



- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用
使用SimCLR进行自我监督对比学习
学习目标
本课程将带领学者通过SimCLR与Logistic 回归对数据进行训练以及测试,进行自我监督学习的对比。
相关知识点
- 使用SimCLR进行自我监督对比学习
学习内容
1 使用SimCLR进行自我监督对比学习
1.1 SimCLR
SimCLR(Simple Contrastive Learning of Visual Representations)是Google于2020年提出的简单对比学习框架,核心目标是通过无监督学习,从海量未标注图像中学习通用、鲁棒的视觉特征,为下游任务(如图像分类、检测)提供优质预训练模型。其核心特点是“简洁高效”,摒弃了早期对比学习中复杂的架构设计(如需要专门的记忆库),仅通过基础组件实现了当时领先的无监督特征学习效果。
-
核心原理:对比学习的“正负样本”逻辑
对比学习的本质是“让相似样本的特征更接近,不相似样本的特征更疏远” -
应用场景
SimCLR的核心价值是为计算机视觉任务提供无监督预训练模型:
1.当标注数据稀缺时(如下游分类任务只有少量标注图),用SimCLR在未标注数据上预训练,再微调下游任务模型,能大幅提升性能;
2.为图像检索、目标检测等任务提供高质量的初始特征,降低后续训练难度。
1.1.1 实验前准备
##安装完重启内核
%pip install pytorch_lightning
%pip install seaborn
%pip install tensorboard
%pip install --upgrade ipywidgets
%pip install --upgrade jupyterlab
- 从obs桶中下载数据和模型权重
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_datasets/6130d176102e11f0b67bfa163edcddae/stl10_binary.zip
!unzip stl10_binary.zip
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_models/7fd174a6103211f0b67bfa163edcddae/saved_models.zip
!unzip saved_models.zip
在这个实验中,我们将更深入地探讨自监督对比学习。自监督学习(有时也称为无监督学习)描述了这样一种情况:我们有输入数据,但没有用于经典监督学习的标签。然而,这些数据仍然包含大量我们可以学习的信息:图像之间有什么不同?哪些模式对某些图像具有描述性?我们能否对图像进行聚类?等等。自监督学习方法试图从数据本身尽可能多地学习,以便能够快速微调用于特定分类任务的模型。
自监督学习的好处是,我们可以轻松获得大量数据集。例如,如果我们想在自动驾驶的语义分割任务上训练一个视觉模型,我们可以通过在汽车上安装摄像头并在城市中行驶一小时来收集大量数据。相比之下,如果我们想进行监督学习,我们需要在训练模型之前手动标记所有这些图像。这非常昂贵,手动标记相同数量的数据可能需要几个月的时间。此外,自监督学习可以为从 ImageNet 预训练模型的迁移学习提供替代方案,因为我们可以针对特定数据集/情况(例如自动驾驶的交通场景)预训练一个模型。
在过去的两年里,针对图像的自监督学习提出了许多新的方法,这些方法在只有少量标签可用时与监督模型相比取得了巨大进步。在本课程中,我们将专注于对比学习这一子领域。对比学习的动机是上面提到的问题:图像之间有什么不同?具体来说,对比学习方法训练模型将图像及其略微增强的版本在潜在空间中聚类,同时最大化与其他图像的距离。一个非常新且简单的方法是 SimCLR,其可视化如下图所示(图片来源于 Ting Chen 等人)。
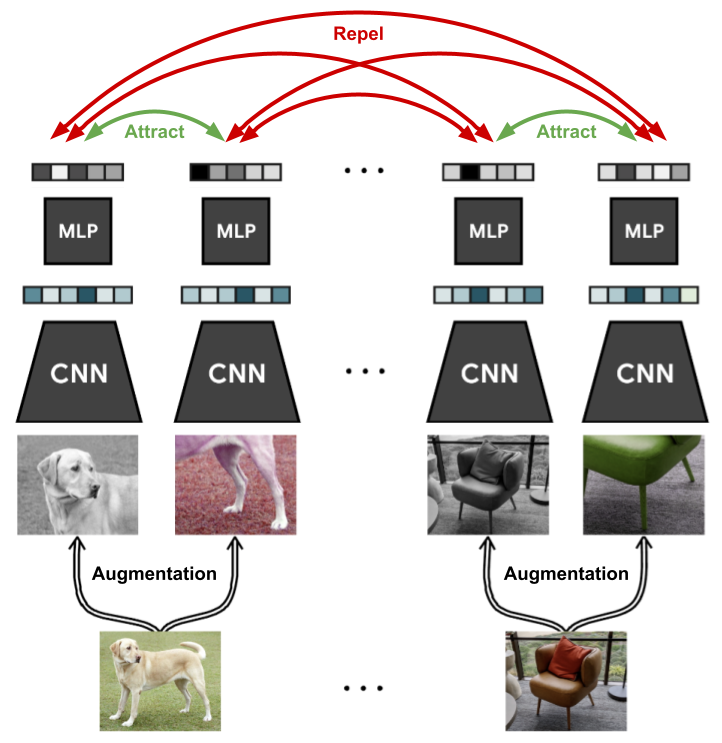
一般情况下,我们有一个没有标签的图像数据集,并希望在这个数据上训练一个模型,使其能够快速适应任何图像识别任务。在每次训练迭代中,我们像往常一样采样一批图像。对于每张图像,我们通过应用数据增强技术(如裁剪、高斯噪声、模糊等)创建两个版本。左边的狗的图像展示了这样的一个例子。我们稍后会详细讨论所选增强技术的细节及其影响。在这些图像上,我们应用一个卷积神经网络(如 ResNet),并获得一个一维特征向量作为输出,然后对其应用一个小的多层感知机(MLP)。然后,我们训练这两个增强图像的输出特征彼此接近,而该批次中的所有其他图像应尽可能不同。通过这种方式,模型必须学会识别在数据增强下保持不变的图像内容,例如在监督任务中我们通常关心的物体。
