







一、VGG-16模型简介
经典卷积神经网络的基本组成部分是下面的这个序列:
(1)带填充以保持分辨率的卷积层; (2)非线性激活函数,如ReLU; (3)池化层,最大池化层。
而一个VGG块与之类似,由一系列卷积层组成,后面再加上用于空间下采样的最大池化层。
VGG特点: vgg-block内的卷积层都是同结构的 池化层都得上一层的卷积层特征缩减一半 深度较深,参数量够大
来源:B站up主 【炮哥带你学】
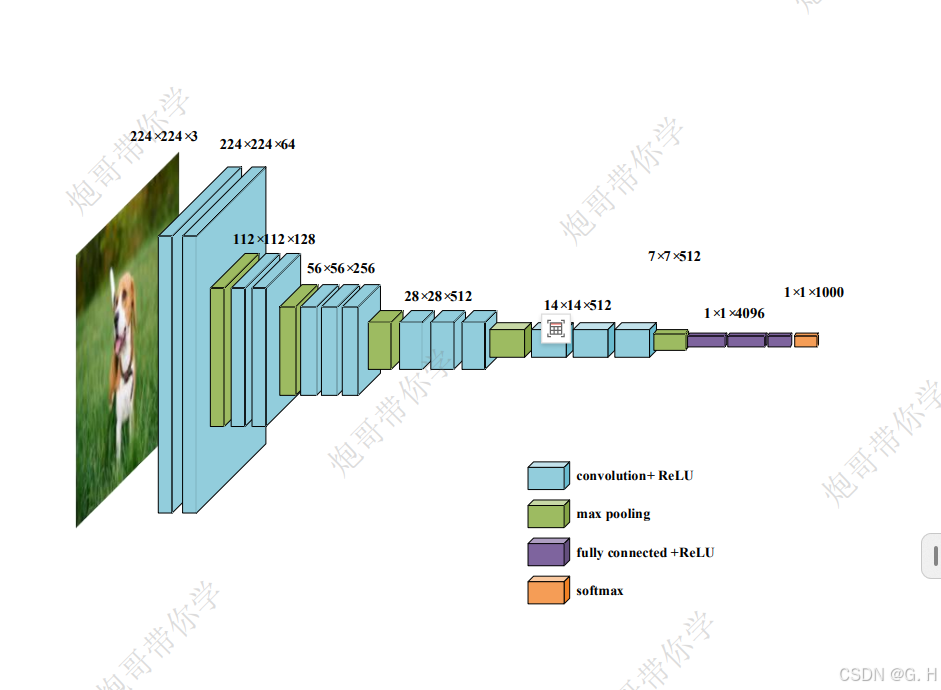
网络参数结构示意图(其中conv3-256表示:这是一个卷积层,卷积核尺寸为3×3,通道数为256)
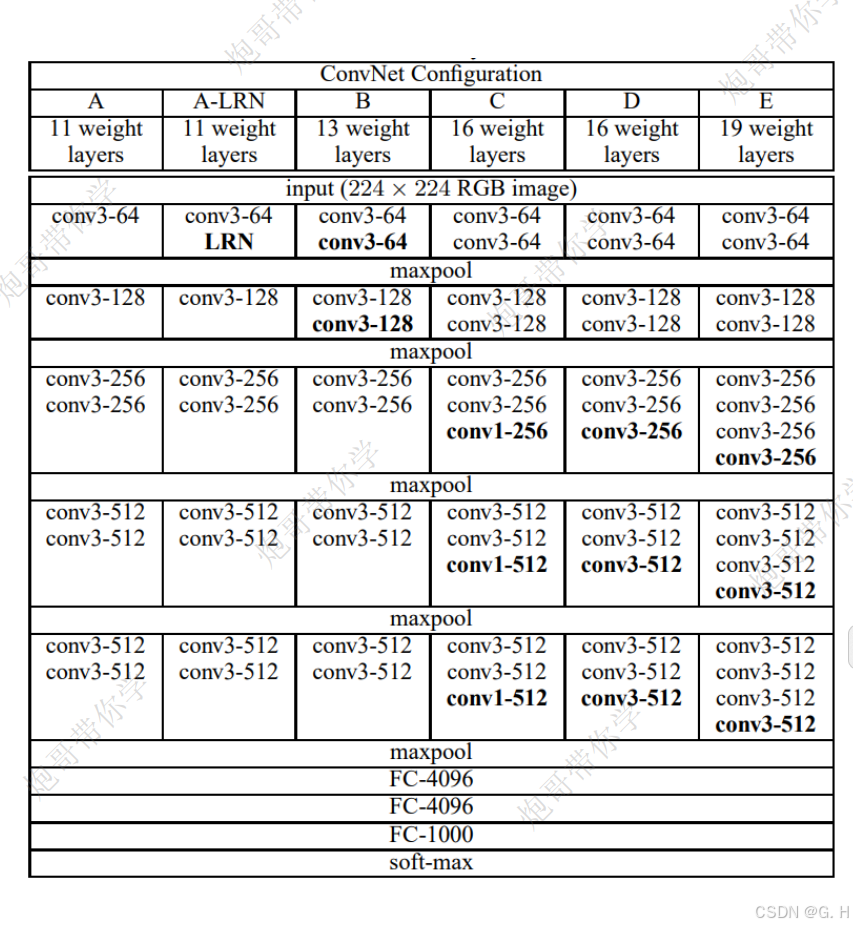
不同VGG版本对应的参数:
VGG共有6个模型,A是VGG11 B是VGG13参数个数都是1.33亿,C是VGG16也就是我们本次搭建的,参数个数为1.34亿,E是VGG19参数个数是1.44亿

总结:
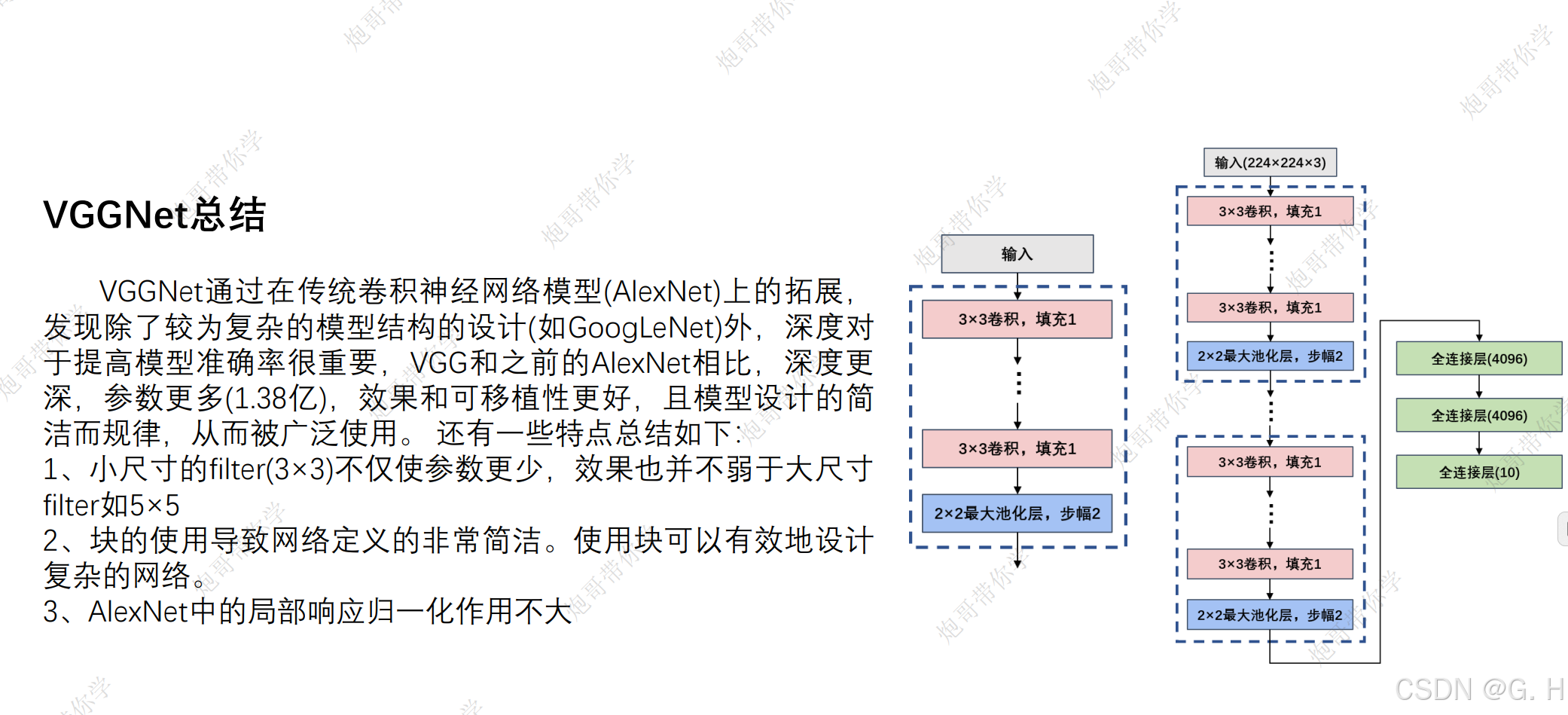
二、模型搭建
import torch
from torch import nn
from torchsummary import summary
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.block1 = nn.Sequential(
