







《DeepSeek大模型高性能核心技术与多模态融合开发(人工智能技术丛书)》(王晓华)【摘要 书评 试读】- 京东图书
图像问答,作为一种基本的多模态模型形式,融合了视觉与语言处理的技术精髓。它不仅能够理解图像的视觉内容,还能根据用户提出的问题,准确地从图像中提取相关信息,并最终以自然语言的形式给出回答。这种模型的出现,极大地丰富了人机交互的方式,使得机器能够更自然地理解和回应人类的问题。
在图像问答系统中,多模态模型的运用至关重要。该模型能够同时处理图像和语言两种不同模态的数据,通过深度学习算法挖掘它们之间的内在联系。当用户提出一个问题时,系统首先会分析问题的语义,明确用户想要了解的信息点;然后,系统会利用视觉处理技术对图像进行解析,识别出图像中的关键元素;最后,结合问题语义和图像内容,系统生成简洁明了的回答。
随着技术的不断发展,图像问答系统将在更多领域得到应用。例如,在智能教育领域,它可以帮助学生更直观地理解复杂的概念;在智能家居领域,它可以为用户提供更加便捷的控制方式;在医疗领域,它还可以辅助医生进行疾病诊断等。
在本章中,我们将讲解一种基于多模态的图文问答实战,即将图像输入与文本内容进行拉平的操作,再嵌入后进行后续的处理和计算。
10.1.1 一种新的多模态融合方案
为了将图像输入到视觉多模态模型中,我们首先需要执行一个关键步骤:将图像的像素密集地嵌入到模型中。在ViT(即图像分块技术)问世之前,多数VLP[yx1] [晓王2] (Vision-and-Language Pre-training,视觉与语言预训练)方法都高度依赖于复杂的图像特征提取流程。这些流程通常涉及区域监督(例如物体检测)和卷积架构(如ResNet)的运用。因此,VLP研究的重点多集中在通过提升视觉嵌入器的性能来优化整体模型的效果。
研究人员渴望设计出功能更强大的视觉encoder,但这其中潜在着一个实际问题。在学术研究领域,视觉encoder所提取的区域特征可以预先缓存,从而加速研究进程。然而,在实际应用开发中,当面对全新的数据时,研究人员仍需经历区域特征的提取过程。这一过程往往耗时较长,因此,拥有高性能视觉嵌入器所带来的速度瓶颈问题,在实践中常常被忽视。
在这里,我们开发了一种新的多模态视觉模型ViLT。其总体架构如图10-1所示。Transformer Encoder使用预训练的 ViT来初始化,Image Embedding使用ViT中的Patch投影来实现,Word Embedding使用文本的tokenizer进行标记化,并学习一个全新的文本嵌入参数。
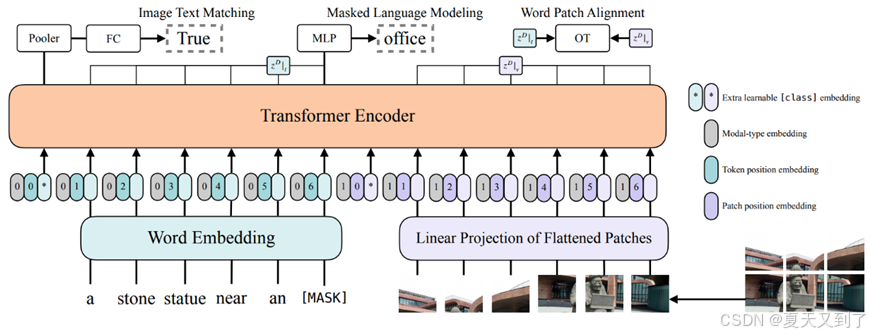 图10-1 一种新的多模态融合方案
图10-1 一种新的多模态融合方案
具体来看,为了实现此种图像和文字特征融合的效果。我们可以使用如下代码:
token_embedding = self.embedding(input_token)
bs, seq_len, dim = token_embedding.shape
image_embedding = self.patch_embedding(image).to(token_embedding.device)
bs,seq_len,dim = token_embedding.shape
img_bs,image_len,dim = image_embedding.shape
position_ids = torch.concat((torch.zeros(size=(bs,image_len),dtype=torch.int), torch.ones(size=(bs,seq_len),dtype=torch.int)),dim=-1).to(token_embedding.device)
position_embedding = self.position_embedding(position_ids)
embedding = torch.cat((image_embedding,token_embedding),dim=1) + position_embedding
for i in range(self.num_layers):
#residual = token_embedding
#这里不能动,需要把信息融合进去
embedding = self.layers[i](embedding, past_length = image_len)
从上面代码可以看到,我们分别提取了token_embedding与image_embedding,之后使用concat将两个embedding连接在一起。而past_length参数确保了模型在处理过程中能够区分并正确处理图像和文本数据。完整的ViLT代码如下所示。
import torch
import torch.nn as nn
import torch.nn.functional as F
import kan,mhsa
import timm
class ViLT(nn.Module):
def __init__(self,vocab_size = 3120,num_layers = 6,d_model = 384,attention_head_num = 6,hidden_dropout = 0.1):
"""Full Mamba model."""