接下来,我们将自己实现这个框架,并在实现过程中进一步讨论细节。首先,我们从导入标准库开始:
from copy import deepcopy
%reload_ext tensorboard
import os
os.environ.pop('MPLBACKEND', None)
## Imports for plotting
import matplotlib.pyplot as plt
plt.set_cmap('cividis')
%matplotlib inline
from matplotlib_inline.backend_inline import set_matplotlib_formats
set_matplotlib_formats('svg', 'pdf')
import matplotlib
matplotlib.rcParams['lines.linewidth'] = 2.0
import seaborn as sns
sns.set()
from tqdm.notebook import tqdm
## PyTorch
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import torch.optim as optim
import torch_npu
import torchvision
from torchvision.datasets import STL10
from torchvision import transforms
try:
import pytorch_lightning as pl
except ModuleNotFoundError:
!pip install --quiet pytorch-lightning>=1.4
import pytorch_lightning as pl
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
import tensorboard
%load_ext tensorboard
import warnings
warnings.filterwarnings("ignore", category=UserWarning, module="torch_npu")
DATASET_PATH = "data"
CHECKPOINT_PATH = "saved_models/tutorial17"
NUM_WORKERS = os.cpu_count()
pl.seed_everything(42)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device("cpu")
print("Device:", device)
print("Number of workers:", NUM_WORKERS)
SimCLR:我们将通过讨论不同数据增强技术的效果以及如何为这些技术实现高效的数据加载器,开始探索对比学习。接下来,我们使用 PyTorch Lightning 实现 SimCLR,并最终在一个大型的、未标记的数据集上对其进行训练。
用于对比学习的数据增强:为了实现高效的训练,我们需要准备数据加载,以便对每个批次中的每张图像采样两个不同的、随机的增强版本。实现这一点最简单的方法是创建一个转换,当被调用时,它会对图像应用两次一组数据增强。这在下面的ContrastiveTransformations类中实现了:
class ContrastiveTransformations(object):
def __init__(self, base_transforms, n_views=2):
self.base_transforms = base_transforms
self.n_views = n_views
def __call__(self, x):
return [self.base_transforms(x) for i in range(self.n_views)]
对比学习框架很容易通过采样同一图像的多个增强版本来获得更多正样本。然而,通常使用两个增强版本就能获得最高效的训练。
接下来,我们可以看看我们想要应用的具体增强方法。在SimCLR中,选择数据增强是最关键的超参数,因为它直接影响潜在空间的结构,以及从数据中可能学到的模式。让我们先来看看一些最受欢迎的数据增强方法:

它们都可以使用,但事实证明,两个增强功能的重要性非常突出:裁剪和调整大小以及颜色失真。只有当它们一起使用时,它们才会产生强大的性能。在执行随机裁剪和调整大小时,我们可以区分两种情况:(a) 裁剪后的图像 A 提供裁剪后图像 B 的局部视图,或 (b) 裁剪后的图像 C 和 D 显示同一图像的相邻视图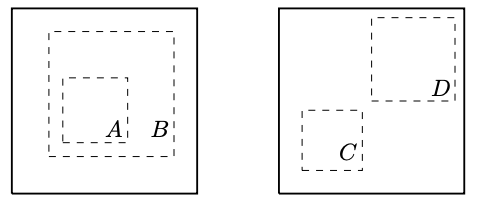