#卷积 -> 激活函数 卷积 -> 激活函数
#步幅为1这个参数可以省略不写 默认为1 填充为1这个参数要写
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(),
#最大池化
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block6 = nn.Sequential(
#全连接之前先进行展平
nn.Flatten(),
nn.Linear(7 * 7 * 512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
#权重初始化!!!
for m in self.modules():
# 这一行代码使用self.modules()方法遍历了神经网络模型self中的所有模块。
# self.modules()是一个生成器,它会递归地遍历模型中的所有层(包括子模块、子层等),并返回它们的引用。
# 对于卷积层的初始化
if isinstance(m, nn.Conv2d):
# 对于每一个模块m,代码首先检查它是否是nn.Conv2d类型,即二维卷积层。如果是,那么执行以下操作:
# 对于权重参数 w进行初始化
nn.init.kaiming_normal_(m.weight, nonlinearity='relu')
# 对于偏置 b 进行初始化
if m.bias is not None:
# 如果卷积层有偏置项m.bias(不是所有卷积层都有偏置项,这取决于在创建层时是否指定了bias = True),则使用nn.init.constant_函数将其初始化为0
nn.init.constant_(m.bias, 0)
# 对于全连接层的初始化 mean是平均值 std是方差
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
return x
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VGG16().to(device)
print(summary(model, (1, 224, 224)))
if __name__=="__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VGG16().to(device)
print(summary(model, (1, 224, 224)))注意VGG16的模型搭建和之前的LetNet-6以及AlexNet的网络搭建有所不同:
1.我们把这些层分成一个个的块,只需要在每个块内部按顺序排列好各个参数层,然后直接调用块进行卷积运算就可以了 ,调用块的时候就会按照块中的顺序执行下来
2.除此之外还有一块代码是进行权重初始化,也就是对权重w和偏置b进行初始化,可是为什么要这样呢,在之前的两个网络中为什么没有这部分代码呢?
