







 超级会员免费看
超级会员免费看
💙作者主页: GoAI |💚 公众号: GoAI的学习小屋 | 💛交流群: 704932595 |💜个人简介 : 掘金签约作者、百度飞桨PPDE、领航团团长、开源特训营导师、优快云、阿里云社区人工智能领域博客专家、新星计划计算机视觉方向导师等,专注大数据与AI 知识分享。
💚导读:GoAI的学习社区知识星球 是一个 致力于提供《机器学习 | 深度学习 | CV | NLP | 大模型 | 多模态 | AIGC 》各个最新AI方向综述、论文等成体系的学习资料,并对以上方向推出全面而有深度的专栏内容,包括不限于 前沿论文解读、资料共享、行业最新动态以、实践教程、求职相关(简历撰写技巧、面经资料与心得)多方面综合学习平台。星球访问 :https://t.zsxq.com/QBfaV,有惊喜优惠!
💻文章目录
✨专栏介绍: 本作者推出全新系列《深入浅出多模态》专栏,具体章节如导图所示(导图后续更新),将分别从各个多模态模型的概念、经典模型、创新点、论文综述、发展方向、数据集等各种角度展开详细介绍,欢迎大家关注。
《深入浅出多模态》之多模态技术总结(上)
《深入浅出多模态》之多模态技术知识总结(中)(本篇)
《深入浅出多模态》(一):多模态模型论文最全总结
《深入浅出多模态》(二):多模态任务应用与背景
《深入浅出多模态》(三):多模态任务前言知识
《深入浅出多模态》之多模态经典模型:CLIP
《深入浅出多模态》之多模态经典模型:ALBEF
《深入浅出多模态》之多模态经典模型:BLIP
《深入浅出多模态》之多模态经典模型:BLIP2
《深入浅出多模态》之多模态经典模型:MiniGPTv4
《深入浅出多模态》之多模态经典模型:MiniGPT-v2、MiniGPT5
《深入浅出多模态》之多模态经典模型:InstructBLIP
🔥本篇导读:本篇内容承接前两篇《深入浅出多模态》之多模态技术总结(上)、《深入浅出多模态》中:多模态模型原理总结,首先将围绕不同多模态模型的对齐方法对经典多模态模型进行对比与总结,并挑选主流的多模态模型CLIP、BLIP、BLIP2等展开详细介绍,最后引入厂内多模态框架PaddleMIX进行多任务实战,帮助大家快速了解多模态技术。
实战平台:https://aistudio.baidu.com/index
本次实战平台环境推荐采用飞桨星河社区的开源平台,其提供强大易用的环境,包括上传自己的数据集及训练可视化,还可以加载多任务套件(PaddleNLP、PaddleOCR、PaddleDetection、PaddleClas任等),更多亮点在于轻量代码实现,共同助力开发者轻松进行机器和深度学习。相比个人环境飞桨平台已预配环境,用户无需自行安装GPU环境可直接编程、运行实验,可快速搭建模型,降低门槛。飞桨平台提供多行业的模型库,具体如下:

(1)PaddleMIX 介绍
PaddleMIX是基于飞桨的跨模态大模型开发套件,聚合图像、文本、视频等多种模态,覆盖视觉语言预训练,文生图,文生视频等丰富的跨模态任务。提供开箱即用的开发体验,同时满足开发者灵活定制需求,探索通用人工智能。PaddleMIX官网: https://github.com/PaddlePaddle/PaddleMIX
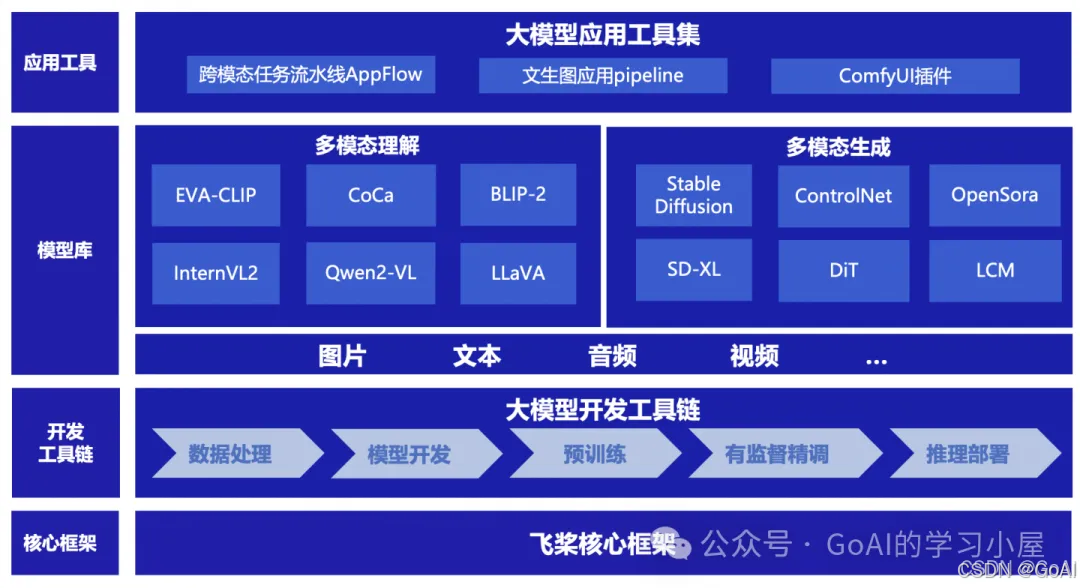
主要特性:
丰富的多模态功能:覆盖图文预训练,文生图,跨模态视觉任务,实现图像编辑、图像描述、数据标注等多样功能
简洁的开发体验:模型统一开发接口,高效实现自定义模型开发和功能实现
高效的训推流程:全量模型打通训练推理一站式开发流程,BLIP-2,Stable Diffusion等重点模型训推性能业界领先