虽然情况(a)要求模型学习某种尺度不变性,以使作物A和B在潜在空间中相似,但情况(b)更具挑战性,因为模型需要在有限的视野之外识别物体。然而,在没有颜色失真的情况下,模型可以利用一个漏洞,即同一图像的不同裁剪通常在颜色空间中看起来非常相似。考虑上面的狗的照片。仅从毛色和背景的绿色调来看,你可以推断出两个小块属于同一张图片,而无需真正识别图片中的狗。在这种情况下,模型最终可能会只关注图像的颜色直方图,而忽略其他更具泛化性的特征。然而,如果我们随机且独立地扭曲两个小块的颜色,模型就不能再依赖这一简单特征了。因此,通过结合随机裁剪和颜色扭曲,模型只能通过学习更具泛化性的表示来匹配两个小块。
总体而言,在我们的实验中,我们应用了一组5种变换,遵循原始SimCLR设置:随机水平翻转、裁剪并调整大小、颜色扭曲、随机灰度化和高斯模糊。与原始实现相比,我们略微降低了颜色抖动的效果(亮度、对比度和饱和度从0.8降至0.5,色调从0.2降至0.1)。在我们的实验中,这种设置获得了更好的性能,并且训练起来更快、更稳定。例如,如果数据集中亮度尺度变化很大,原始设置可能会更有益,因为模型不能依赖这一信息来区分图像了。
contrast_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96),
transforms.RandomApply([
transforms.ColorJitter(brightness=0.5,
contrast=0.5,
saturation=0.5,
hue=0.1)
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
在讨论了数据增强技术之后,我们现在可以专注于数据集。在本课程中,我们将使用STL10数据集,它类似于CIFAR10,包含10个类别的图像:飞机、鸟、汽车、猫、鹿、狗、马、猴子、船和卡车。然而,这些图像的分辨率更高,为96×96像素,我们每个类别只有500张标记图像。此外,我们还有一个包含10万张未标记图像的更大集合,这些图像与训练图像相似,但采样自更广泛的动物和交通工具。这使得该数据集非常适合展示自监督学习所提供的优势。
幸运的是,STL10数据集可以通过torchvision获得。不过,由于这个数据集相对较大,其分辨率比CIFAR10高得多,因此需要更多的磁盘空间(约3GB),并且下载需要一些时间。在我们对自监督学习和SimCLR进行初步讨论时,我们将使用上述对比变换创建两个数据加载器:unlabeled_data将用于通过对比学习训练我们的模型,而train_data_contrast将用作对比学习中的验证集。
unlabeled_data = STL10(root=DATASET_PATH, split='unlabeled', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
train_data_contrast = STL10(root=DATASET_PATH, split='train', download=True,
transform=ContrastiveTransformations(contrast_transforms, n_views=2))
最后,在开始实现SimCLR之前,让我们先看看一些使用我们的增强方法采样的示例图像对:
pl.seed_everything(42)
NUM_IMAGES = 6
imgs = torch.stack([img for idx in range(NUM_IMAGES) for img in unlabeled_data[idx][0]], dim=0)
img_grid = torchvision.utils.make_grid(imgs, nrow=6, normalize=True, pad_value=0.9)
img_grid = img_grid.permute(1, 2, 0)
plt.figure(figsize=(10,5))
plt.title('Augmented image examples of the STL10 dataset')
plt.imshow(img_grid)
plt.axis('off')
plt.show()
plt.close()

我们看到了数据增强的多样性,包括随机裁剪、灰度化、高斯模糊和颜色扭曲。因此,对于模型来说,匹配同一图像的两个独立增强后的图像块仍然是一个具有挑战性的任务。
1.1.2 SimCLR 实现
