







目录
生成式大模型的评价是一个复杂且多维度的任务,其主要用于全面、准确地衡量模型的性能和质量。常见的评价指标包括困惑度、BLEU、ROUGE、BERTScore等。
1.困惑度
困惑度是衡量语言模型性能的一个重要指标,它反映了模型对文本的预测能力。直观上,困惑度越低,说明模型对文本的预测越准确,生成的文本越符合语言的真实分布。从信息论的角度来看,困惑度可以理解为对模型预测结果的不确定性的度量,不确定性越低,困惑度越小。
对于给定的文本序列w1,w2,⋯,wN,语言模型预测每个词wi在其上下文条件下出现的概率为P(wi∣w1,w2,⋯,wi−1),则困惑度的计算公式为:
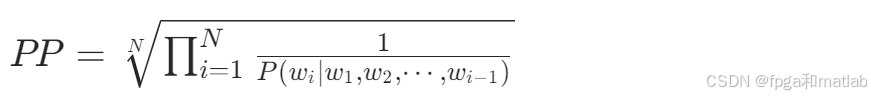
在实际计算中,通常使用对数形式来简化计算,即:
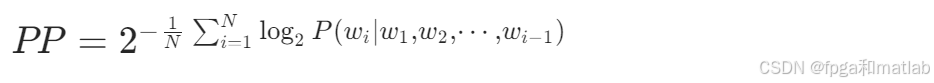
主要用于评估语言模型在给定语料上的表现,常用于自然语言生成任务,如文本生成、机器翻译等。较低的困惑度表示模型能够更好地拟合训练数据,生成更自然、合理的文本。
2.BLEU
BLEU是一种用于评估机器翻译质量的指标,它通过比较生成的翻译文本与参考翻译文本之间的n-gram重叠程度来衡量翻译的准确性。其基本思想是,如果生成的文本与参考文本在n-gram级别上有较高的重合度,那么该生成文本更接近参考文本,翻译质量也就越高。
BLEU的计算涉及到Precision(精确率)和 BP(Brevity Penalty,长度惩罚)两个部分。
Precision:计算生成文本中与参考文本匹配的n-gram的比例。对于每个n-gram,统计其在生成文本中出现的次数cn以及在参考文本中出现的次数rn,然后计算Precision为:
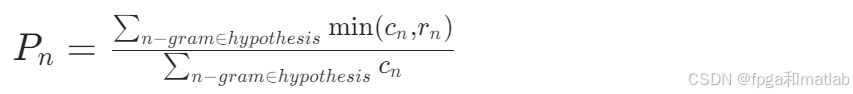
BP:用于惩罚生成文本过短的情况,其计算公式为:
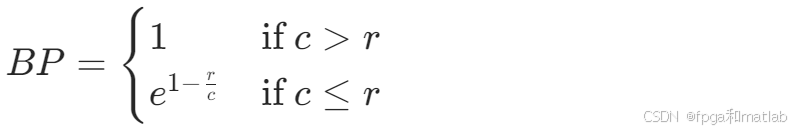
其中,c是生成文本的长度,r是参考文本的平均长度。
最终,BLEU指标的计算公式为:
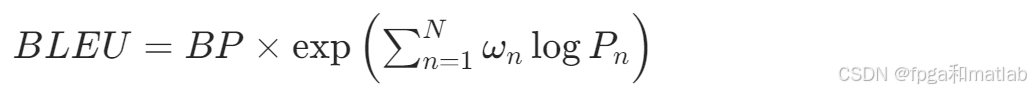
其中,ωn是不同n-gram的权重,通常取ωn=1/N,N是n-gram的最大阶数。
广泛应用于机器翻译领域,用于比较机器生成的翻译结果与人工翻译的参考结果之间的相似度,以评估机器翻译系统的性能。也可用于其他文本生成任务中,衡量生成文本与标准文本的相似程度。
3.ROUGE
ROUGE主要用于评估自动摘要系统生成的摘要质量,它基于召回率的思想,通过计算生成摘要与参考摘要之间的重叠单元(如n-gram、词块等)的比例来衡量摘要的质量。与BLEU不同,ROUGE更侧重于衡量生成摘要能够覆盖参考摘要的重要信息的程度。ROUGE有多种变体,常见的有ROUGE-N、ROUGE-L等。

其中,LCS(C,S)是生成摘要C和参考摘要S之间的最长公共子序列的长度,∣C∣是生成摘要的长度。
在自动文本摘要任务中被广泛使用,用于评估生成的摘要与人工撰写的参考摘要之间的相似性和信息覆盖程度。也可用于其他一些涉及文本内容比较和评估的任务,如问答系统的答案评估等。
4.BERTScore
BERTScore是一种基于预训练语言模型BERT的评价指标,它利用BERT模型对文本的语义理解能力,通过比较生成文本和参考文本在语义空间中的相似度来评估生成质量。其核心思想是将文本映射到BERT模型的语义空间中,然后计算它们之间余弦相似度等指标来衡量语义的匹配程度。
BERTScore首先使用 BERT 模型对生成文本和参考文本进行编码,得到它们在不同层次的向量表示。然后,对于每个层次的向量,计算生成文本和参考文本对应向量之间的余弦相似度,并进行加权求和。具体公式如下:

其中,L是 BERT 模型的层数,hlg和hlr分别是生成文本和参考文本在第l层的向量表示,cosine表示计算余弦相似度的函数。
适用于多种自然语言生成任务,如机器翻译、文本生成、对话系统等。由于其基于预训练语言模型,能够更好地捕捉文本的语义信息,因此在评估语义复杂的文本生成任务时表现较好,能够更准确地反映生成文本与参考文本在语义上的一致性。
生成式大模型的评价是一个综合性的任务,需要结合多种评价方式和指标,从不同角度全面评估模型的性能和质量。不同的评价指标在不同的任务和场景中具有各自的优势和局限性,实际应用中需要根据具体情况选择合适的评价方法和指标组合,以获得对模型准确、全面的评价。


















 4485
4485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