超大规模训练支持:可训练千亿规模图文预训练模型,百亿规模文生图底座模型 支持的多模态任务(理解和生成):

1.使用教程
注:最新安装教程可参照访问官网Github:PaddleMIX
克隆PaddleMIX项目:git clone https://github.com/PaddlePaddle/PaddleMIX
安装PaddleMIX和ppdiffusers环境
cd PaddleMIX
pip install -e .
cd ppdiffusers
pip install -e .
安装appflow 依赖环境
pip install -r paddlemix/appflow/requirements.txt
2.一键预测
PaddleMIX提供一键预测功能,无需训练,覆盖图文预训练,文生图,跨模态视觉任务,实现图像编辑、图像描述、数据标注等多十几种种跨模态应用(可自行更开预训练任务模型)。下面本人将参考官方教程以PaddleMIX库中的BLIP2模型展开介绍。
(2)基于PaddleMIX的多模态模型VQA和Caption任务–以BLIP2为例:
1.环境准备
cd PaddleMIX
pip install -r requirements.txt
2.数据准备
coco数据 数据部分,默认使用coco_karpathy数据,使用该数据不需另外配置,会自动下载。目前已支持 “coco_caption”,"vg_caption"等数据集训练。数据标注示例:{‘caption’: 'A woman wearing a net on her head cutting a cake. ', ‘image’: ‘val2014/COCO_val2014_000000522418.jpg’, ‘image_id’: ‘coco_522418’}
自定义数据 如果需要自定义数据,推荐沿用上述数据格式处理自己的数据。更多可参考数据集中的annotations/coco_karpathy_train.json文件。在准备好自定义数据集以后, 我们可以使用 load_dataset() 来加载数据.
3.模型介绍
PaddleMix支持BLIP-2系列模型,目前包括BLIP-2-OPT、BLIP-2-FlanT5
blip2-stage1 :对应上述blip2的第一阶段预训练模型,可用于开启第二阶段预训练
blip2-stage2 :使用论文中数据训练好的第一阶段模型,可用于开启第二阶段预训练
blip2-pretrained-opt :对应论文精度Blip2第二阶段训练完成的模型,语言模型使用opt,可用于模型微调任务或进行zeroshot vqa推理
blip2-caption-opt :对应论文精度Blip2第二阶段训练完成并在caption数据集进行微调的模型,语言模型使用opt,可用于image caption推理
4.BLIP2训练配置
BLIP2训练无需更改参数即可开始训练,参考代码如下:
MODEL_NAME="paddlemix/blip2-stage2"fleetrun --master ‘127.0.0.1’ --nnodes 1 --nproc_per_node 8 --ips ‘127.0.0.1:8080’ run_pretrain_stage2.py
–per_device_train_batch_size 128
–model_name_or_path ${MODEL_NAME}
–warmup_steps 2000
–eta_min 1e-5
–learning_rate 0.0001
–weight_decay 0.05
–num_train_epochs 10