super().__init__()
self.num_layers = num_layers
self.hidden_dropout = hidden_dropout
self.embedding = nn.Embedding(3120, d_model)
self.patch_embedding = timm.layers.PatchEmbed(28,patch_size=7,in_chans = 1,embed_dim=d_model)
self.image_patch_num = int((28/7)**2)
self.layers = torch.nn.ModuleList([mhsa.EncoderBlock(d_model, attention_head_num, hidden_dropout) for _ in range(num_layers)])
self.lm_head = kan.KAN([d_model, vocab_size])
"这里是我加上一个position_ids,目标是标注输入image与token_embedding方式"
self.position_embedding = nn.Embedding(2, d_model)
def forward(self, image,input_token):
token_embedding = self.embedding(input_token)
bs, seq_len, dim = token_embedding.shape
image_embedding = self.patch_embedding(image).to(token_embedding.device)
bs,seq_len,dim = token_embedding.shape
img_bs,image_len,dim = image_embedding.shape
position_ids = torch.concat((torch.zeros(size=(bs,image_len), dtype=torch.int), torch.ones(size=(bs,seq_len),dtype=torch.int)), dim=-1).to(token_embedding.device)
position_embedding = self.position_embedding(position_ids)
embedding = torch.cat((image_embedding,token_embedding),dim=1) + position_embedding
for i in range(self.num_layers):
#residual = token_embedding
#这里不能动,需要把信息融合进去
embedding = self.layers[i](embedding, past_length = image_len)
x = torch.nn.functional.dropout(embedding,p=0.1)
logits = self.lm_head(x)
return logits
@torch.no_grad()
def generate(self,image, prompt=None,n_tokens_to_gen = 20, temperature=1.,top_k = 3,sample = False,eos_token=2,device = "cuda"):
"""
根据给定的提示(prompt)生成一段指定长度的序列。
参数:
- seq_len: 生成序列的总长度。
- prompt: 序列生成的起始提示,可以是一个列表。
- temperature: 控制生成序列的随机性。温度值越高,生成的序列越随机;温度值越低,生成的序列越确定。
- eos_token: 序列结束标记的token ID,默认为2。
- return_seq_without_prompt: 是否在返回的序列中不包含初始的提示部分,默认为True。
返回:
- 生成的序列(包含或不包含初始提示部分,取决于return_seq_without_prompt参数的设置)。
"""
# 将输入的prompt转换为torch张量,并确保它在正确的设备上(如GPU或CPU)。]
self.eval()
#prompt = torch.tensor(prompt)
prompt = prompt.clone().detach().requires_grad_(False).to(device)
input_ids = prompt
for token_n in range(n_tokens_to_gen):
with torch.no_grad():
indices_to_input = input_ids
next_token_logits = self.forward(image,indices_to_input)[:, -1]
probs = F.softmax(next_token_logits, dim=-1) * temperature
(batch, vocab_size) = probs.shape
if top_k is not None:
(values, indices) = torch.topk(probs, k=top_k)
probs[probs < values[:, -1, None]] = 0
probs = probs / probs.sum(axis=1, keepdims=True)
if sample:
next_indices = torch.multinomial(probs, num_samples=1)
else:
next_indices = torch.argmax(probs, dim=-1)[:, None]
input_ids = torch.cat([input_ids, next_indices], dim=1)
return input_ids
在上面代码中,我们除了在模型中进行融合外,还整合了生成部分,结合原始的生成模型的生成方式,可以对文本内容进行预测。
10.1.2 数据集的设计与使用
本小节将完成图像问答模型的数据准备,此时我们依旧使用MNIST数据集来获取数据,不同的是我们在这例子中用来提问的文本内容,其相应的回答是MNIST手写所代表的数字,示例如下。
sample_texts = [