第一个原因就是之前学习的网络深度是比较浅的,在神经网络中,尤其是当网络结构较深时,如果所有权重都被初始化为相同的值,那么在训练开始时,所有神经元的行为将会是相同的。这会导致网络学习到相同的特征,从而无法充分利用网络的深度和宽度。通过初始化权重为不同的值,可以确保每个神经元在训练开始时就能学习到不同的特征。
第二个原因就是如果权重初始化为过大或过小的值,可能会导致在反向传播过程中梯度消失或爆炸。梯度消失意味着权重更新变得非常小,导致网络学习非常缓慢;而梯度爆炸则可能导致权重更新过大,使得网络无法稳定学习。
合适的权重初始化可以使得模型在训练初期就接近一个较好的状态,从而加速训练过程。例如,使用Kaiming初始化(也称为He初始化)时,它考虑了ReLU激活函数的特点,使得每一层的输出方差保持不变,这有助于维持梯度的稳定性,从而加快训练速度
但是仅仅注意要权重初始化,根据炮哥视频中的讲解,当没有进行权重初始化的时候,他先是在6G的显存上训练批次为12的数据集,效果不好,当换到24G显存训练批次为64的时候效果也不好,但当进行以上的权重初始化的时候,后者效果就变好了,但是前者效果依旧不好,又接着把24G显存上的批次换为12,效果不好,此时分析训练效果应该与批次(batch_size)也有关
为什么会与批次有关呢?
-
批次统计量的不稳定性:
当批次很小时,批次统计量(如均值和方差)会变得非常不稳定。这些统计量在批归一化(Batch Normalization)等过程中起着关键作用,用于标准化输入数据,使其具有一致的分布。不稳定的统计量会导致模型训练过程中的不稳定,从而影响收敛性。 -
训练过程中的梯度波动:
小的批次可能导致梯度在每次迭代中波动较大。这种波动可能使得模型在训练过程中难以找到稳定的下降方向,从而导致收敛速度缓慢甚至不收敛。 -
模型泛化能力的下降:
虽然小的批次有助于模型更好地泛化到未见过的数据(通过引入更多的随机性),但当批次太小以至于无法提供足够的信息来更新模型参数时,模型的泛化能力可能会下降。这可能导致模型在训练集上表现良好,但在测试集上表现不佳。
所以既要关注权重初始化,也要关注训练集批次大小,训练批次不能太小,但是矛盾又来了,本来我是显存是6G跑批次为12的数据就特别慢,要是跑批次为32的还不要卡死啊,这里为了让数据跑通,我们可以对全连接层的中间几层的输入输出进行调整(因为绝大部分的参数都集中在线性全连接层,虽然论文中模型的参数是4096,但是对于我们练习代码这个结果只有十分类的数据来说,根本用不着那么多参数),把代码参数改一下:
把:
self.block6 = nn.Sequential(
#全连接之前先进行展平
nn.Flatten(),
nn.Linear(7 * 7 * 512, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, 10),
)
改为:
self.block6 = nn.Sequential(
#全连接之前先进行展平
nn.Flatten(),
nn.Linear(7 * 7 * 512, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 10),
)这样改完运行发现效果就好了很多
三、模型训练+测试
import copy
import time
import torch
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import torch.utils.data as Data
import numpy as np
import matplotlib.pyplot as plt
from model import VGG16
import torch.nn as nn
import pandas as pd
def train_val_data_process():
train_data = FashionMNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]),
download=True)
train_data, val_data = Data.random_split(train_data, [round(0.8*len(train_data)), round(0.2*len(train_data))])
train_dataloader = Data.DataLoader(dataset=train_data,
batch_size=28,
shuffle=True,
num_workers=2)
