、DeepSeek、Qwen等 |
| 算法模块 | 专业性 | RAG、Planning、MCP Tools、Memory等 |
| 行业Agent | 端到端效果 | 行业垂直应用场景中的综合表现 |
支付宝行业评测挑战与整体策略
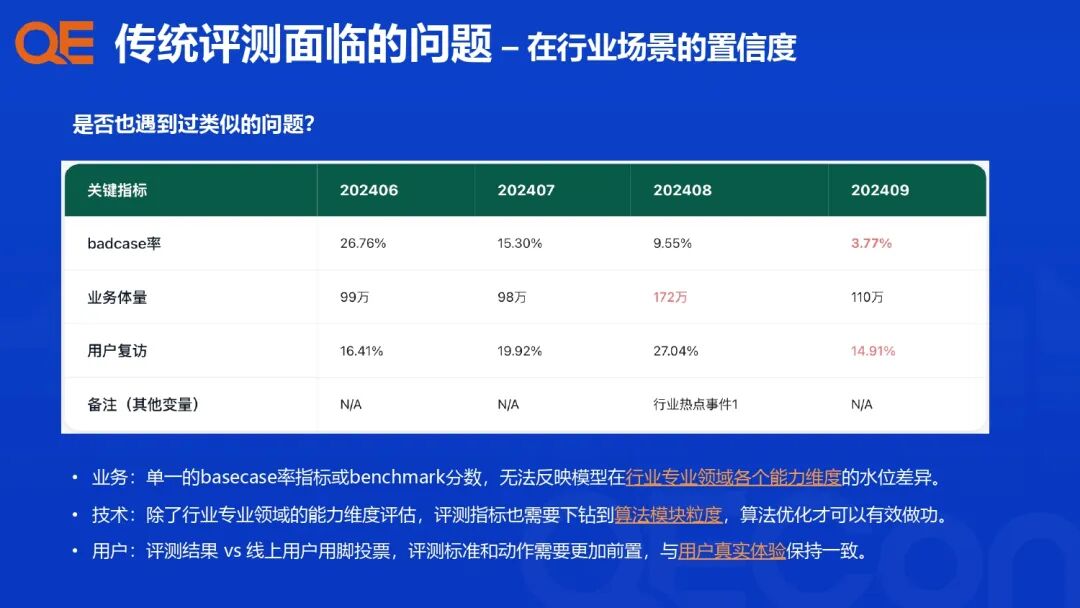
在将AI智能体应用于政务、出行、就业等专业领域时,传统的通用评测方法暴露了以下关键问题,导致评测结果缺乏置信度:
-
业务层面: 业务方需要的不仅是单一的“Base Case率”或“Benchmark分数”。这些通用指标无法反映模型在行业专业领域各个能力维度的真实水位和差异化表现。
-