"这个数字或许是:",
"此数字可能等于:",
"该数字可能表示:",
"这个数字可能意味着:",
"或许这个数字是:",
……
]
此时对MNIST数据集处理的代码如下所示。
class MNIST(Dataset):
def __init__(self, is_train=True):
super().__init__()
self.ds = torchvision.datasets.MNIST('../dataset/mnist/', train=is_train, download=True)
self.img_convert = Compose([
PILToTensor(),
])
def __len__(self):
return len(self.ds)
def __getitem__(self, index):
img, label = self.ds[index]
#text = f"现在的数字是:{label}#"
text = random.sample(sample_texts,1)[0][-10:]
text = text + str(label) + "#"
full_tok = tokenizer_emo.encode(text)[-12:]
full_tok = full_tok + [1] * (12 - len(full_tok))
inp_tok = full_tok[:-1]
tgt_tok = full_tok[1:]
inp_tok = torch.tensor(inp_tok)
tgt_tok = torch.tensor(tgt_tok)
"""
torch.Size([1, 28, 28])
"""
return self.img_convert(img) / 255.0, inp_tok,tgt_tok
10.1.3 多模态融合数据集的训练
对于训练任务,我们需要根据需求设置特殊的label。观察此时的数据,我们的模型并不需要预测image部分,只需要预测文本生成部分。因此,我们在建立label时,可以额外添加一个不需要预测的image label部分,放置在文本内容之前,代码如下所示。
token_tgt_pad = torch.ones(size=(token_inp.shape[0],16),dtype=torch.int) * -100
token_tgt = torch.concat((token_tgt_pad,token_tgt),dim=-1)
token_tgt = token_tgt.to(device)
同样地,对于损失函数的计算,我们也需要做如下设计:
criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
这样做的目的是对于补充的部分,忽略了额外添补的image特征部分,从而只需要计算对应的文本内容。完整的训练代码如下所示。
from model import ViLT
import math
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
device = "cuda"
model = ViLT()
model.to(device)
save_path = "./saver/mamba_generator.pth"
#model.load_state_dict(torch.load(save_path),strict=False)
BATCH_SIZE = 640
seq_len = 49
import get_data_emotion
#import get_data_emotion_2 as get_data_emotion
train_dataset = get_data_emotion.MNIST()
train_loader = (DataLoader(train_dataset, batch_size=BATCH_SIZE,shuffle=True))
optimizer = torch.optim.AdamW(model.parameters(), lr = 2e-4)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer,T_max = 1200,eta_min=2e-5,last_epoch=-1)
criterion = torch.nn.CrossEntropyLoss(ignore_index=-100)
for epoch in range(12):
pbar = tqdm(train_loader,total=len(train_loader))
for image,token_inp,token_tgt in pbar:
image = image.to(device)
token_inp = token_inp.to(device)
token_tgt_pad = torch.ones(size=(token_inp.shape[0],16),dtype=torch.int) * -100
token_tgt = torch.concat((token_tgt_pad,token_tgt),dim=-1)
token_tgt = token_tgt.to(device)
logits = model(image,token_inp)
loss = criterion(logits.view(-1, logits.size(-1)), token_tgt.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step() # 执行优化器
pbar.set_description(f"epoch:{epoch +1}, train_loss:{loss.item():.5f}, lr:{lr_scheduler.get_last_lr()[0]*1000:.5f}")
if (epoch + 1) % 7 == 0:
torch.save(model.state_dict(), save_path)
torch.save(model.state_dict(), save_path)
读者可以自行运行代码并查看结果。


















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