val_dataloader = Data.DataLoader(dataset=val_data,
batch_size=28,
shuffle=True,
num_workers=2)
return train_dataloader, val_dataloader
def train_model_process(model, train_dataloader, val_dataloader, num_epochs):
# 设定训练所用到的设备,有GPU用GPU没有GPU用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 使用Adam优化器,学习率为0.001
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 损失函数为交叉熵函数
criterion = nn.CrossEntropyLoss()
# 将模型放入到训练设备中
model = model.to(device)
# 复制当前模型的参数
best_model_wts = copy.deepcopy(model.state_dict())
# 初始化参数
# 最高准确度
best_acc = 0.0
# 训练集损失列表
train_loss_all = []
# 验证集损失列表
val_loss_all = []
# 训练集准确度列表
train_acc_all = []
# 验证集准确度列表
val_acc_all = []
# 当前时间
since = time.time()
for epoch in range(num_epochs):
print("Epoch {}/{}".format(epoch, num_epochs-1))
print("-"*10)
# 初始化参数
# 训练集损失函数
train_loss = 0.0
# 训练集准确度
train_corrects = 0
# 验证集损失函数
val_loss = 0.0
# 验证集准确度
val_corrects = 0
# 训练集样本数量
train_num = 0
# 验证集样本数量
val_num = 0
# 对每一个mini-batch训练和计算
for step, (b_x, b_y) in enumerate(train_dataloader):
# 将特征放入到训练设备中
b_x = b_x.to(device)
# 将标签放入到训练设备中
b_y = b_y.to(device)
# 设置模型为训练模式
model.train()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 将梯度初始化为0
optimizer.zero_grad()
# 反向传播计算
loss.backward()
# 根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值的作用
optimizer.step()
# 对损失函数进行累加
train_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确度train_corrects加1
train_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于训练的样本数量
train_num += b_x.size(0)
for step, (b_x, b_y) in enumerate(val_dataloader):
# 将特征放入到验证设备中
b_x = b_x.to(device)
# 将标签放入到验证设备中
b_y = b_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为一个batch,输出为一个batch中对应的预测
output = model(b_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 计算每一个batch的损失函数
loss = criterion(output, b_y)
# 对损失函数进行累加
val_loss += loss.item() * b_x.size(0)
# 如果预测正确,则准确度train_corrects加1
val_corrects += torch.sum(pre_lab == b_y.data)
# 当前用于验证的样本数量
val_num += b_x.size(0)
# 计算并保存每一次迭代的loss值和准确率
# 计算并保存训练集的loss值
train_loss_all.append(train_loss / train_num)