技术层面: 评测指标必须能够下钻到算法模块粒度(如RAG、Planning等),才能有效指导算法工程师进行精准优化和有效迭代。
-
用户层面: 评测结果与线上用户的真实“用脚投票”存在差距。评测的标准和动作需要更加前置,并与用户的真实体验保持高度一致。
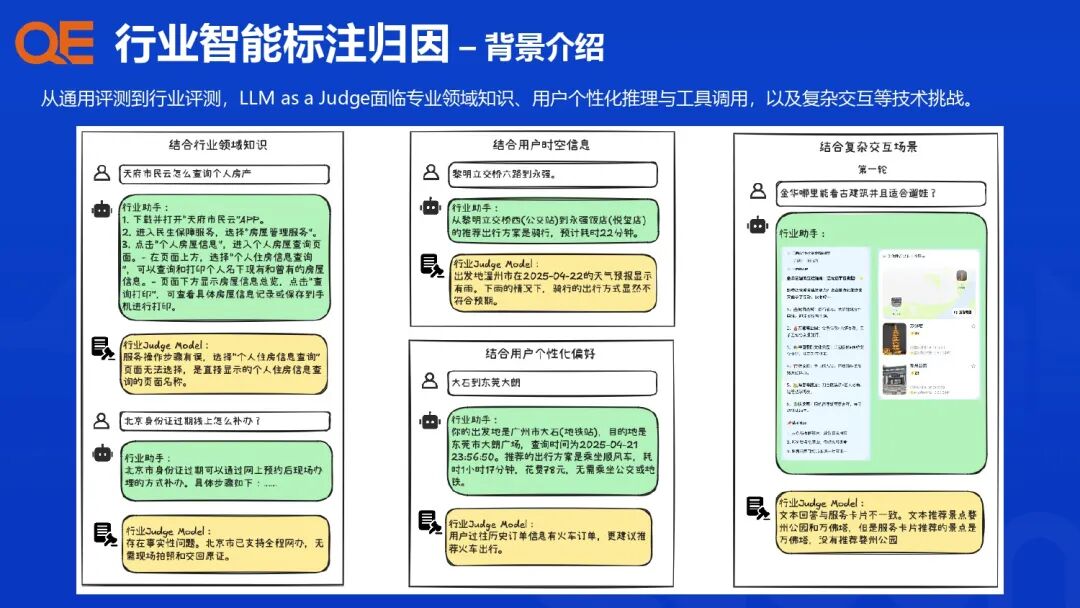
政务、出行、就业等行业助手在数据类型、风险等级和任务复杂度上差异显著,通用的评测标准难以避免失真。
| 行业助手 | 核心业务场景 | 典型数据类型 | 区域性 | 时效性 |
|---|---|---|---|---|
