



快链:
- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用
使用PyTorch解决异或问题
学习目标
本课程简要介绍了 PyTorch 基础知识,并帮助你搭建起编写自己的神经网络用来解决异或问题。
相关知识点
- PyTorch 的基础
- 连续 XOR 问题
学习内容
1 PyTorch 的基础
PyTorch 是一个开源的机器学习框架,它允许你编写自己的神经网络并高效地进行优化。然而,PyTorch 并不是唯一此类框架。PyTorch 的替代品包括 TensorFlow、JAX 和 Caffe。许多当前的论文都用 PyTorch 发布代码,因此熟悉 PyTorch 是很有必要的。与此同时,TensorFlow(由谷歌开发)通常被认为是一个生产级的深度学习库。不过,如果你深入掌握了其中一个机器学习框架,学习另一个框架就会很容易,因为许多框架都使用了相同的概念和思想。例如,TensorFlow 的 2.0 版本在很大程度上受到了 PyTorch 最受欢迎功能的启发,这使得这两个框架更加相似。如果你已经熟悉 PyTorch 并且创建过自己的神经网络项目,那么你可以很轻松的掌握本课程所介绍的内容。
- 实验所需依赖安装
%pip install seaborn
%pip install ipywidgets
%pip install torch==2.2.0
- 导入依赖
## 标准库
import os
import math
import numpy as np
import time
## 用于绘图的导入
import matplotlib.pyplot as plt
%matplotlib inline
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf') # 用于导出
from matplotlib.colors import to_rgba
import seaborn as sns
sns.set()
## 进度条
from tqdm.notebook import tqdm
本课程将从回顾 PyTorch 的最基本概念开始。作为先决条件,建议熟悉 numpy 包,因为大多数机器学习框架都基于非常相似的概念。
那么,先从导入 PyTorch 开始。该包名为 torch,基于其最初框架 Torch。作为第一步,可以检查其版本:
import torch
print("Using torch", torch.__version__)
由于安装依赖时更新了torch版本到2.2.0。因此,你应该看到输出内容为Using torch 2.2.0。
在每一个机器学习框架中,PyTorch 都提供了诸如生成随机数这样的随机函数。然而,一个非常好的实践是设置你的代码,使其能够使用完全相同的随机数来复现结果。这就是为什么需要在下面设置了种子。
torch.manual_seed(42) # 设置随机数种子
1.1 张量
张量是 PyTorch 中与 Numpy 数组相对应的概念,此外还支持 NPU 加速。名称“张量”是你已经熟悉的概念的泛化。例如,向量是一维张量,矩阵是二维张量。在处理神经网络时,会使用各种形状和维度数量的张量。
你熟悉的大多数 Numpy 函数也可以用于张量。实际上,由于 Numpy 数组与张量非常相似,可以将大多数张量转换为 Numpy 数组(反之亦然),但这种情况并不常见。
1.1.1 初始化
创建张量的不同方法,有很多可能的选项,最简单的方法是调用torch.Tensor,并将所需的形状作为输入参数传递:
x = torch.Tensor(2, 3, 4)
print(x)
torch.Tensor 函数会为所需的张量分配内存,但会重复使用内存中已经存在的值。如果要在初始化时直接为张量分配值,有许多替代方法,包括:
torch.zeros: 创建一个填充了零的张量。torch.ones: 创建一个填充了一的张量。torch.rand: 创建一个张量,其值在 0 和 1 之间均匀采样。torch.randn: 创建一个张量,其值从均值为 0、方差为 1 的正态分布中采样。torch.arange: 创建一个包含值 N , N + 1 , N + 2 , . . . , M N,N+1,N+2,...,M N,N+1,N+2,...,M 的张量。torch.Tensor(输入列表): 根据你提供的列表元素创建一个张量。
# 从(嵌套的)列表创建张量
x = torch.Tensor([[1, 2], [3, 4]])
print(x)
# 创建一个形状为 [2, 3, 4] 的张量,其值在 0 到 1 之间随机
x = torch.rand(2, 3, 4)
print(x)
你可以像在 numpy 中一样通过 x.shape 获取张量的形状,也可以使用 .size 方法:
shape = x.shape
print("Shape:", x.shape)
size = x.size()
print("Size:", size)
dim1, dim2, dim3 = x.size()
print("Size:", dim1, dim2, dim3)
1.1.2 张量与 Numpy 数组之间的转换
张量可以转换为 Numpy 数组,Numpy 数组也可以转换为张量。要将 Numpy 数组转换为张量,可以使用 torch.from_numpy 函数:
np_arr = np.array([[1, 2], [3, 4]])
tensor = torch.from_numpy(np_arr)
print("Numpy array:", np_arr)
print("PyTorch tensor:", tensor)
要将 PyTorch 张量转换回 NumPy 数组,可以使用张量的 .numpy() 方法:
