



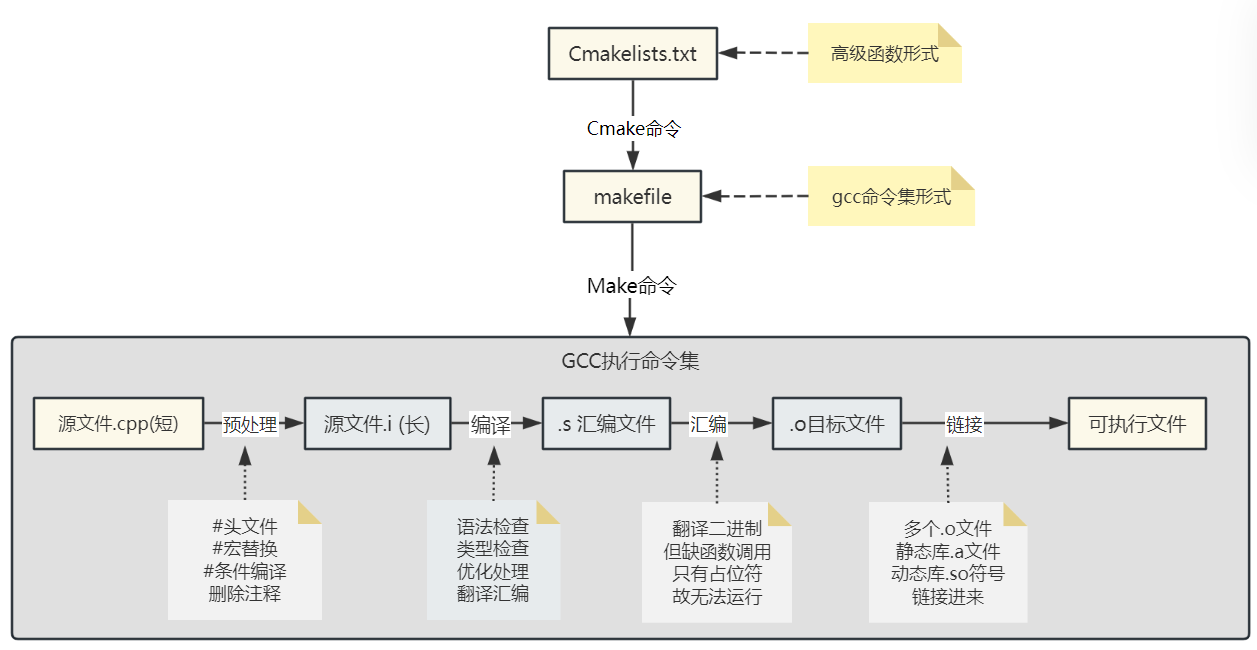
编译过程与工具
内存空间
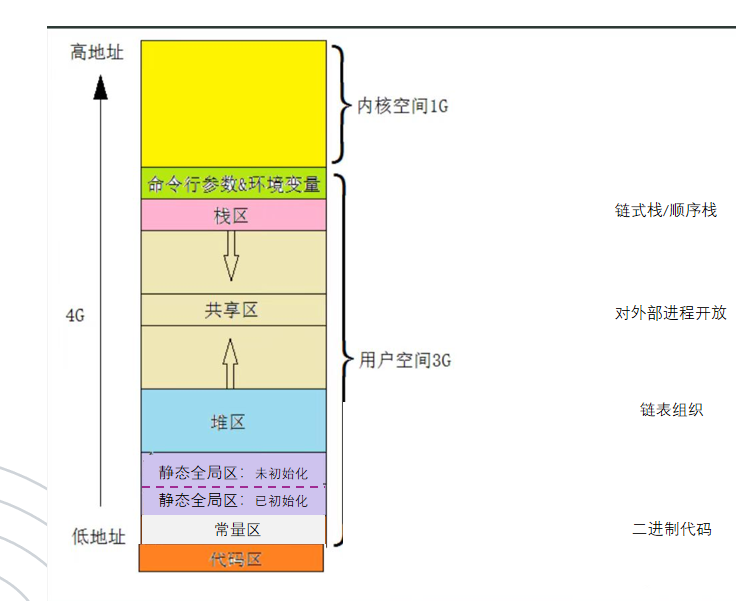
栈:由编辑器管理分配和回收,存放局部变量和函数参数(函数或循环内如蜉蝣朝生暮死)
堆:由程序员管理分配和回事,空间大但是可能有内存泄漏和空闲碎片的情况
静态/全局区:存储初始化和未初始化的静态(局部暴露)/全局变量(全域暴露)
常量存储区:存储常量,一般不允许修改
代码区:存放程序的二进制代码
STL与数据结构
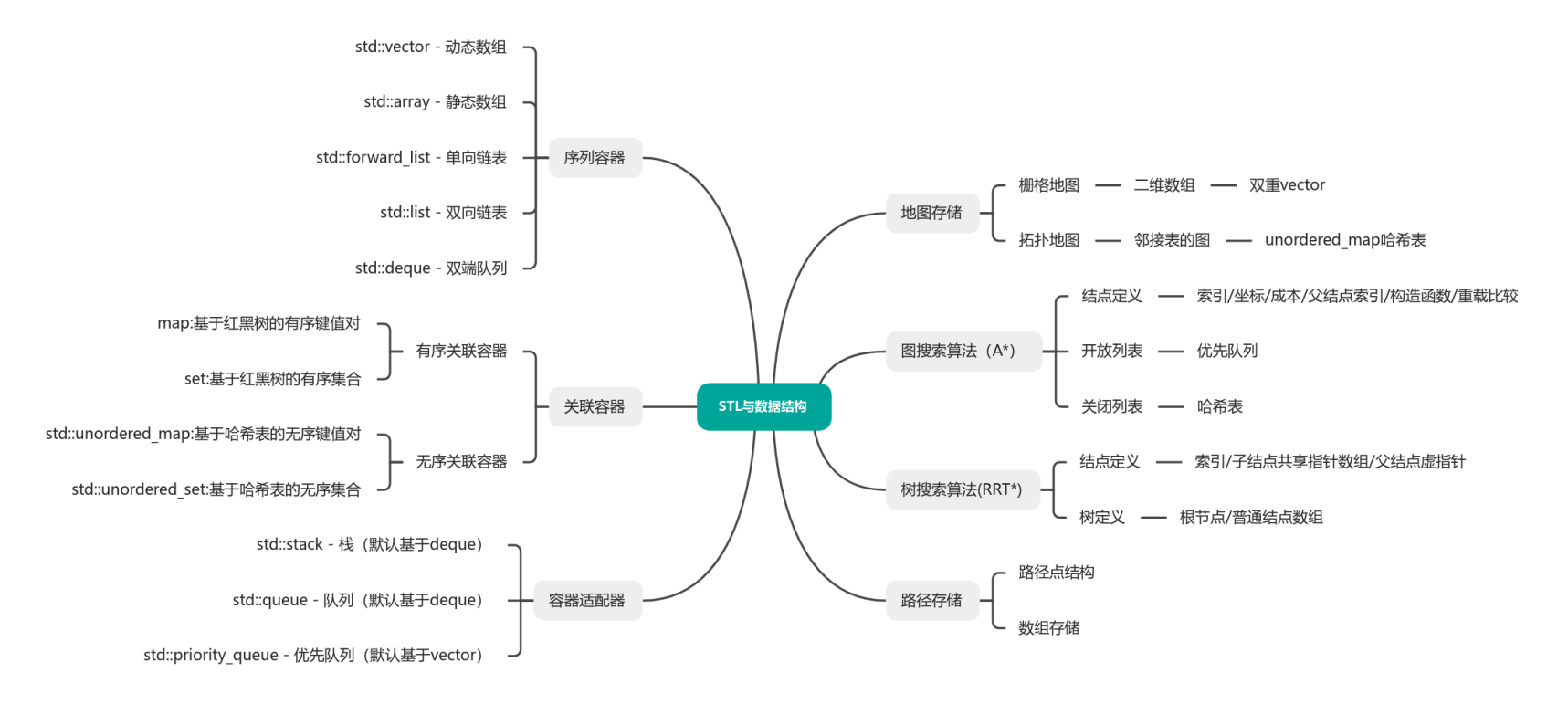
下面我将以序列容器的vector,关联容器的哈希映射,容器适配器的优先队列为例实战
红黑树和AVL树的查询,插入/删除操作量级都是o(log2^n)。但是两者略有差异(常量上),AVL树查询快一点(绝对平衡,树更矮),而红黑树的更新更快一点,因为旋转操作只有一两次,AVL树则要旋转到顶层
但是没有看到什么路径规划算法必须使用有序关联容器
-
✅ 排序需求被
priority_queue更好地满足 -
✅ 查找性能要求倾向于
unordered_map
也就是说对于互联网后端工程师来说用的比较多吗,和数据库打交道的那种
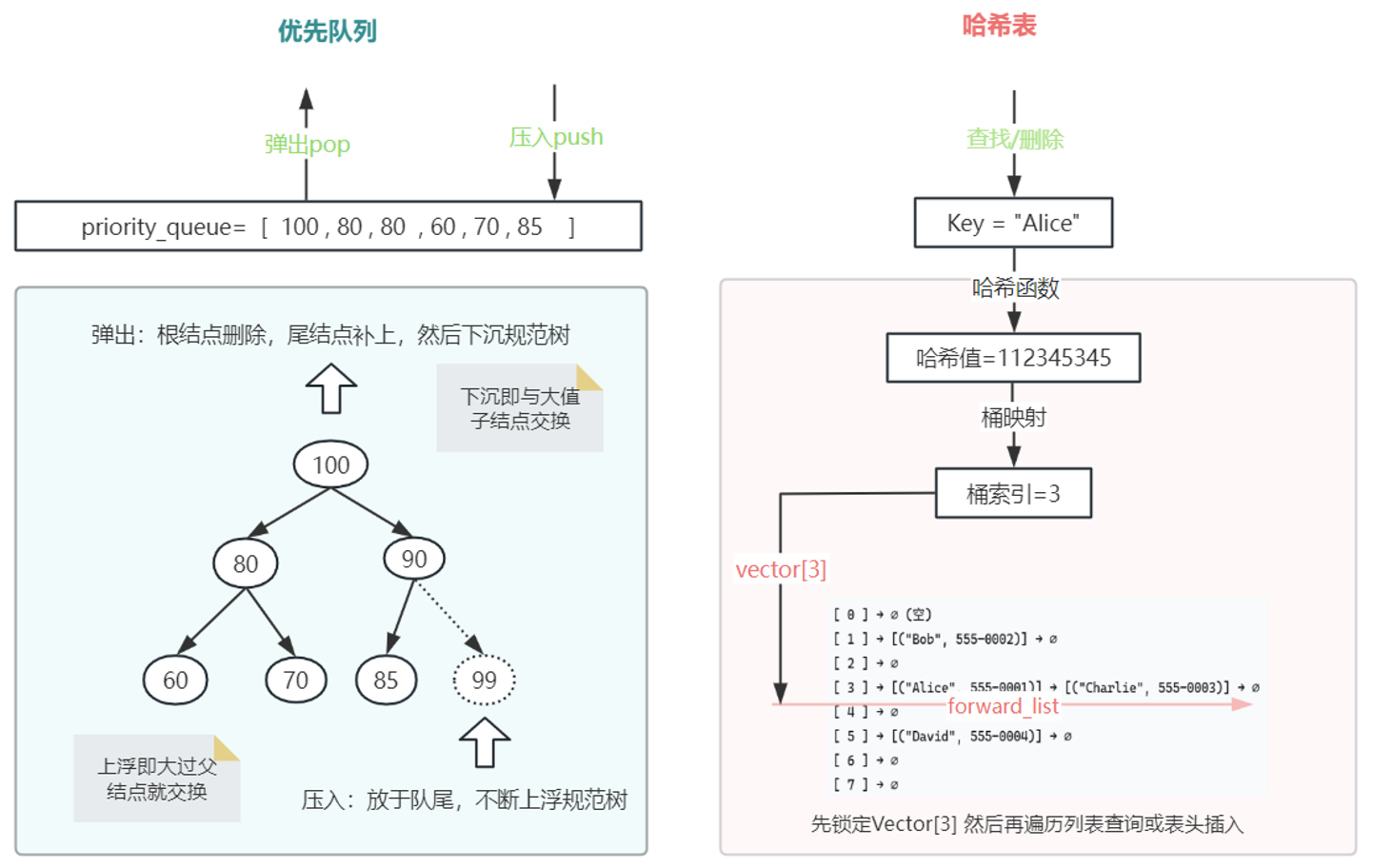
// Node节点
struct Node {
int id;
double f_cost; // f = g + h
int parent_id; // 添加父节点信息
Node(int id, double g, double h, int parent = -1)
: id(id), g_cost(g), h_cost(h), f_cost(g + h), parent_id(parent) {}
bool operator>(const Node& other) const {
return f_cost > other.f_cost;
}
};
// 树结点