| 政务助手 | 政策解读、办事指南、服务推荐 | 社保/公积金、政策法规、统计数据 | 高 (各省市政策差异) | 中 (跟随政策节奏,对热点要求高) |
| 就业助手 | 岗位推荐、AI面试、职业规划 | 岗位JD、学历/履历、求职意向 | 中 (受用户偏好、地域方言影响) | 中 (招聘信息每日更新) |
| 出行助手 | 知识问答、服务推荐、智能履约 | 路线库、景点库、交通FAQ | 高 (道路规则、交通服务有差异) | 高 (路况、车次、天气实时更新) |
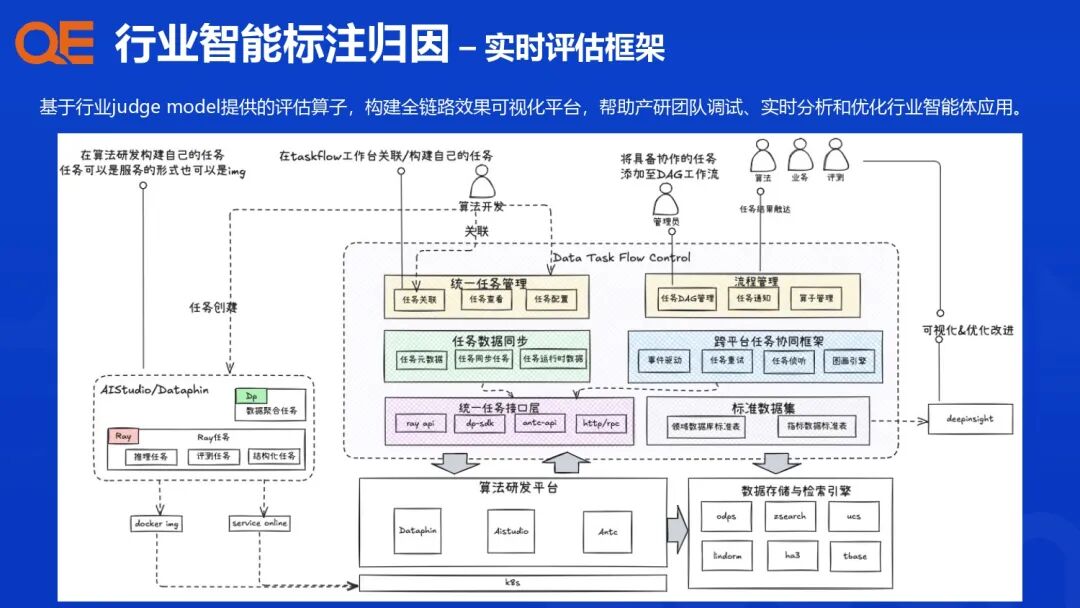
支付宝行业评测体系建设与实践
好的,我将继续整理您提供的关于“支付宝行业评测体系建设与实践”的第三部分内容,并以报告形式呈现。