tensor = torch.arange(4)
np_arr = tensor.numpy()
print("PyTorch tensor:", tensor)
print("Numpy array:", np_arr)
将张量转换为 Numpy 数组需要张量位于 CPU 上,而不是 NPU 上。如果你有一个位于 NPU 上的张量,你需要先对该张量调用 .cpu() 方法。因此,你会得到类似这样的代码行:np_arr = tensor.cpu().numpy()。
1.1.3 张量的操作
在 PyTorch 中,大多数在 Numpy 中存在的操作张量也都有。
最简单的操作是将两个张量相加:
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
y = x1 + x2
print("X1", x1)
print("X2", x2)
print("Y", y)
调用 x1 + x2 会创建一个新张量,其中包含两个输入的和。然而,也可以使用原地操作(in-place operations),这些操作直接作用于张量的内存。因此,会改变 x2 的值,而没有机会重新访问操作之前的 x2 的值。以下是一个示例:
x1 = torch.rand(2, 3)
x2 = torch.rand(2, 3)
print("X1 (before)", x1)
print("X2 (before)", x2)
x2.add_(x1)
print("X1 (after)", x1)
print("X2 (after)", x2)
原地操作通常用下划线后缀来标记(例如,“add_”而不是“add”)。
另一个常见的操作是改变张量的形状。一个大小为 (2,3) 的张量可以被重新组织成任何其他具有相同元素数量的形状(例如,大小为 (6) 的张量,或 (3,2) 的张量,……)。在 PyTorch 中,这种操作被称为 view:
x = torch.arange(6)
print("X", x)
x = x.view(2, 3)
print("X", x)
x = x.permute(1, 0) # 交换维度 0 和 维度1
print("X", x)
其他常用的操作包括矩阵乘法,这对于神经网络至关重要。通常,有一个输入向量 x \mathbf{x} x,它通过一个学习到的权重矩阵 W \mathbf{W} W 进行变换。执行矩阵乘法有多种方法和函数,其中一些我们列在下面:
torch.matmul: 对两个张量执行矩阵乘积,具体行为取决于维度。如果两个输入都是矩阵(二维张量),它执行标准的矩阵乘法。对于更高维度的输入,该函数支持广播。也可以写作 a @ b,类似于 numpy。torch.mm: 对两个矩阵执行矩阵乘积,但不支持广播。torch.bmm: 执行矩阵乘法,支持批量维度。如果第一个张量 T T T 的形状为 ( b × n × m b\times n\times m b×n×m), 第二个张量 R R R 的形状为( b × m × p b\times m\times p b×m×p), 那么输出 O O O 的形状为 ( b × n × p b\times n\times p b×n×p), 通过执行 b b b 次子矩阵 T T T 和 R R R的矩阵乘法计算得到: O i = T i @ R i O_i = T_i @ R_i Oi=Ti@Ritorch.einsum:使用爱因斯坦求和约定执行矩阵乘法以及更多操作(即乘积的和)。
通常,我们使用 torch.matmul 或 torch.bmm。我们可以在下面尝试使用 torch.matmul 进行矩阵乘法。
x = torch.arange(6)
x = x.view(2, 3)
print("X", x)
W = torch.arange(9).view(3, 3) # 可以在一行中堆叠多个操作
print("W", W)
h = torch.matmul(x, W) # 通过手动计算来验证结果!
print("h", h)
1.1.4 索引
本课程经常需要从张量中选择一部分。索引的使用方法与 numpy 完全相同,尝试一下:
x = torch.arange(12).view(3, 4)
print("X", x)
print(x[:, 1]) # 第二列
print(x[0]) # 第一行
print(x[:2, -1]) # 前两行,最后一列
print(x[1:3, :]) # x[1],x[2]两行,1:3,包含1不包含3
X tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
tensor([1, 5, 9])
tensor([0, 1, 2, 3])
tensor([3, 7])
tensor([[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
1.2 动态计算图与反向传播
使用 PyTorch 进行深度学习项目的主要原因之一是,可以自动获得我们定义的函数的梯度/导数。本课程将主要使用 PyTorch 来实现神经网络,而神经网络本质上是复杂的函数。如果本课程使用的函数中包含想要学习的权重矩阵,那么这些就被称为参数或简单地说是权重。
如果神经网络输出一个标量值,就会谈到求导数,但你会发现很多时候会有多个输出变量(“值”);在这种情况下,就会谈论的是梯度。这是一个更通用的术语。
给定一个输入 x \mathbf{x} x,通过操作这个输入来定义我们的函数,通常通过与权重矩阵进行矩阵乘法和与所谓的偏置向量进行加法运算。当操作输入时,自动创建了一个计算图。这个图展示了如何从输入到达输出。