struct RRTNode {
int id;
double x, y; // 坐标
std::vector<std::shared_ptr<RRTNode>> children; //一大堆子结点
std::weak_ptr<RRTNode> parent; // 一个父结点 使用weak_ptr避免循环引用
RRTNode(int id, double x, double y) : id(id), x(x), y(y) {}
};
// 树结构
class RRTTree {
public:
std::shared_ptr<RRTNode> root;
std::unordered_map<int, std::shared_ptr<RRTNode>> nodes; // 所隐藏查结点
语言特性
1.与Python区别
2.与C区别
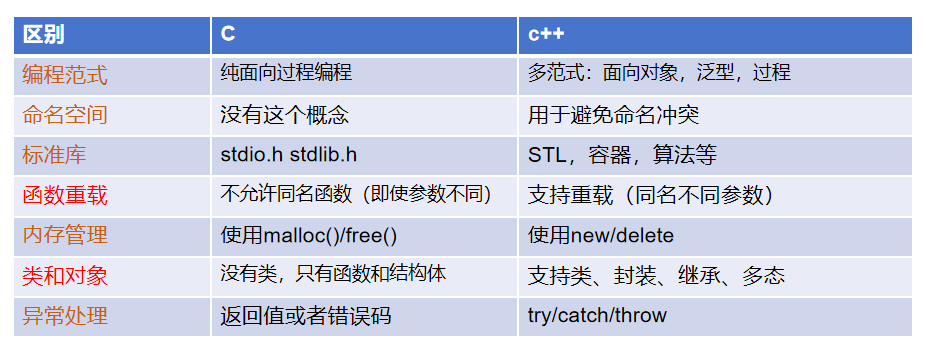
更复用,更多态,更动态,更健壮
1.C没有的命名空间
// C++
namespace MyLib {
void print() { cout << "MyLib version"; }
}
// 使用
MyLib::print();
// C语言通常通过前缀区分
void mylib_print() {...}
2.C没有的面向对象编程
C++定义类:属性+构造方法+功能方法 C:结构体+函数
3.C没有的STL标准模板库
#include <vector>
#include <string>
#include <algorithm>
vector<string> names = {"Alice", "Bob"};
names.push_back("Charlie"); // 动态扩容
sort(names.begin(), names.end()); // 排序
// C语言需手动实现动态数组和排序
是一个C++程序库,包含了诸多常用基本数据结构和基本算法,
基于泛型思想设计,其中的一种算法大多数适用于多种数据结构
容器、算法、迭代器、仿函数、适配器、分配器