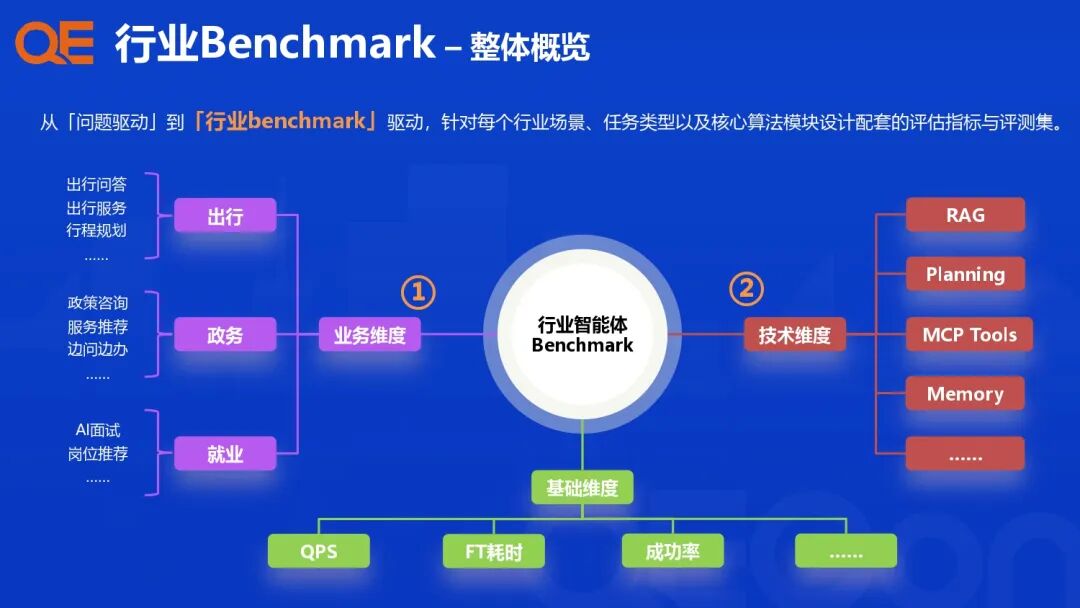
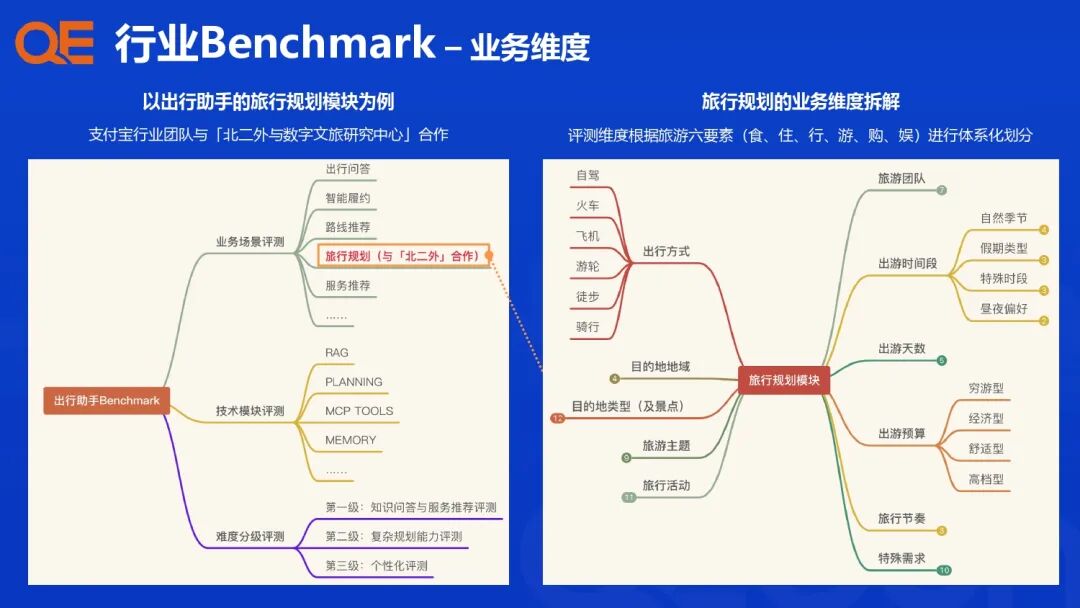
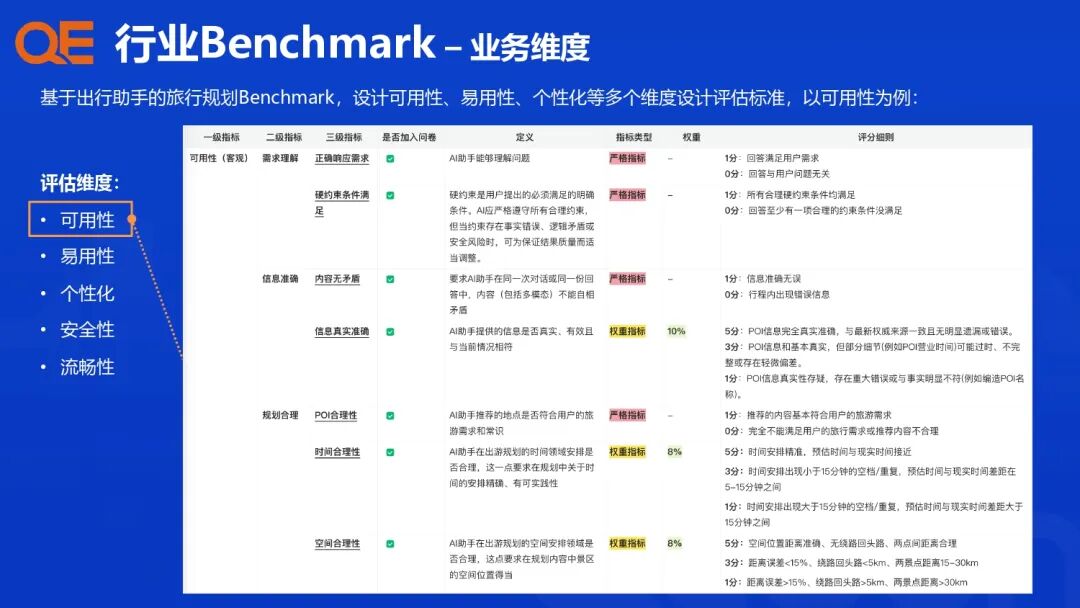
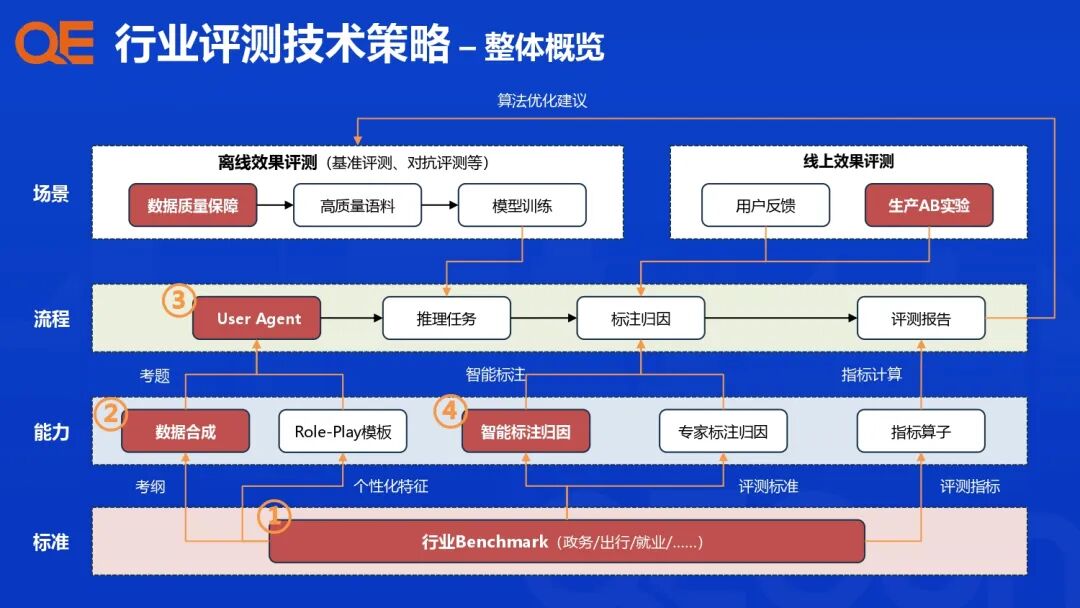
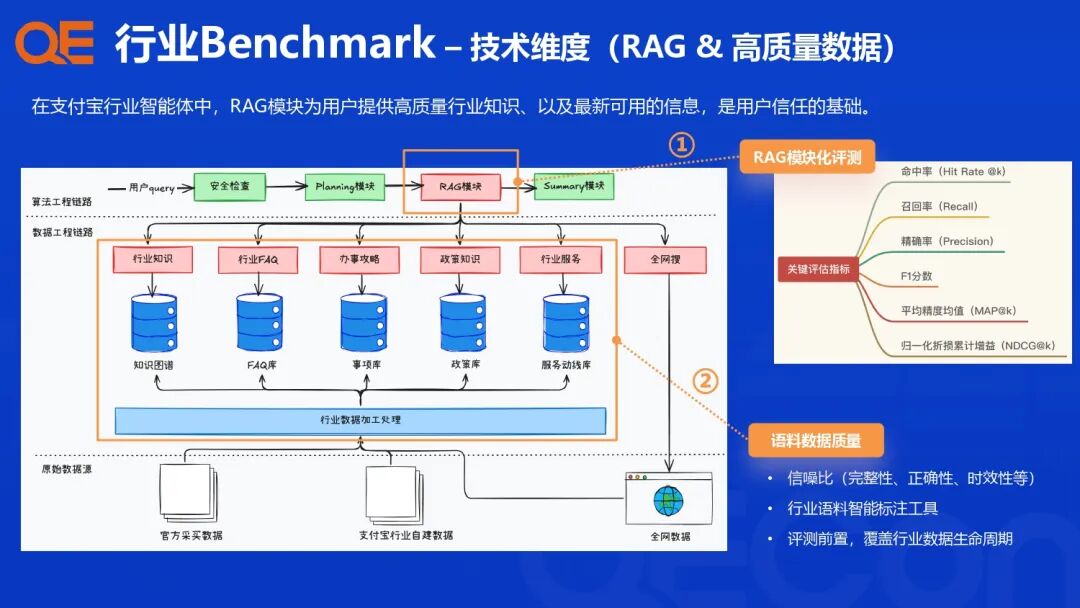
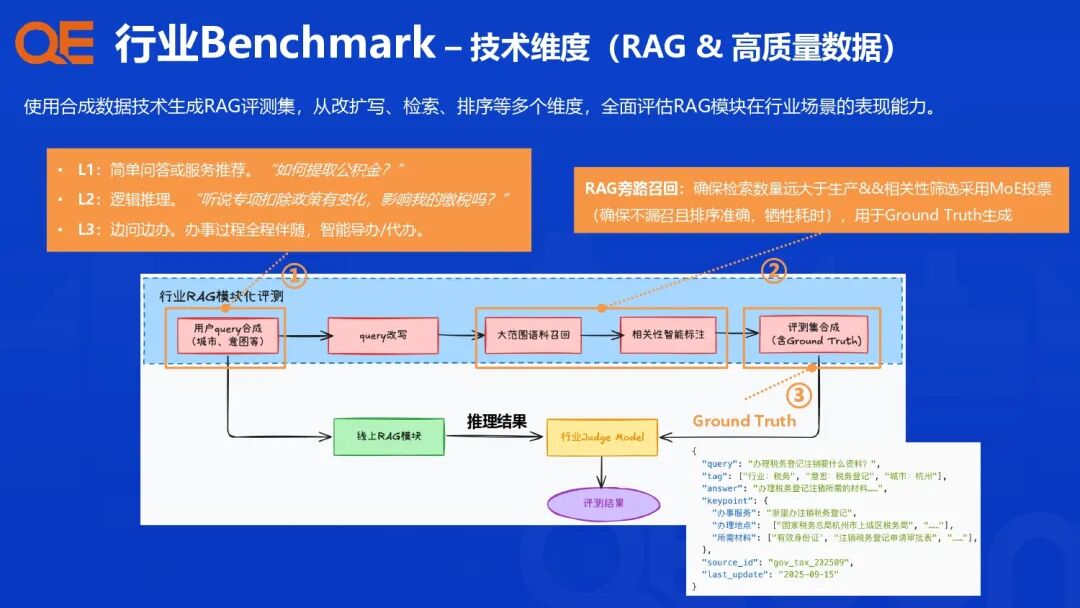
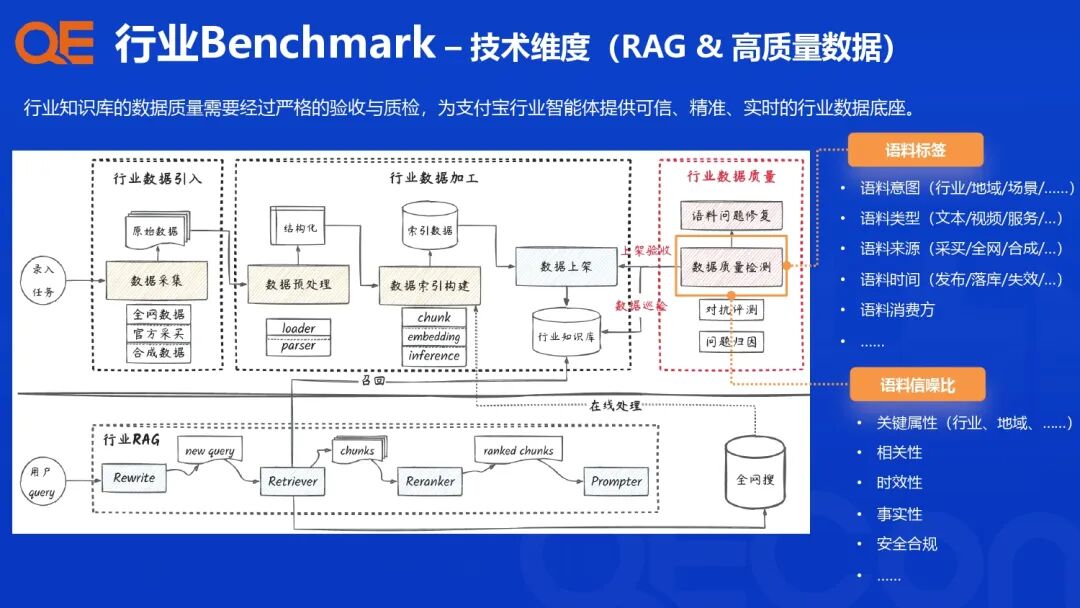
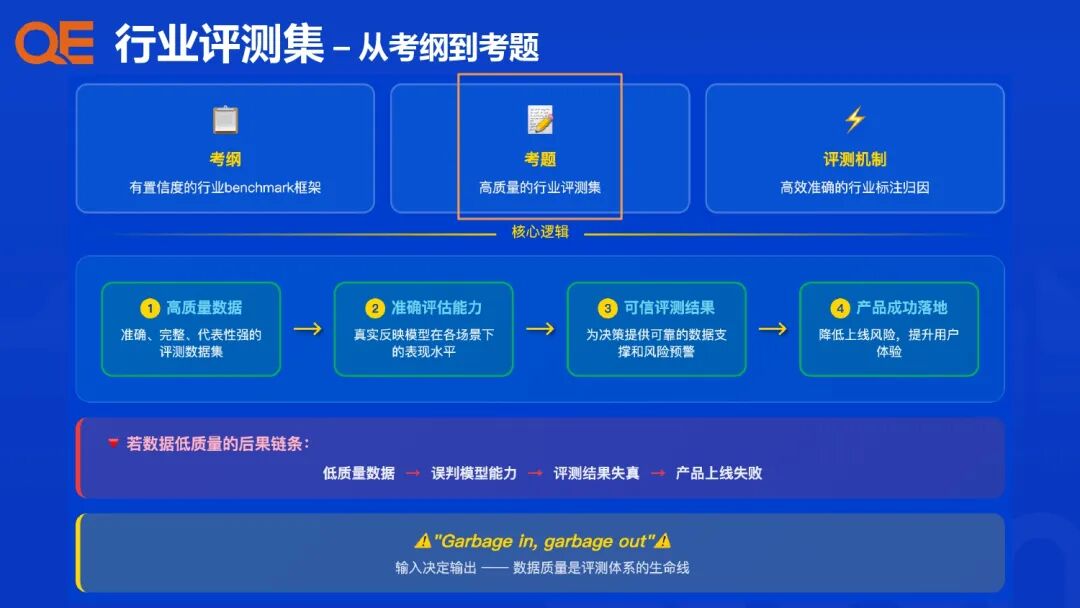