# 计算并保存训练集的准确率
train_acc_all.append(train_corrects.double().item() / train_num)
# 计算并保存验证集的loss值
val_loss_all.append(val_loss / val_num)
# 计算并保存验证集的准确率
val_acc_all.append(val_corrects.double().item() / val_num)
print("{} train loss:{:.4f} train acc: {:.4f}".format(epoch, train_loss_all[-1], train_acc_all[-1]))
print("{} val loss:{:.4f} val acc: {:.4f}".format(epoch, val_loss_all[-1], val_acc_all[-1]))
if val_acc_all[-1] > best_acc:
# 保存当前最高准确度
best_acc = val_acc_all[-1]
# 保存当前最高准确度的模型参数
best_model_wts = copy.deepcopy(model.state_dict())
# 计算训练和验证的耗时
time_use = time.time() - since
print("训练和验证耗费的时间{:.0f}m{:.0f}s".format(time_use//60, time_use%60))
# 选择最优参数,保存最优参数的模型
model.load_state_dict(best_model_wts)
# torch.save(model.load_state_dict(best_model_wts), "C:/Users/86159/Desktop/LeNet/best_model.pth")
torch.save(best_model_wts, "./best_model.pth")
train_process = pd.DataFrame(data={"epoch":range(num_epochs),
"train_loss_all":train_loss_all,
"val_loss_all":val_loss_all,
"train_acc_all":train_acc_all,
"val_acc_all":val_acc_all,})
return train_process
def matplot_acc_loss(train_process):
# 显示每一次迭代后的训练集和验证集的损失函数和准确率
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process['epoch'], train_process.train_loss_all, "ro-", label="Train loss")
plt.plot(train_process['epoch'], train_process.val_loss_all, "bs-", label="Val loss")
plt.legend()
plt.xlabel("epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(train_process['epoch'], train_process.train_acc_all, "ro-", label="Train acc")
plt.plot(train_process['epoch'], train_process.val_acc_all, "bs-", label="Val acc")
plt.xlabel("epoch")
plt.ylabel("acc")
plt.legend()
plt.show()
if __name__ == '__main__':
# 加载需要的模型
VGG16 = VGG16()
# 加载数据集
train_data, val_data = train_val_data_process()
# 利用现有的模型进行模型的训练
train_process = train_model_process(VGG16, train_data, val_data, num_epochs=20)
matplot_acc_loss(train_process)运行结果
(我租的是AutoDL上面的2080Ti的GPU,好慢好慢,出去跑了步回来才训练了13轮次。。。。然后没跑完我就停止了,应该是没什么问题,有条件的可以用4090)