六大组件中,最主要的是容器,迭代器和算法三个部分
数据由容器管理,而操作由算法执行,迭代器充当两者桥梁,遍历和访问容器元素
迭代器服务于所有的容器,注定了它适用范围广,不像指针只能针对连续物理内容元素
序列式容器:向量 双端队列 列表
关联式容器:集合 多重集合 映射 多重映射
无关联式容器
4没有构造函数与析构函数
构造规范与使用时刻
class MyClass
{
public:
//构造函数:名称要求-不能有返回值-可以重载
// 默认构造函数
MyClass(){};
// 带参数的构造函数
MyClass(int x);
// 拷贝构造函数
MyClass(const MyClass& other);
//析构函数:名称要求-不能有返回值-不能重载-不能带参数
~MyClass() { cout << "析构函数调用" << endl; }
//!当类可能被派生时,必须虚析构,否则派生类的析构可能无法调用
};
void testFunction() {
MyClass obj; // 进入作用域,构造函数调用
} // 离开作用域,析构函数自动调用
int main() {
testFunction(); // obj 在这里创建并销毁
return 0;
}
如果未定义,编译器会自动创建“构造函数和析构函数”
6.C没有的引用
引用是空间的别名,指针是空间的邻居
int x = 10;
// C++ 引用(别名)
int& ref = x; // ref是x的引用
ref = 20; // 直接修改x
// C语言只能用指针
int *ptr = &x;
*ptr = 20;
7.C没有的动态内存
真服了,太多了,太多案例,只申请不释放的了
int* p = new int(10); // 动态分配内存
delete p; // 必须手动释放
8.C没有的异常处理
// C++捕捉异常并进行处理
try {
if (age < 0) throw runtime_error("Invalid age");