支付宝的行业智能体评测体系建设,其核心理念是从传统的“问题驱动”升级为“行业 Benchmark 驱动”,针对各个行业场景、任务类型和核心算法模块,设计配套的评估指标与评测集,构建一个多维度、高效能的评测闭环。
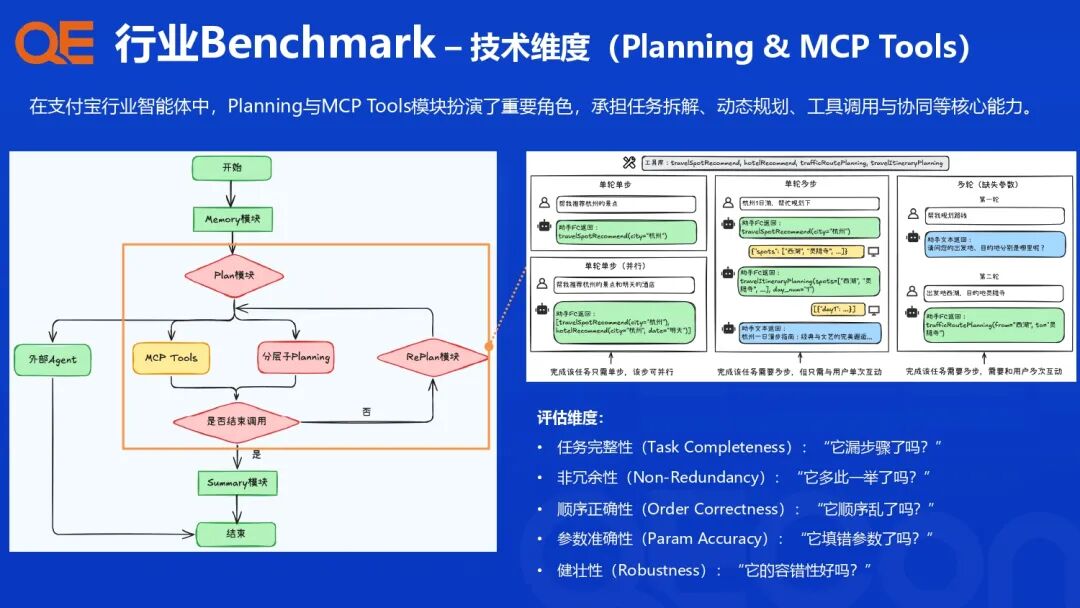
Planning 与 Multi-step Collaborative Process (MCP) Tools 是智能体执行复杂任务的核心能力。评估标准围绕其规划执行能力展开:
-
任务完整性: 检查是否有步骤遗漏。
-
非冗余性: 检查是否有“多此一举”的操作。
-
顺序正确性: 评估任务步骤的执行顺序是否正确。