PyTorch 是一个定义即运行的框架;这意味着只需进行操作,PyTorch 会为跟踪这个图。因此,会沿着路径创建了一个动态计算图。
所以,总结一下:本课程唯一需要做的是计算输出,然后可以要求 PyTorch 自动获得梯度。
注意:为什么需要梯度? 假设本课程定义了一个函数,一个神经网络,它应该为输入向量 x \mathbf{x} x 计算一个特定的输出 y y y。然后定义了一个误差度量,它告诉本课程的网络有多错误;它在从输入 x \mathbf{x} x 预测输出 y y y 时有多糟糕。基于这个误差度量,可以使用梯度来更新那些负责输出的权重 W \mathbf{W} W,以便下次向网络呈现输入 x \mathbf{x} x 时,输出将更接近想要的结果。
首先要做的就是指定哪些张量需要梯度。默认情况下,当创建一个张量时,它是不需要梯度的。
x = torch.ones((3,))
print(x.requires_grad)
可以使用函数 requires_grad_()(下划线表示这是一个原地操作)来改变现有张量的这一属性。或者,在创建张量时,你可以将参数 requires_grad=True 传递给上面看到的大多数初始化函数。
x.requires_grad_(True)
print(x.requires_grad)
为了熟悉计算图的概念,将为以下函数创建一个计算图:
y = 1 ℓ ( x ) ∑ i [ ( x i + 2 ) 2 + 3 ] , y = \frac{1}{\ell(x)}\sum_i \left[(x_i + 2)^2 + 3\right], y=ℓ(x)1i∑[(xi+2)2+3],
其中用 ℓ ( x ) \ell(x) ℓ(x) 表示 x x x 中的元素数量。换句话说,是对求和内的操作取平均值。你可以想象 x x x 是实验的参数,实验中想要优化(最大化或最小化)输出 y y y。为此,实验中需要获得梯度 ∂ y / ∂ x \partial y / \partial \mathbf{x} ∂y/∂x。在实验的例子中,将使用 x = [ 0 , 1 , 2 ] \mathbf{x}=[0,1,2] x=[0,1,2] 作为输入。
x = torch.arange(3, dtype=torch.float32, requires_grad=True) # 只有浮点张量可以有梯度
print("X", x)
现在逐步构建计算图。虽然你可以在一行中组合多个操作,但是将在这里将它们分开,以便更好地理解每个操作是如何被添加到计算图中的。
a = x + 2
b = a ** 2
c = b + 3
y = c.mean()
print("Y", y)
使用上述语句,创建了一个类似于下图的计算图:
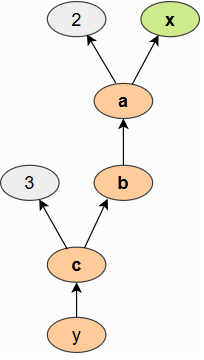
我们根据输入
x
x
x 和常数
2
2
2 计算
a
a
a ,
b
b
b 是
a
a
a 的平方,依此类推。这种可视化是对我们应用的操作的输入和输出之间依赖关系的抽象。
计算图的每个节点都自动定义了一个函数,用于计算其输入的梯度,即 grad_fn。当你打印输出张量
y
y
y 时,你可以看到这一点。这就是为什么计算图通常以相反的方向进行可视化(箭头从结果指向输入)。我们可以通过在最后一个输出上调用 backward() 函数来对计算图进行反向传播,这实际上会为每个具有 requires_grad=True 属性的张量计算梯度:
y.backward()
x.grad 现在将包含梯度
∂
y
/
∂
x
\partial y/ \partial \mathcal{x}
∂y/∂x,这个梯度表明在当前输入
x
=
[
0
,
1
,
2
]
\mathbf{x}=[0,1,2]
x=[0,1,2]的情况下,
x
\mathbf{x}
x 的变化将如何影响输出
y
y
y:
print(x.grad)
也可以手动验证这些梯度。将使用链式法则计算梯度,就像 PyTorch 做的那样:
∂ y ∂ x i = ∂ y ∂ c i ∂ c i ∂ b i ∂ b i ∂ a i ∂ a i ∂ x i \frac{\partial y}{\partial x_i} = \frac{\partial y}{\partial c_i}\frac{\partial c_i}{\partial b_i}\frac{\partial b_i}{\partial a_i}\frac{\partial a_i}{\partial x_i} ∂xi∂y=∂ci∂y∂bi∂ci∂ai∂bi∂xi∂ai
请注意,实验中已经将这个方程简化为索引表示法,并且利用了除了求平均值之外的所有操作都不会组合张量中的元素这一事实。偏导数如下:
∂ a i ∂ x i = 1 , ∂ b i ∂ a i = 2 ⋅ a i ∂ c i ∂ b i = 1 ∂ y ∂ c i = 1 3 \frac{\partial a_i}{\partial x_i} = 1,\hspace{1cm} \frac{\partial b_i}{\partial a_i} = 2\cdot a_i\hspace{1cm} \frac{\partial c_i}{\partial b_i} = 1\hspace{1cm} \frac{\partial y}{\partial c_i} = \frac{1}{3} ∂xi∂ai=1,∂ai∂bi=2⋅ai∂bi∂ci=1∂ci∂y=31
因此,当输入为 x = [ 0 , 1 , 2 ] \mathbf{x}=[0,1,2] x=[0,1,2] 时,实验的梯度是 ∂ y / ∂ x = [ 4 / 3 , 2 , 8 / 3 ] \partial y/\partial \mathbf{x}=[4/3,2,8/3] ∂y/∂x=[4/3,2,8/3]。前面的代码单元应该打印了相同的结果。