使用上述的数据加载器管道,我们现在可以实现 SimCLR。在每次迭代中,我们为每张图像 ( x ) ( x ) (x) 获取两个不同增强版本,我们将其称为 ( x ~ i \tilde{x}_i x~i) 和 ( x ~ j \tilde{x}_j x~j )。这两个图像都被编码成一维特征向量,我们希望最大化这两个向量之间的相似性,同时将其与其他所有图像的相似性最小化。编码器网络分为两部分:基础编码器网络 ( f ( ⋅ ) f(\cdot) f(⋅) ) 和投影头 ( g ( ⋅ ) g(\cdot) g(⋅) )。基础网络通常是一个深度卷积神经网络(CNN),在我们的实验中,我们将使用常见的 ResNet-18 架构作为 ( f ( ⋅ ) f(\cdot) f(⋅) ),并将其输出称为 ( f ( x ~ i ) = h i f(\tilde{x}_i) = h_i f(x~i)=hi )。投影头 ( g ( ⋅ ) g(\cdot) g(⋅) ) 将表示 ( h h h ) 映射到一个空间,在这个空间中我们应用对比损失,即比较向量之间的相似性。它通常被选择为一个带有非线性的小型多层感知机(MLP),为了简单起见,我们遵循原始 SimCLR 论文的设置,将其定义为一个两层的 MLP,隐藏层使用 ReLU 激活函数。需要注意的是,在后续论文 SimCLRv2 中,作者提到更大的/更宽的 MLP 可以显著提升性能。这就是为什么我们在隐藏层使用四倍更大的维度,但更深的 MLP 在给定的数据集上显示出过拟合的迹象。总体设置如下图所示(图片来源于 Ting Chen 等人):
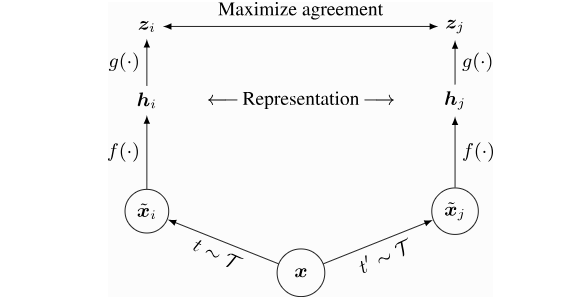
完成对比学习训练后,我们将移除投影头 g ( ⋅ ) g(\cdot) g(⋅),并使用 f ( ⋅ ) f(\cdot) f(⋅) 作为预训练的特征提取器。从投影头 g ( ⋅ ) g(\cdot) g(⋅) 输出的表示 z z z 在微调网络用于新任务时,表现不如基础网络 f ( ⋅ ) f(\cdot) f(⋅) 的表示。这可能是因为表示 ( z ) 被训练成对许多特征(如颜色)不变,而这些特征对于下游任务可能是重要的。因此, g ( ⋅ ) g(\cdot) g(⋅) 只在对比学习阶段需要。
现在架构已经描述完毕,让我们更仔细地看看如何训练模型。正如前面提到的,我们希望最大化同一图像的两个增强版本的表示之间的相似性,即上图中的 z i z_i zi 和 z j z_j zj,同时将其与其他所有样本的相似性最小化。SimCLR应用了InfoNCE损失,最初由 Aaron van den Oord et al. 提出用于对比学习。简而言之,InfoNCE损失通过在相似度值上执行softmax操作,比较 z i z_i zi 和 z j z_j zj 的相似度与 z i z_i zi与其他任何表示的相似度。损失可以正式写为:
ℓ i , j = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( sim ( z i , z k ) / τ ) = − sim ( z i , z j ) / τ + log [ ∑ k = 1 2 N 1 [ k ≠ i ] exp ( sim ( z i , z k ) / τ ) ] \ell_{i,j}=-\log \frac{\exp(\text{sim}(z_i,z_j)/\tau)}{\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(\text{sim}(z_i,z_k)/\tau)}=-\text{sim}(z_i,z_j)/\tau+\log\left[\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(\text{sim}(z_i,z_k)/\tau)\right] ℓi,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)=−sim(zi,zj)/τ+log[k=1∑2N1[k=i]exp(sim(zi,zk)/τ)]
函数 sim \text{sim} sim 是一个相似性度量,超参数 τ \tau τ 称为温度,它决定了分布的尖锐程度。由于许多相似性度量是有界的,温度参数允许我们在许多不相似的图像块与一个相似的图像块之间平衡影响。SimCLR中使用的相似性度量是余弦相似性,定义如下:
sim ( z i , z j ) = z i ⊤ ⋅ z j ∣ ∣ z i ∣ ∣ ⋅ ∣ ∣ z j ∣ ∣ \text{sim}(z_i,z_j) = \frac{z_i^\top \cdot z_j}{||z_i||\cdot||z_j||} sim(zi,zj)=∣∣zi∣∣⋅∣∣zj∣∣zi⊤⋅zj
余弦相似性的最大值为 1 1 1,最小值为 − 1 -1 −1.一般来说,我们会看到不同图像的特征会收敛到余弦相似性大约为零,因为最小值 − 1 -1 −1 要求 z i z_i zi 和 z j z_j zj 在所有特征维度上完全相反,这限制了灵活性。
最后,现在我们已经讨论了所有细节,让我们在下面实现SimCLR作为一个PyTorch Lightning模块。
class SimCLR(pl.LightningModule):
def __init__(self, hidden_dim, lr, temperature, weight_decay, max_epochs=500):
super().__init__()
self.save_hyperparameters()
assert self.hparams.temperature > 0.0, 'The temperature must be a positive float!'
self.convnet = torchvision.models.resnet18(num_classes=4*hidden_dim)
self.convnet.fc = nn.Sequential(
self.convnet.fc,
nn.ReLU(inplace=True),
nn.Linear(4*hidden_dim, hidden_dim)
)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer,
T_max=self.hparams.max_epochs,
eta_min=self.hparams.lr/50)
return [optimizer], [lr_scheduler]
def info_nce_loss(self, batch, mode='train'):
imgs, _ = batch
imgs = torch.cat(imgs, dim=0)
feats = self.convnet(imgs)
cos_sim = F.cosine_similarity(feats[:,None,:], feats[None,:,:], dim=-1)
self_mask = torch.eye(cos_sim.shape[0], dtype=torch.bool, device=cos_sim.device)
cos_sim.masked_fill_(self_mask, -9e15)
pos_mask = self_mask.roll(shifts=cos_sim.shape[0]//2, dims=0)
cos_sim = cos_sim / self.hparams.temperature
nll = -cos_sim[pos_mask] + torch.logsumexp(cos_sim, dim=-1)
nll = nll.mean()
self.log(mode+'_loss', nll)
comb_sim = torch.cat([cos_sim[pos_mask][:,None],
cos_sim.masked_fill(pos_mask, -9e15)],
dim=-1)
sim_argsort = comb_sim.argsort(dim=-1, descending=True).argmin(dim=-1)
self.log(mode+'_acc_top1', (sim_argsort == 0).float().mean())
self.log(mode+'_acc_top5', (sim_argsort < 5).float().mean())
self.log(mode+'_acc_mean_pos', 1+sim_argsort.float().mean())
return nll
def training_step(self, batch, batch_idx):
return self.info_nce_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self.info_nce_loss(batch, mode='val')
除了对对比学习损失进行验证之外,我们还可以采用一个简单的小型下游任务,并跟踪基础网络 f ( ⋅ ) f(\cdot) f(⋅) 在该任务上的性能。然而,在本课程中,我们将仅限于使用 STL10 数据集,其中我们将 STL10 上的图像分类任务作为我们的测试任务。
1.1.3 SimCLR训练