–tensor_parallel_degree 1 \ #设置张量模型的并行数。–sharding_parallel_degree 1 \ #设置分片数量,启用分片并行。–output_dir “./output” \ --logging_steps 50
–do_train
–save_strategy epoch
注:其中#MODEL_NAME 路径配置为 paddlemix/ + 已支持的model name(如blip2-pretrained-opt2.7b,paddlemix/blip2-stage1等)
可配置参数说明(具体请参考paddlemix/examples/blip2/run_pretrain_stage2.py)
第一阶段训练
单卡训练
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_pretrain_stage1.py
多卡训练
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_pretrain_stage1.py
第二阶段训练
单卡训练
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_pretrain_stage2.py
多卡训练
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_pretrain_stage2.py
5.评估
问答任务评估
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_eval_vqav2_zeroshot.py
生成任务评估
fleetrun --gpus=0,1,2,3 paddlemix/examples/blip2/run_eval_caption.py
6.预测
CUDA_VISIBLE_DEVICES=0 python paddlemix/examples/blip2/run_predict.py
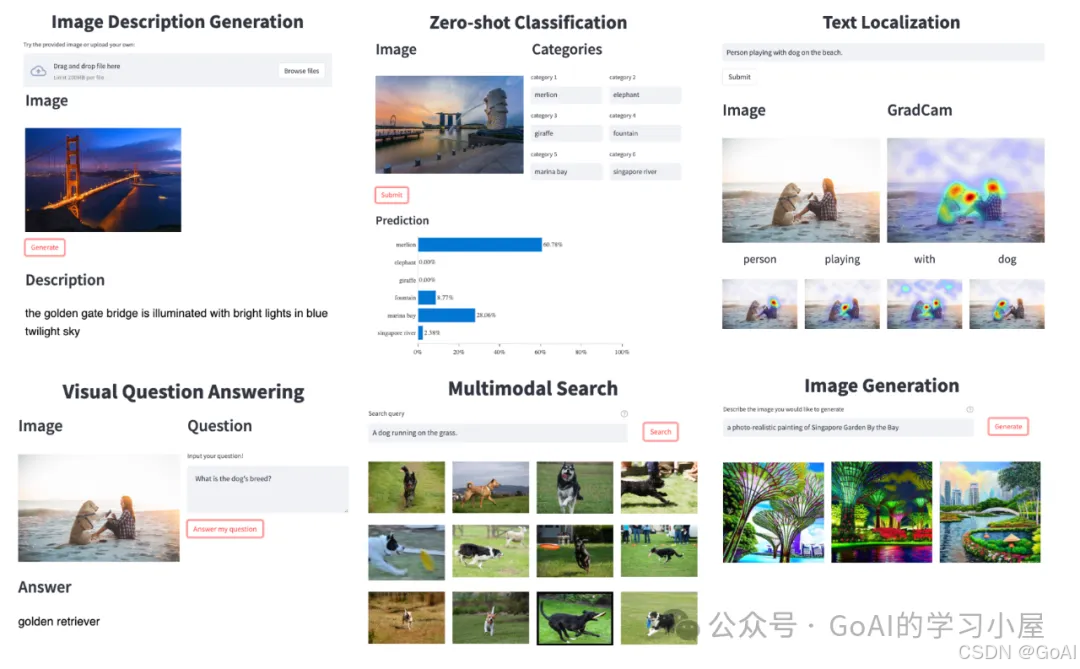
多模态学习项目推荐:
多模态理解相关项目:
CLIP以文搜图
多模态视频分类 - 飞桨AI Studio星河社区
多模态技术在金融场景创新实践:表单识别 - 飞桨AI Studio星河社区
…
多模态生成相关项目:
【奥运海报】基于Stable Diffusion XL自制奥运海报生成器 - 飞桨AI Studio星河社区
基于【PaddleMIX】的音乐生成器 让你的灵感瞬间变成美妙旋律
基于【PaddleMIX】给新年第一张照片配音
…
更多完整的项目可访问飞桨官方查阅!PaddleMIX项目分类汇总
最后,对多模态技术感兴趣的小伙伴,可以关注下厂内飞桨推出的多模态课程:飞桨AI Studio星河社区-人工智能学习与实训社区
全文总结:
本文主要对多模态模型的概念、下游任务类型、数据集、发展时间线的基础理论进行介绍,着重讲解经典多模态大模型(CLIP、BLIP、BLIP2等)原理及结构,最后对飞桨多模态框架PaddleMIX进行介绍,对多模态通用任务基础项目实战,最后推荐给大家一些自己在学习多模态中遇到的相关资料,欢迎大家在评论区交流学习,作者能力有限,若文中描述有误也欢迎大家指导!
本书详尽地覆盖了多模态大模型的算法原理和应用实战,提供了丰富的微调技术细节和实际案例,适合对多模态大模型有兴趣的技术人员深入学习和应用,非常适合想学习多模态技术的爱好者学习。书籍链接:


















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