-
参数准确性: 评估工具调用时的参数填充是否准确。
-
健壮性: 评估系统的容错能力。
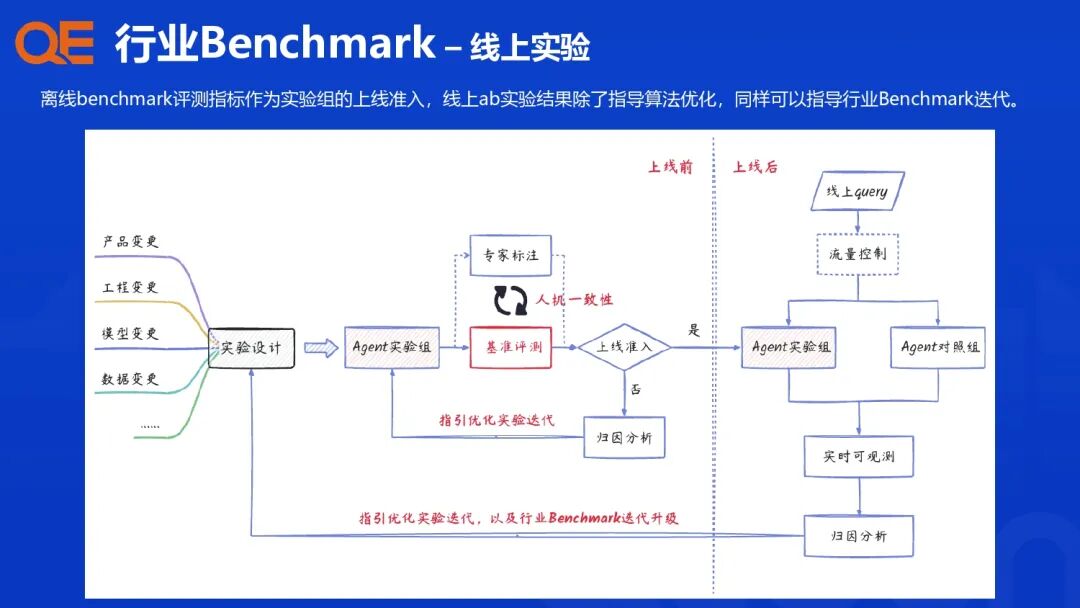
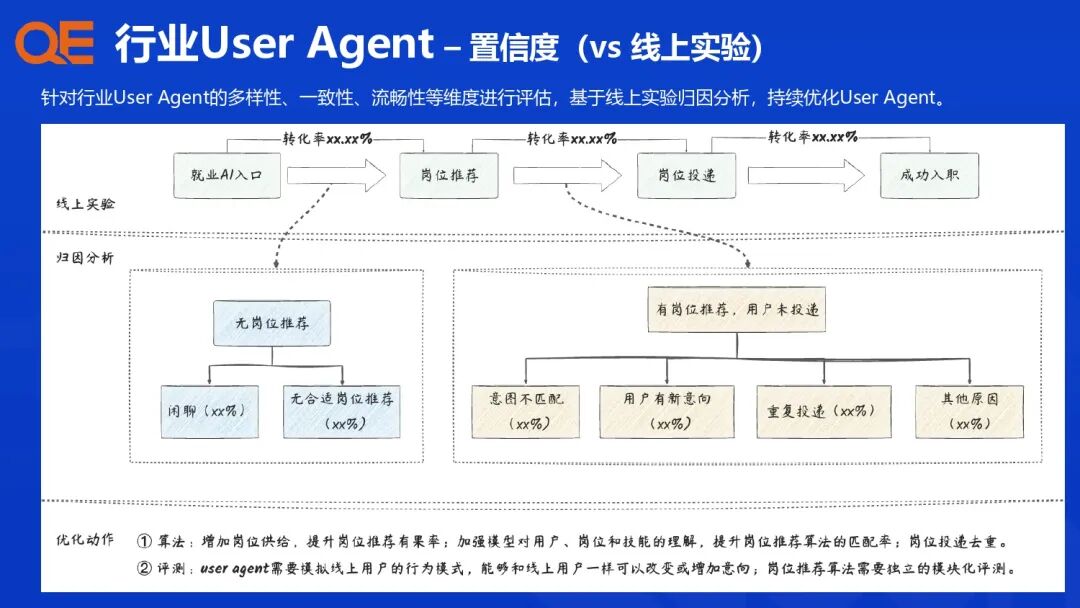
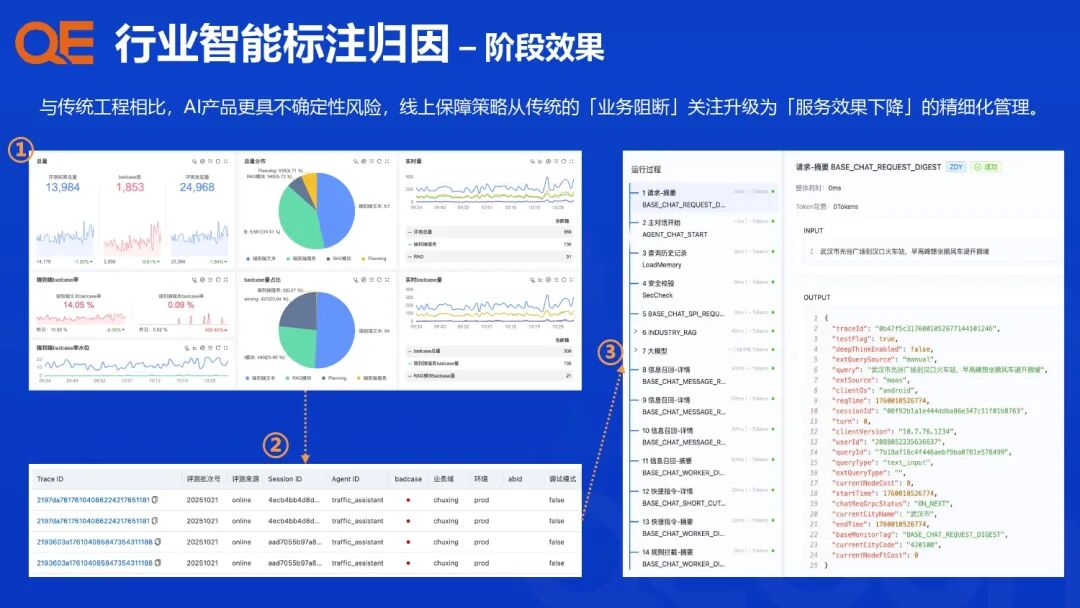
评测结果支持业务场景 + 技术能力的组合维度下钻分析。这种基于行业 Benchmark 的多维度组合,使得评测结果能够精准归因,指导算法团队进行靶向优化。
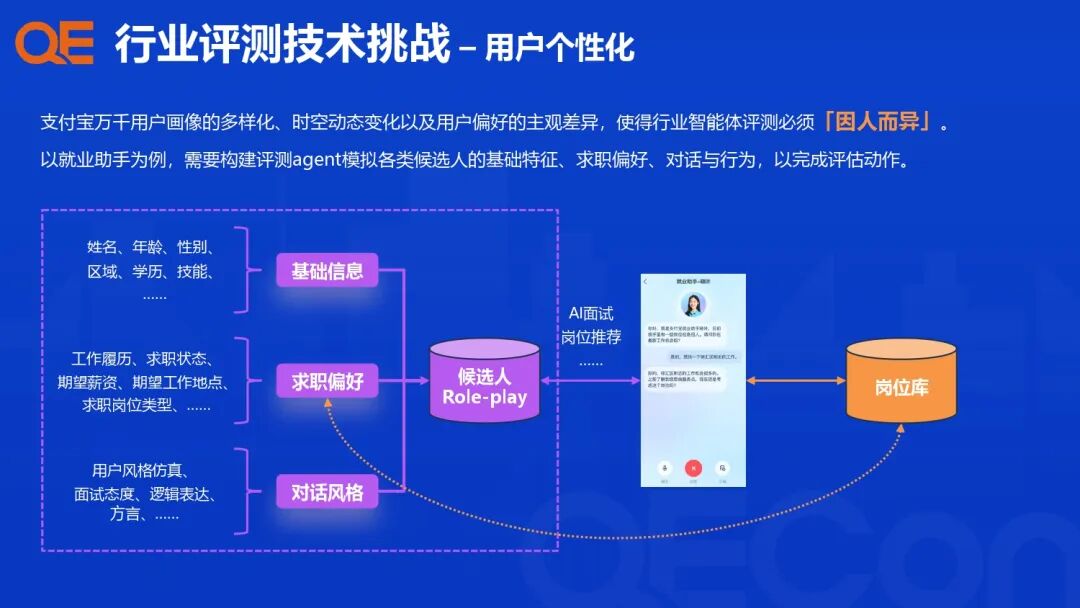