2 连续 XOR 问题
如果想在 PyTorch 中构建一个神经网络,可以使用 Tensors(设置 requires_grad=True)来指定所有的参数(权重矩阵、偏置向量),让 PyTorch 计算梯度,然后调整这些参数。但如果参数很多,这种方式会变得很繁琐。在 PyTorch 中,有一个名为 torch.nn 的包,它使得构建神经网络变得更加方便。
实验将通过一个简单的示例分类器(基于一个简单但众所周知的例子:XOR)来介绍 PyTorch 中训练神经网络所需的库和所有附加部分。给定两个二进制输入
x
1
x_1
x1 和
x
2
x_2
x2,如果
x
1
x_1
x1 或
x
2
x_2
x2 中有一个为
1
1
1,而另一个为
0
0
0,则预测的标签为
1
1
1;在所有其他情况下,标签为
0
0
0。这个例子之所以出名,是因为单个神经元(即线性分类器)无法学习这个简单的函数。
因此,本课程中将学习如何构建一个小型神经网络来学习这个函数。
为了让问题更有趣,实验中将 XOR 移到连续空间中,并在二进制输入上引入一些高斯噪声。期望的 XOR 数据集的分离效果可能如下所示:
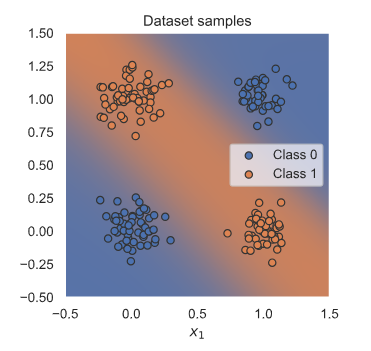
2.1 模型
torch.nn 包定义了一系列有用的类,例如线性网络层、激活函数、损失函数等。
在构建神经网络时,如果您需要某种特定的网络层,请先查看该包的文档,因为该包很可能已经包含了您需要的代码,无需您自己编写。在下面导入了它:
import torch.nn as nn
除了 torch.nn 之外,还有 torch.nn.functional。它包含了网络层中使用的函数。这与 torch.nn 形成对比,torch.nn 将这些函数定义为 nn.Modules(稍后会详细介绍),并且 torch.nn 实际上使用了 torch.nn.functional 中的许多功能。因此,torch.nn.functional 在许多情况下都非常有用,在这里也导入了它。
import torch.nn.functional as F
2.1.1 nn.Module
在 PyTorch 中,神经网络是由模块(modules)构建而成的。模块可以包含其他模块,而神经网络本身也被视为一个模块。模块的基本模板如下:
class MyModule(nn.Module):
def __init__(self):
super().__init__()
# 为我的模块进行一些初始化
def forward(self, x):
# 用于执行模块计算的函数。
pass
forward 函数是模块进行计算的地方,当你调用模块时(例如:nn = MyModule(); nn(x)),它会被执行。在 init 函数中,通常使用 nn.Parameter 创建模块的参数,或者定义在 forward 函数中使用的其他模块。反向传播计算是自动完成的,但也可以根据需要进行覆盖。
2.1.2 简单分类器
现在可以利用 torch.nn 包中预定义的模块,定义自己的小型神经网络。将使用一个最小的网络,包含输入层、一个带有 tanh 激活函数的隐藏层以及输出层。换句话说,我们的网络应该类似于以下结构:
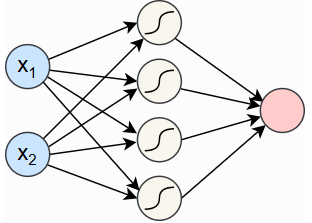
输入神经元以蓝色显示,表示数据点的坐标
x
1
x_1
x1 和
x
2
x_2
x2。带有 tanh 激活函数的隐藏神经元以白色显示,输出神经元以红色显示。
在 PyTorch 中,可以这样定义这个网络:
class SimpleClassifier(nn.Module):
def __init__(self, num_inputs, num_hidden, num_outputs):
super().__init__()
# 初始化我们需要构建网络的模块
self.linear1 = nn.Linear(num_inputs, num_hidden)
self.act_fn = nn.Tanh()
self.linear2 = nn.Linear(num_hidden, num_outputs)
def forward(self, x):
# 执行模型的计算以确定预测结果
x = self.linear1(x)
x = self.act_fn(x)
x = self.linear2(x)
return x
在本课程中,将使用一个非常小的神经网络,包含两个输入神经元和四个隐藏神经元。由于实验进行的是二分类任务,因此将使用一个输出神经元。请注意,实验中尚未在输出上应用 Sigmoid数 。这是因为其他函数(尤其是损失函数)在原始输出上进行计算时会更高效且更精确,而不是在 Sigmoid 输出上进行计算。我们稍后将详细讨论原因。
model = SimpleClassifier(num_inputs=2, num_hidden=4, num_outputs=1)
# 打印模型会显示其所有子模块
print(model)
打印模型会列出它包含的所有子模块。可以通过使用模块的 parameters() 函数来获取其参数,或者使用 named_parameters() 来为每个参数对象分配一个名称。对于实验中的小型神经网络,有以下参数:
for name, param in model.named_parameters():
print(f"Parameter {name}, shape {param.shape}")
每个线性层都有一个形状为 [output, input] 的权重矩阵,以及一个形状为 [output] 的偏置向量。tanh 激活函数没有参数。请注意,参数仅注册为直接作为对象属性的 nn.Module 对象,即 self.a = ...。如果您定义了一个模块列表,这些模块的参数不会被注册到外部模块中,这可能会在您尝试优化模块时导致一些问题。有一些替代方案,例如 nn.ModuleList、nn.ModuleDict 和 nn.Sequential,它们允许您使用不同类型的模块数据结构。