} catch (const exception& e) {
cerr << e.what();
}
// C语言只能返回错误码
int set_age(int a) {
if (a < 0) return -1; // 错误码
return 0;
}
指针
1.智能指针
C++11引入的自动管理动态分配的内存,避免内存泄漏 (可用内存一直减少,因为部分被借了不还)
该文件是一个结点,功能是打印hello
# include "rclcpp/rclcpp.hpp"
int main(int argc,char **argv)
{
rclcpp::init(argc,argv)
auto node = std::make_shared<rclcpp::Node>("cpp_node");
}
最好做张图把四个都涵盖进去。
(1) auto_ptr (已经弃用)
(2)unique_ptr (独占对象)
独占性:同时段仅一个unique_ptr指针指向对象地址,不能够被复制成多份,但是可以移交权力
(3)shared_ptr (共享对象)
共享性:可有多shared_ptr管理同一区域,当大家都释放(即引用计数为0),就释放内存
(4)weak_ptr(观察对象)
它不拥有对象的所有权,但可以观察 shared_ptr 管理对象是否还存在,避免循环引用和悬空指针
类型 对象 函数
std::unique_ptr<int> unique_p = std::make_unique<int>(42); #创建独占指针
std::shared_ptr<int> shared_p = std::make_shared<int>(42); #创建共享指针
std::weak_ptr<int> weak_p = shared_p; #派生观察指针
2. 函数指针
int (*funcPtr)(int, int); // 声明一个指向“返回int,接受两个int参数”的函数的指针
// 目标函数
int add(int a, int b) { return a + b; }
//