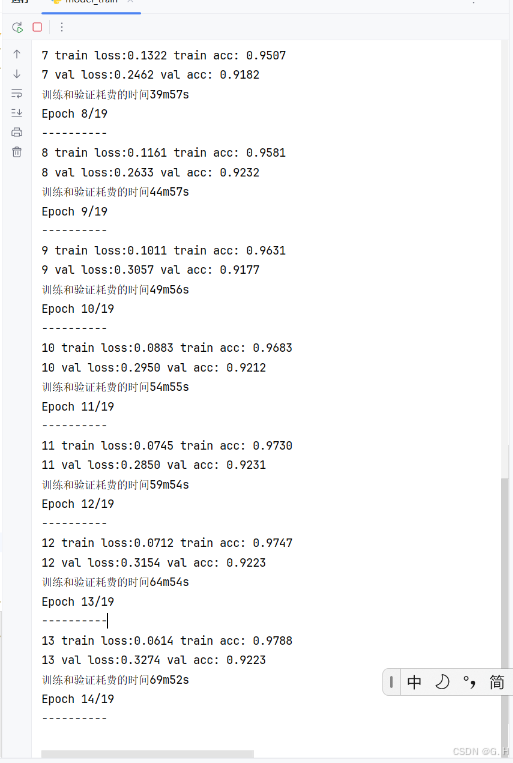
内存占用数据
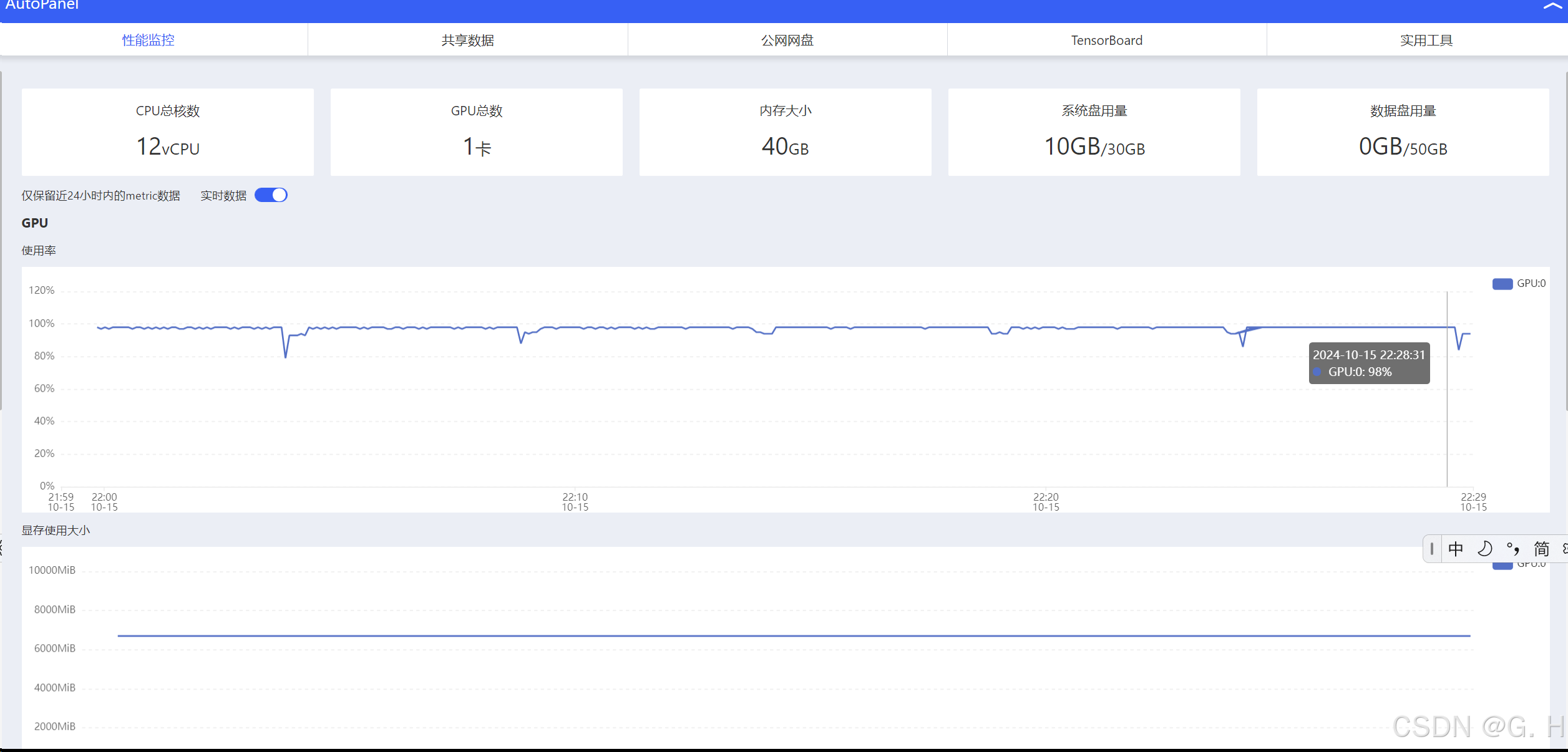
四、推理验证
import torch
import torch.utils.data as Data
from torchvision import transforms
from torchvision.datasets import FashionMNIST
from model import VGG16
def test_data_process():
test_data = FashionMNIST(root='./data',
train=False,
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]),
download=True)
test_dataloader = Data.DataLoader(dataset=test_data,
batch_size=1,
shuffle=True,
num_workers=0)
return test_dataloader
def test_model_process(model, test_dataloader):
# 设定测试所用到的设备,有GPU用GPU没有GPU用CPU
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 讲模型放入到训练设备中
model = model.to(device)
# 初始化参数
test_corrects = 0.0
test_num = 0
# 只进行前向传播计算,不计算梯度,从而节省内存,加快运行速度
with torch.no_grad():
for test_data_x, test_data_y in test_dataloader:
# 将特征放入到测试设备中
test_data_x = test_data_x.to(device)
# 将标签放入到测试设备中
test_data_y = test_data_y.to(device)
# 设置模型为评估模式
model.eval()
# 前向传播过程,输入为测试数据集,输出为对每个样本的预测值
output= model(test_data_x)
# 查找每一行中最大值对应的行标
pre_lab = torch.argmax(output, dim=1)
# 如果预测正确,则准确度test_corrects加1
test_corrects += torch.sum(pre_lab == test_data_y.data)
# 将所有的测试样本进行累加
test_num += test_data_x.size(0)
# 计算测试准确率
test_acc = test_corrects.double().item() / test_num
print("测试的准确率为:", test_acc)
if __name__ == "__main__":
# 加载模型
model = VGG16()
model.load_state_dict(torch.load('best_model.pth'))
# # 利用现有的模型进行模型的测试
test_dataloader = test_data_process()
test_model_process(model, test_dataloader)
# 设定测试所用到的设备,有GPU用GPU没有GPU用CPU
device = "cuda" if torch.cuda.is_available() else 'cpu'
model = model.to(device)
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
with torch.no_grad():
for b_x, b_y in test_dataloader:
b_x = b_x.to(device)
b_y = b_y.to(device)
# 设置模型为验证模型
model.eval()
output = model(b_x)
pre_lab = torch.argmax(output, dim=1)
result = pre_lab.item()
label = b_y.item()
print("预测值:", classes[result], "------", "真实值:", classes[label])

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