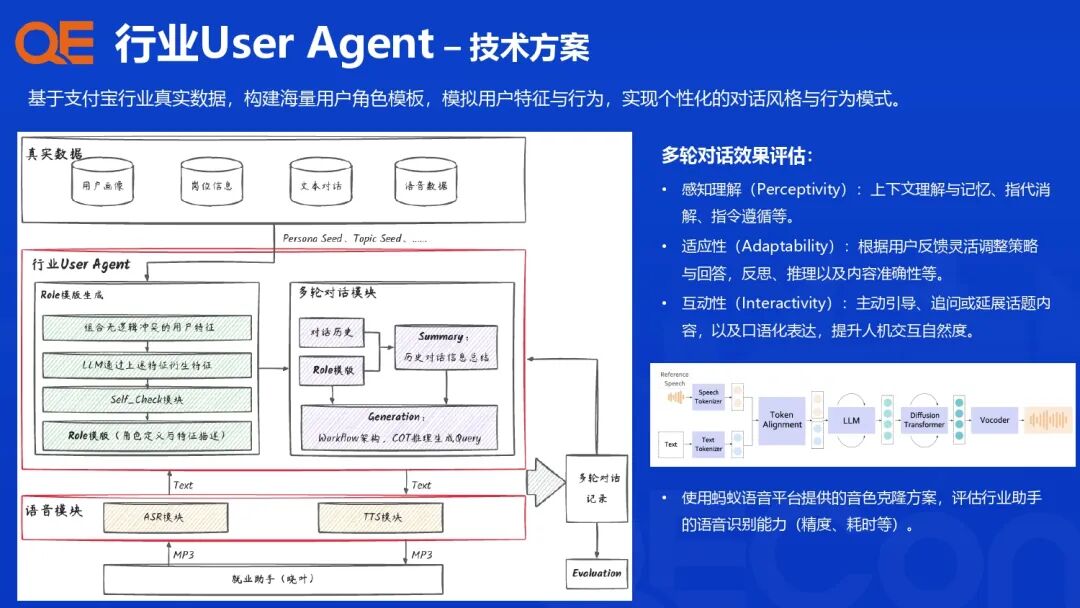
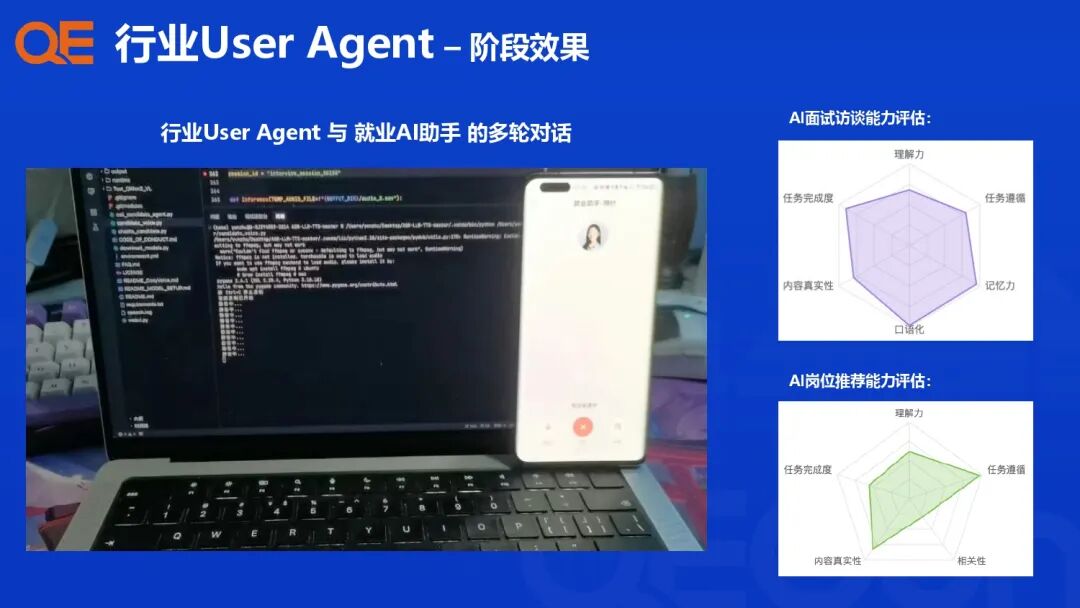
为了解决用户个性化和复杂多轮任务的挑战,支付宝构建了行业 User Agent,用于在真实世界或沙盒环境模拟用户特征和行为,进行个性化评测。
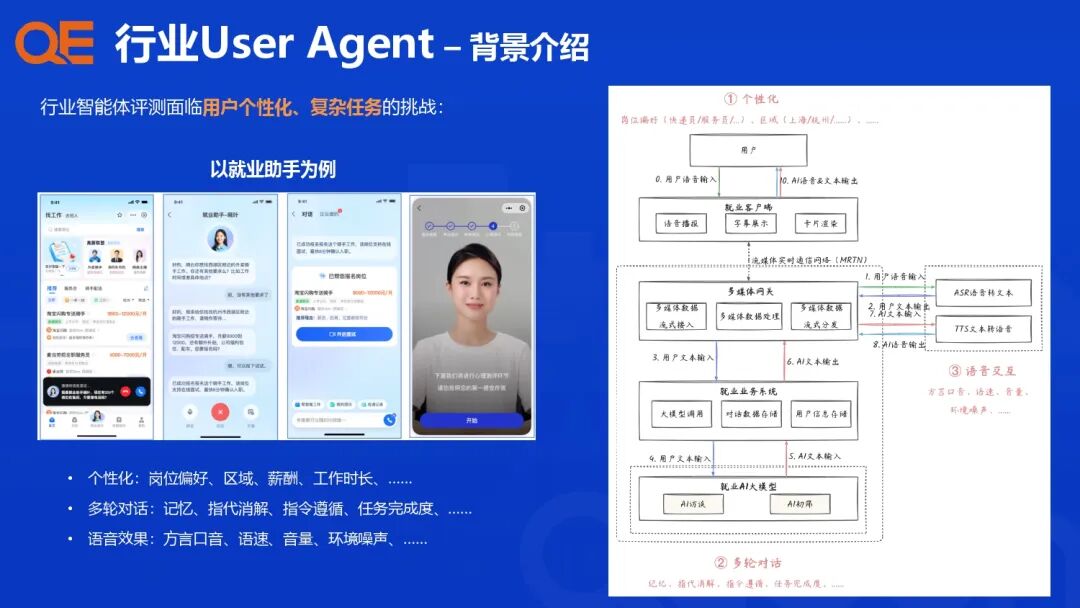
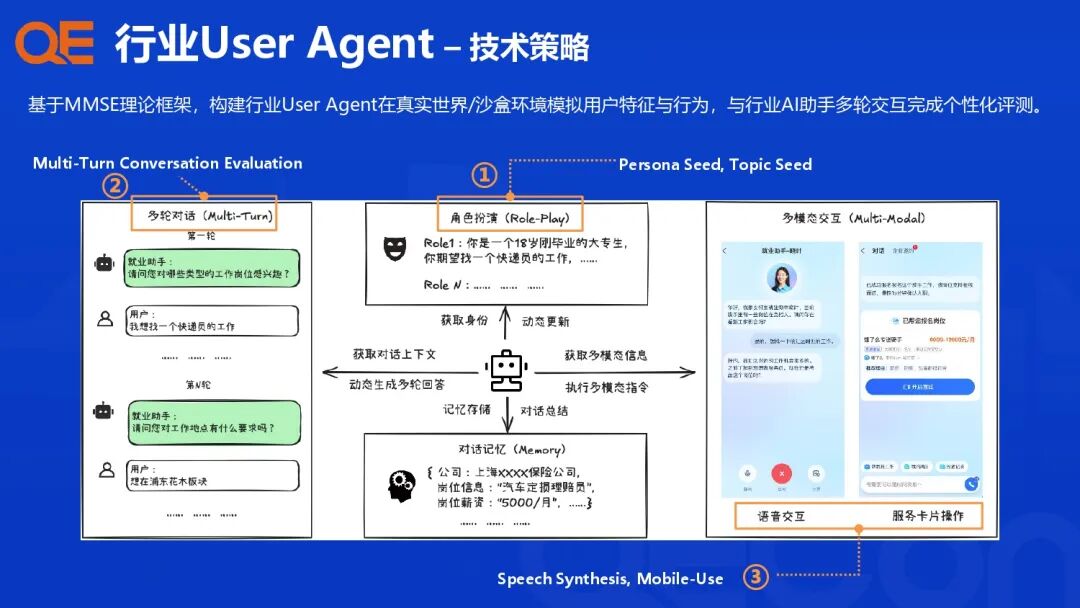
-
理论基础: 基于 MMSE 理论框架构建。
-
角色模拟: 基于支付宝行业真实数据,构建海量用户角色模板(Persona Seed, Topic Seed),模拟用户的个性化偏好(区域、薪酬、岗位)和行为模式(Speech Synthesis, Mobile-Use)。
-
多轮对话评估: 评估关注以下核心能力:
-
感知理解(Perceptivity): 上下文理解、记忆、指代消解、指令遵循。
-
适应性(Adaptability): 根据用户反馈灵活调整、反思、推理和内容准确性。
-
互动性(Interactivity): 主动引导、追问或延展话题,提升交互自然度。
-
-
语音效果: 利用蚂蚁语音平台的音色克隆方案,评估行业助手的语音识别能力。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