int main() {
// 1. 为函数指针初始化
funcPtr = &add; // 或直接写 funcPtr = add;
// 2. 通过指针调用函数
int result = funcPtr(3, 5); // 等价于 add(3, 5)
cout << result;
}
借指针能够将函数作为参数传递给另一个函数,实现灵活函数嵌套
或者声明一个函数指针数组然后来存储一个函数表
3.常量指针
参数
2.普通参数vs指针参数
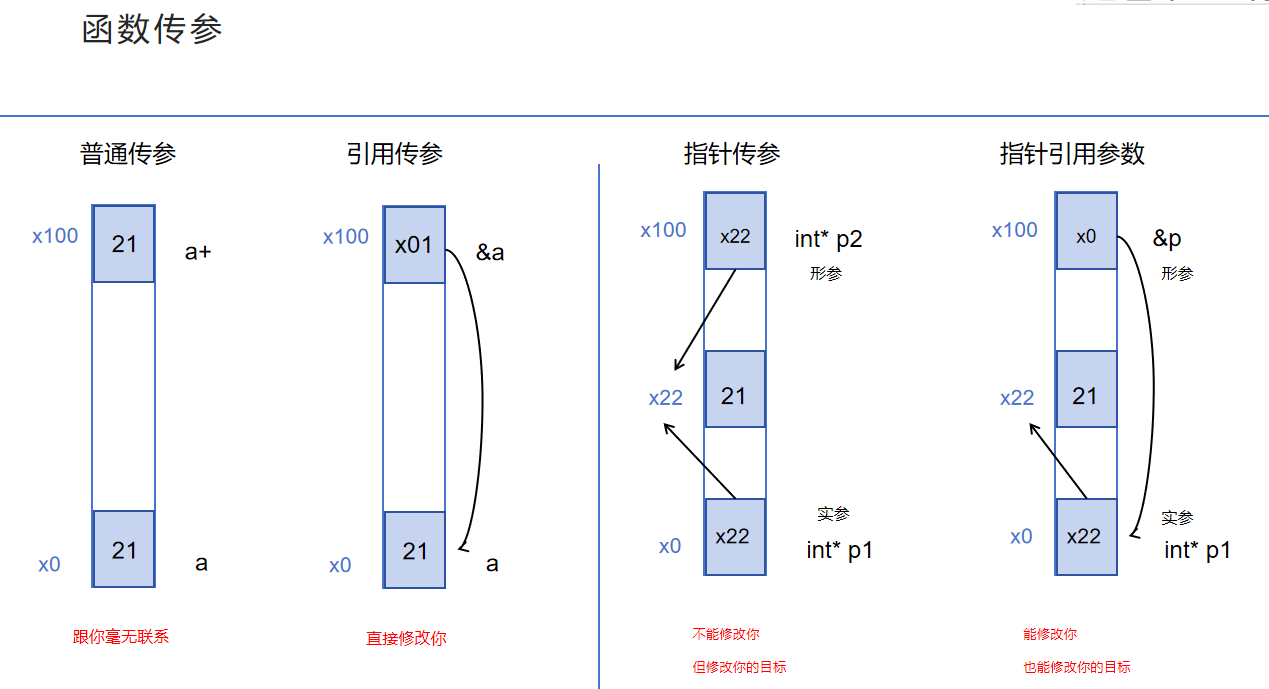
简单值传递:形参作为实参的拷贝,函数内部对形参操作并不影响实参
指针传递:也是值传递,实参指针——目标地址——>形参指针
引用传递;直接将形参与实参绑定一起,同生共死
《八股文篇章》
关键字
difine、const、static、typedef、inline、volatile、extern
//#define定义宏
#define PI 3.14159 // 定义宏常量,宏函数
//const声明常量
const int MAX_SIZE = 100; // 全局常量,局部常量
//static声明静态
static int count = 0; // 定义在函数中,类中,全局中
//typedef定义类型别名
typedef int* IntPtr; // 只针对类型
//inline声明内联
inline int square(int x) { // 针对简单且频繁函数
return x * x;
}
编译器会尝试将函数调用直接替换为函数体代码(类似宏展开),避免函数调用的压栈、跳转和返回等开销。
//volatile防止优化
volatile int sensorValue; // 针对频繁使用的变量
//extern引入其它文件变量
extern int globalVar; // 针对跨文件使用的变量
//new与malloc
int* p = new int(10); // C++申请空间