2.2 数据处理
PyTorch 还提供了一些功能,用于高效地加载训练数据和测试数据,这些功能总结在 torch.utils.data 包中。
import torch.utils.data as data
数据包定义了两个类,它们是 PyTorch 中处理数据的标准接口:data.Dataset 和 data.DataLoader。Dataset 类提供了一个统一的接口来访问训练数据和测试数据,而 DataLoader 确保在训练过程中高效地从数据集中加载和堆叠数据点到批次中。
2.2.1 数据集类
数据集类以自然的方式总结了数据集的基本功能。要在 PyTorch 中定义一个数据集,我们只需指定两个函数:__getitem__ 和 __len__。__getitem__ 函数必须返回数据集中的第
i
i
i 个数据点,而 __len__ 函数返回数据集的大小。对于 XOR 数据集,我们可以这样定义数据集类:
class XORDataset(data.Dataset):
def __init__(self, size, std=0.1):
"""
输入:
size - 想要生成的数据点数量
std - 噪声的标准差(参见 generate_continuous_xor 函数)
"""
super().__init__()
self.size = size
self.std = std
self.generate_continuous_xor()
def generate_continuous_xor(self):
# XOR 数据集中的每个数据点都有两个变量,x 和 y,它们可以是 0 或 1。
# 标签是它们的 XOR 组合,即仅当 x 或仅当 y 为 1 而另一个为 0 时为 1。
# 如果 x = y ,标签为 0 。
data = torch.randint(low=0, high=2, size=(self.size, 2), dtype=torch.float32)
label = (data.sum(dim=1) == 1).to(torch.long)
# 为了使其稍微更具挑战性,我们在数据点中加入了一些高斯噪声。
data += self.std * torch.randn(data.shape)
self.data = data
self.label = label
def __len__(self):
# 我们拥有的数据点数量。也可以使用 self.data.shape[0] 或 self.label.shape[0]
return self.size
def __getitem__(self, idx):
# 返回数据集中第 idx 个数据点
# 如果需要返回多个内容(数据点和标签),可以将它们作为元组返回
data_point = self.data[idx]
data_label = self.label[idx]
return data_point, data_label
创建这样一个数据集并检查它:
dataset = XORDataset(size=200)
print("Size of dataset:", len(dataset))
print("Data point 0:", dataset[0])
为了更好地理解数据集,在下面对样本进行了可视化:
def visualize_samples(data, label):
if isinstance(data, torch.Tensor):
data = data.cpu().numpy()
if isinstance(label, torch.Tensor):
label = label.cpu().numpy()
data_0 = data[label == 0]
data_1 = data[label == 1]
plt.figure(figsize=(4,4))
plt.scatter(data_0[:,0], data_0[:,1], edgecolor="#333", label="Class 0")
plt.scatter(data_1[:,0], data_1[:,1], edgecolor="#333", label="Class 1")
plt.title("Dataset samples")
plt.ylabel(r"$x_2$")
plt.xlabel(r"$x_1$")
plt.legend()
visualize_samples(dataset.data, dataset.label)
plt.show()
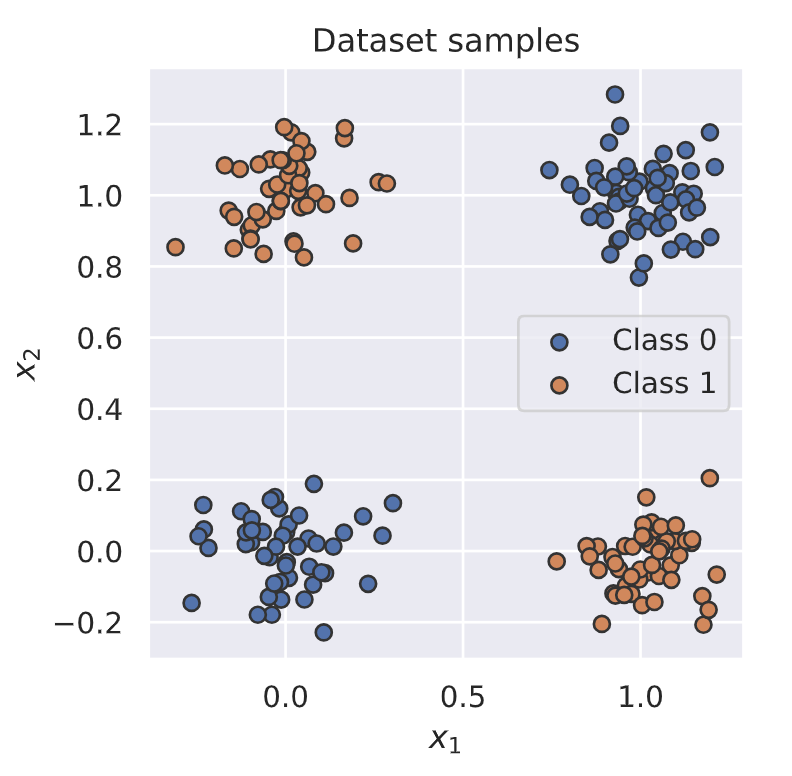
2.2.2 数据加载器类
torch.utils.data.DataLoader 类是一个 Python 可迭代对象,它支持自动批处理、多进程数据加载以及许多其他功能,用于在数据集上进行迭代。数据加载器通过调用数据集的 __getitem__ 函数与数据集通信,并将输出沿着第一维堆叠为张量以形成一个批次。
与数据集类不同,通常不需要自己定义数据加载器类,而是可以直接使用数据集作为输入创建一个数据加载器对象。此外,可以通过以下输入参数(仅列出部分)来配置数据加载器:
batch_size:每个批次堆叠的样本数量。shuffle:如果为 True,则数据将以随机顺序返回。这在训练过程中非常重要,因为它可以引入随机性。num_workers:用于数据加载的子进程数量。默认值为 0,表示数据将在主进程中加载,这可能会使加载单个数据点需要较长时间的数据集(例如大型图像)的训练变慢。对于这些数据集,建议使用更多工作进程,但在 Windows 系统上可能会导致问题。对于我们的小型数据集,通常使用 0 个工作进程会更快。pin_memory:如果为 True,数据加载器会在返回数据之前将张量复制到 CUDA 固定内存中。这可以在 GPU 上为大型数据点节省一些时间。通常建议在训练集上使用此功能,但在验证集和测试集上不一定需要,以节省 GPU 内存。drop_last:如果为 True,当最后一个批次小于指定的批次大小时,该批次将被丢弃。这发生在数据集大小不是批次大小的倍数时。在训练过程中,为了保持一致的批次大小,这可能很有用。
下面创建一个简单的数据加载器:
data_loader = data.DataLoader(dataset, batch_size=8, shuffle=True)
# next(iter(...)) 会捕获数据加载器的第一个批次
# 如果 shuffle 为 True,则每次运行此单元格时都会返回不同的批次
# 对于遍历整个数据集,我们可以简单地使用 "for batch in data_loader: ..."
data_inputs, data_labels = next(iter(data_loader))
# 输出的形状为 [batch_size, d_1,...,d_N],其中 d_1,...,d_N 是从数据集类返回的数据点的维度
print("Data inputs", data_inputs.shape, "\n", data_inputs)
print("Data labels", data_labels.shape, "\n", data_labels)
2.3 优化
在定义了模型和数据集之后,接下来就是准备模型的优化过程。在训练过程中,我们将执行以下步骤:
- 从数据加载器中获取一个批次。
- 获取模型对当前批次的预测结果。
- 根据预测结果与标签之间的差异计算损失。
- 反向传播:计算每个参数相对于损失的梯度。
- 沿着梯度的方向更新模型的参数。
已经在 PyTorch 中看到了如何执行步骤 1、2 和 4。现在,我们将关注步骤 3 和 5。
2.3.1 损失模块
可以通过简单地执行一些张量操作来计算一个批次的损失,因为这些操作会自动添加到计算图中。例如,对于二分类任务,可以使用二元交叉熵(BCE),其定义如下:
L B C E = − ∑ i [ y i log x i + ( 1 − y i ) log ( 1 − x i ) ] \mathcal{L}_{BCE} = -\sum_i \left[ y_i \log x_i + (1 - y_i) \log (1 - x_i) \right] LBCE=−i∑[yilogxi+(1−yi)log(1−xi)]
其中,
y
y
y 是标签,
x
x
x 是预测值,它们都位于
[
0
,
1
]
[0,1]
[0,1] 范围内。然而,PyTorch 已经提供了一系列预定义的损失函数,可以直接使用。例如,对于 BCE,PyTorch 提供了两个模块:nn.BCELoss() 和 nn.BCEWithLogitsLoss()。nn.BCELoss 需要输入
x
x
x 在
[
0
,
1
]
[0,1]
[0,1] 范围内,即 Sigmoid 的输出,而 nn.BCEWithLogitsLoss 将 Sigmoid 层和 BCE 损失结合在一个类中。由于损失函数中应用了对数,因此 nn.BCEWithLogitsLoss 比直接使用 Sigmoid 后跟 BCE 损失在数值上更稳定。因此,建议尽可能使用应用于“logits”(原始输出)的损失函数(在这种情况下,记得不要在模型输出上应用 Sigmoid)。对于上面定义的模型,我们因此使用 nn.BCEWithLogitsLoss 模块。
loss_module = nn.BCEWithLogitsLoss()
2.3.2 随机梯度下降
为了更新参数,PyTorch 提供了 torch.optim 包,其中实现了大多数流行的优化器。将在课程的后续部分讨论具体的优化器及其差异,但目前实验中先使用其中最简单的一个:torch.optim.SGD。随机梯度下降(SGD)通过将梯度乘以一个小常数(称为学习率)并从参数中减去这些值来更新参数(从而最小化损失)。因此,逐渐向最小化损失的方向移动。对于像实验中这样的小型网络,学习率的一个良好默认值是 0.1。
# 优化器的输入是模型的参数:model.parameters()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
优化器提供了两个非常有用的函数:optimizer.step() 和 optimizer.zero_grad()。step 函数根据上述方式基于梯度更新参数。optimizer.zero_grad() 函数将所有参数的梯度设置为零。尽管这个函数乍看之下似乎不太重要,但它是在执行反向传播之前的关键步骤。如果对损失调用 backward 函数时,参数的梯度仍然保留了上一个批次的值,那么新的梯度实际上会被加到之前的梯度上,而不是覆盖它们。这是因为在计算图中,一个参数可能会多次出现,需要在这种情况下累加梯度,而不是替换它们。因此,请记住在计算一个批次的梯度之前调用 optimizer.zero_grad()。
2.4 训练
现在,可以开始训练本课程的模型了。作为第一步,创建一个稍微大一些的数据集,并指定一个具有更大批次大小的数据加载器。
train_dataset = XORDataset(size=2500)
train_data_loader = data.DataLoader(train_dataset, batch_size=128, shuffle=True)