int* p = (int*)malloc(sizeof(int)); // C申请空间
new/delete 和 malloc/free
| 特性 | malloc/free(c) | new/delete(c++) |
| 返回类型 | void* - 需强制转换 | 自动匹配 |
| 过程差异 | 直接申请释放 | 调用构造/析构函数 |
| 失败行为 | 返回null | 抛出异常 |
8.三种强制转换

多态
1.编译时多态-静态多态
1.函数重载
2.运算符重载
# 返回类型 操作符(接收参数)
Vector operator+(const Vector& other) const
{
return Vector(x + other.x, y + other.y);
}
Vector v1(1, 2), v2(3, 4);
# 等价于v1.vector+(v2)方法的调用
Vector v3 = v1 + v2;
3.泛型编程
编译时,根据你实际传入的数值类型,自动的更换使用函数或者类中所有T
// 定义函数模板
template <typename T>
T max(T a, T b) {return a > b ? a : b;}
// 函数模板使用
int i = max(3, 5); // T被推导为int
double d = max(3.14, 2.72); // T被推导为double
// 定义类模板
template <typename T> // T 是类型参数
class ClassName {T data; void setData(T val) { data = val; } T getData() { return data;}
// 类模板使用
ClassName<int> intStack; //T全换成了Int
ClassName<std::string> strStack; //T全换成了String
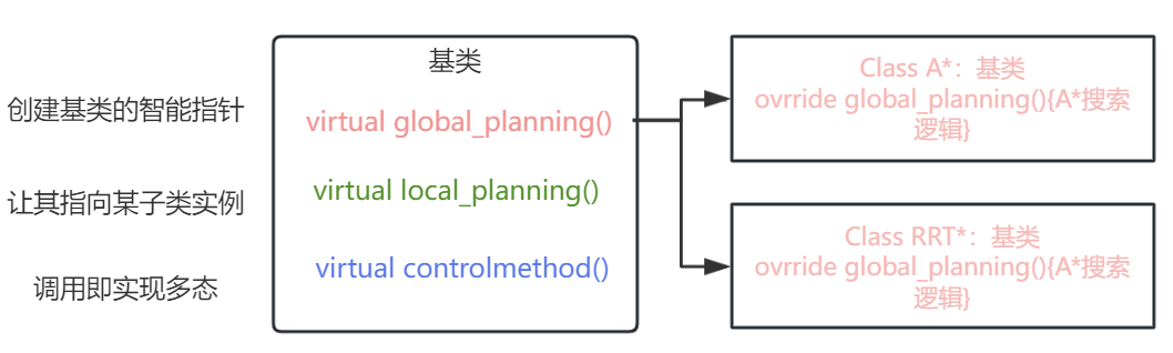
线程创建与线程同步
为什么讨论线程问题,不讨论进程问题?
因为在ros2中默认一个结点的启用就是一个进程的创建,除非你用component来组合结点们,那么这组结点就在一个进程内,自己变成了线程,结点间通信=进程间通信。
如何为节点创建线程?又如何解决线程同步问题?
ros2中本身是不断的事件发生,不断的通信与接收,不断地回调处理,错综复杂,连绵不断
在ros::spin()会持续监听当前节点(进程)中,所有事件并依次处理回调函数,这是单线程思想
方法一:ros::MultiThreadedSpinner(n) 创建包含n个线程的线程池
方法二:ros::AsyncSpinner()它异步地启动线程来处理回调,并且你可以控制它的启动和停止
1.线程创建
planning_thread_ = std::async(std::launch::async, &DWAPlanner::planningLoop, this);
costmap_thread_ = std::thread(&DWAPlanner::updateCostmap, this);
// 等待 costmap 线程
if (costmap_thread_.joinable()) {
costmap_thread_.join();
}
// 等待 planning 线程(如果存在)
if (planning_thread_.valid()) {
planning_thread_.wait(); // 等待 future 完成
}
1.线程同步
方案A-互斥锁
void safe_increment() {
// 某线程进入函数,创建 lock_guard,锁在就上锁并访问临界区,锁不在就等待锁
std::lock_guard<std::mutex> lock(g_mutex);
// 临界区开始:只有持有锁的线程能执行这里-读写操作
int temp = g_shared_data;
temp += 1;
std::this_thread::sleep_for(std::chrono::milliseconds(1)); // 模拟一些工作
g_shared_data = temp;
// 临界区结束
} // lock 变量离开作用域,析构函数被调用,自动解锁 g_mutex
方案B-读写锁-
-
允许多个线程同时读共享数据(读操作不修改数据,不会冲突)。
-
只允许一个线程写共享数据(写操作需要独占访问,避免数据竞争)。
-
读和写不能同时进行(读的时候不能写,写的时候不能读)。
-
那么有读锁的线程在读资源前会首先判断写锁值,没有线程占有写锁就能进行读。那么有写锁的线程在执行写操作前难道会判断是否共享锁无人占用,无人读的时候就能进行写操作
方案C-信号量
与互斥锁的区别在于,信号量可以是大于1的值,并且任何线程都能进行v操作,即使没有p过
std::binary_semaphore sem(1); // 初始值为1
sem.acquire(); // P操作(相当于加锁,计数器减一)
// 临界区代码
sem.release(); // V操作(相当于解锁,计数器加一)
方案D-原子操作
将变量声明为 std::atomic<T> 类型 ,之后该变量的读/写就不允许同时被多个线程访问了,傲娇
2.顺序依赖
方案A-条件变量
#include <mutex>
#include <condition_variable>
std::mutex mtx; // 互斥锁
std::condition_variable cv; // 条件变量
bool condition = false; // 共享条件(可以是任意复杂逻辑)
// 等待方代码
void waiting_thread() {
std::unique_lock<std::mutex> lock(mtx); // 必须用 unique_lock(可灵活解锁)
while (!condition) { // 必须用 while 检查条件(防止虚假唤醒)
cv.wait(lock); // 1. 释放锁 2. 阻塞等待 3. 被唤醒后重新获取锁
}
// 条件满足,执行任务...
}
// 通知方代码
void notifying_thread() {
{
std::lock_guard<std::mutex> lock(mtx); // 首先拿锁
condition = true; // 修改共享条件
} // 锁自动释放(RAII)
cv.notify_all(); // 唤醒所有等待线程
}
方案B-异步执行
往往一行代码就启动异步任务(单开线程去干某事),马上返回future变量,在未来用它获取结果
// 创建服务客户端
rclcpp::Client<srv_type>::SharedPtr client_ = create_client<srv_type>("service_name");
// 异步发送请求,返回 std::future
auto future_result = client_->async_send_request(request);
// 等待并获取结果
auto response = future_result.get();

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