现在,可以编写一个简单的训练函数。请记住之前的五个步骤:加载一个批次、获取预测结果、计算损失、反向传播和更新参数。此外,还需要将所有数据和模型参数推送到选择的设备上。对于小型神经网络,将数据传输到 NPU 的时间实际上比在 CPU 上运行操作所用的时间要多得多。对于大型网络,通信时间显著小于实际运行时间,在这种情况下 NPU 是至关重要的。
# 将模型推送到设备。只需执行一次
device = 'cpu'
model.to(device)
此外,将模型设置为训练模式。这可以通过调用 model.train() 来实现。某些模块在训练期间和测试期间需要执行不同的前向步骤(例如 BatchNorm 和 Dropout),可以通过调用 model.train() 和 model.eval() 在它们之间切换。
def train_model(model, optimizer, data_loader, loss_module, num_epochs=100):
# 将模型设置为训练模式
model.train()
# Training loop
for epoch in tqdm(range(num_epochs)):
for data_inputs, data_labels in data_loader:
## 步骤 1:将输入数据移至设备(仅在使用 GPU 时严格需要)
data_inputs = data_inputs.to(device)
data_labels = data_labels.to(device)
## 步骤 2:在输入数据上运行模型
preds = model(data_inputs)
preds = preds.squeeze(dim=1) # 输出是 [Batch size, 1],但我们想要 [Batch size]
## 步骤 3:计算损失
loss = loss_module(preds, data_labels.float())
## 步骤 4:执行反向传播
# 在计算梯度之前,我们需要确保它们都为零。
# 梯度不会被覆盖,而是会加到现有的梯度上。
optimizer.zero_grad()
# 执行反向传播
loss.backward()
## 步骤 5:更新参数
optimizer.step()
train_model(model, optimizer, train_data_loader, loss_module)
2.4.1 保存模型
完成模型训练后,将模型保存到磁盘中,以便在以后加载相同的权重。为此,从模型中提取所谓的 state_dict,其中包含所有可学习的参数。对于简单模型,state_dict 包含以下条目:
state_dict = model.state_dict()
print(state_dict)
为了保存状态字典,可以使用 torch.save:
# torch.save(object, filename)。对于文件名,可以使用任何扩展名
torch.save(state_dict, "our_model.tar")
为了从状态字典加载模型,使用 torch.load 函数从磁盘加载状态字典,并使用模块的 load_state_dict 函数来覆盖参数以使用新的值:
# 从磁盘加载状态字典(确保与上面的名称相同)
state_dict = torch.load("our_model.tar")
# 创建一个新模型并加载状态
new_model = SimpleClassifier(num_inputs=2, num_hidden=4, num_outputs=1)
new_model.load_state_dict(state_dict)
# 验证参数是否相同
print("Original model\n", model.state_dict())
print("\nLoaded model\n", new_model.state_dict())
2.5 评估
当训练好一个模型后,就到了在保留的测试集上对其进行评估的时候了。由于数据集是由随机生成的数据点组成的,因此首先需要创建一个测试集及其对应的数据加载器。
test_dataset = XORDataset(size=500)
# drop_last -> 不要丢弃最后一个批次,尽管它小于 128
test_data_loader = data.DataLoader(test_dataset, batch_size=128, shuffle=False, drop_last=False)
作为评估指标,我们将使用准确率(accuracy),其计算公式如下:
a c c = # correct predictions # all predictions = T P + T N T P + T N + F P + F N acc = \frac{\#\text{correct predictions}}{\#\text{all predictions}} = \frac{TP+TN}{TP+TN+FP+FN} acc=#all predictions#correct predictions=TP+TN+FP+FNTP+TN
其中,TP 表示真正例(True Positives),TN 表示真负例(True Negatives),FP 表示假正例(False Positives),FN 表示假负例(False Negatives)。
在评估模型时,不需要跟踪计算图,因为并不打算计算梯度。这可以减少所需的内存并加速模型的运行。在 PyTorch 中,可以通过使用 with torch.no_grad(): ... 来停用计算图。记得还要将模型设置为评估模式。
def eval_model(model, data_loader):
model.eval() # 将模型设置为评估模式
true_preds, num_preds = 0., 0.
with torch.no_grad(): # 停用以下代码的梯度
for data_inputs, data_labels in data_loader:
# 确定模型在开发集上的预测结果
data_inputs, data_labels = data_inputs.to(device), data_labels.to(device)
preds = model(data_inputs)
preds = preds.squeeze(dim=1)
preds = torch.sigmoid(preds) # 使用 Sigmoid 将预测值映射到 0 和 1 之间
pred_labels = (preds >= 0.5).long() # 将预测值二值化为 0 和 1
# 记录预测值以用于准确率指标(true_preds=TP+TN,num_preds=TP+TN+FP+FN)
true_preds += (pred_labels == data_labels).sum()
num_preds += data_labels.shape[0]
acc = true_preds / num_preds
print(f"Accuracy of the model: {100.0*acc:4.2f}%")
eval_model(model, test_data_loader)
如果正确地训练了模型,应该会看到接近 100% 的准确率。然而,这只有在任务非常简单的情况下才可能实现,不幸的是,在更复杂任务的测试集上,通常无法获得如此高的分数。
2.5.1 可视化分类边界
为了可视化模型所学到的内容,可以在范围 [ − 0.5 , 1.5 ] [-0.5, 1.5] [−0.5,1.5] 内对每个数据点进行预测,并像本节开头的示例图那样可视化预测的类别。这将展示模型创建的决策边界,以及哪些点会被分类为 0 0 0,哪些点会被分类为 1 1 1。因此,将得到一个背景图像,其中蓝色(类别 0)和橙色(类别 1)区域分别表示不同的类别。模型不确定的地方会看到模糊的重叠区域。具体的代码与输出图像相比不太重要,而输出图像应该能清晰地显示出类别的分隔:
@torch.no_grad() # 装饰器,与在整个函数上使用 "with torch.no_grad(): ..." 具有相同的效果。
def visualize_classification(model, data, label):
if isinstance(data, torch.Tensor):
data = data.cpu().numpy()
if isinstance(label, torch.Tensor):
label = label.cpu().numpy()
data_0 = data[label == 0]
data_1 = data[label == 1]
fig = plt.figure(figsize=(4,4), dpi=500)
plt.scatter(data_0[:,0], data_0[:,1], edgecolor="#333", label="Class 0")
plt.scatter(data_1[:,0], data_1[:,1], edgecolor="#333", label="Class 1")
plt.title("Dataset samples")
plt.ylabel(r"$x_2$")
plt.xlabel(r"$x_1$")
plt.legend()
# 让我们充分利用上面学到的许多操作
model.to(device)
c0 = torch.Tensor(to_rgba("C0")).to(device)
c1 = torch.Tensor(to_rgba("C1")).to(device)
x1 = torch.arange(-0.5, 1.5, step=0.01, device=device)
x2 = torch.arange(-0.5, 1.5, step=0.01, device=device)
xx1, xx2 = torch.meshgrid(x1, x2, indexing='ij') # 与 numpy 中的 meshgrid 函数相同
model_inputs = torch.stack([xx1, xx2], dim=-1)
preds = model(model_inputs)
preds = torch.sigmoid(preds)
output_image = (1 - preds) * c0[None,None] + preds * c1[None,None] # 在维度中指定 "None" 会创建一个新的维度
output_image = output_image.cpu().numpy() # 转换为 numpy 数组。这仅适用于 CPU 上的张量,因此首先需要将其推送到 CPU
plt.imshow(output_image, origin='lower', extent=(-0.5, 1.5, -0.5, 1.5))
plt.grid(False)
return fig
_ = visualize_classification(model, dataset.data, dataset.label)
plt.show()
决策边界可能与本课程2.2.1中的图像不完全相同,这的确具有一定随机性。然而,准确率指标的结果应该大致相同。


















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