现在我们已经实现了SimCLR和数据加载管道,我们就可以开始训练模型了。我们将使用与以往相同的训练函数设置。为了保存最佳模型检查点,我们跟踪val_acc_top5这一指标,它描述的是正确图像块在批次中出现在最相似的5个示例中的频率。这一指标通常比top-1指标的波动更小,因此更适合用来选择最佳模型。
在对比学习中,一个常见的观察结果是:批量大小越大,模型的性能越好。较大的批量大小使我们能够将每张图像与更多的负样本进行比较,从而导致整体损失梯度更加平滑。然而,在我们的情况下,我们发现256的批量大小就足以获得良好的结果。
simclr_model = train_simclr(batch_size=256,
hidden_dim=128,
lr=5e-4,
temperature=0.07,
weight_decay=1e-4,
max_epochs=500)
1.2 Logistic 回归
在通过对比学习训练好我们的模型之后,我们可以在下游任务上部署它,并看看它在数据很少的情况下表现如何。一个常见的设置(也可以验证模型是否学到了泛化的表示)是在特征上执行逻辑回归。换句话说,我们学习一个单一的线性层,将表示映射到类别预测上。由于在训练过程中基础网络 f ( ⋅ ) f(\cdot) f(⋅) 没有改变,所以模型只有在 h h h 的表示描述了任务可能需要的所有特征时,才能表现良好。此外,由于我们训练的参数很少,我们不必太担心过拟合。因此,我们可能会期望即使数据很少,模型也能表现良好。
首先,让我们实现一个简单的逻辑回归设置,我们假设图像已经被编码到它们的特征向量中。如果数据很少,那么在训练期间动态地对图像进行编码可能更有益,这样我们也可以应用数据增强。然而,我们在这里实现的方式要高效得多,并且可以在几秒钟内完成训练。此外,在这个简单的设置中,使用数据增强并没有显示出任何显著的增益。
1.2.1 Logistic 回归前处理
在通过对比学习训练完模型后,我们可以将其部署到下游任务中,并看看它在数据量较少的情况下表现如何。一个常见的设置(也用于验证模型是否学习到了通用的表示)是在特征上执行逻辑回归。换句话说,我们学习一个单一的线性层,将表示映射到类别预测。由于基础网络 f ( ⋅ ) f(\cdot) f(⋅) 在训练过程中不会改变,模型只有在表示 h h h 描述了任务所需的所有特征时,才可能表现良好。此外,由于我们训练的参数非常少,我们不需要太担心过拟合的问题。因此,我们可能期望即使在数据量非常少的情况下,模型也能表现良好。
首先,我们实现一个简单的逻辑回归设置,假设图像已经被编码为特征向量。如果可用的数据非常少,那么在训练过程中动态编码图像(以便同时应用数据增强)可能会更有益。然而,我们在这里实现的方式效率更高,可以在几秒钟内完成训练。此外,在这种简单的设置中,使用数据增强并没有显示出任何显著的增益。
class LogisticRegression(pl.LightningModule):
def __init__(self, feature_dim, num_classes, lr, weight_decay, max_epochs=100):
super().__init__()
self.save_hyperparameters()
self.model = nn.Linear(feature_dim, num_classes)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.6),
int(self.hparams.max_epochs*0.8)],
gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode='train'):
feats, labels = batch
preds = self.model(feats)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss
def training_step(self, batch, batch_idx):
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='test')
我们使用的数据是STL10的训练集和测试集。训练集包含每个类别500张图像,而测试集每个类别有800张图像。
img_transforms = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
train_img_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=img_transforms)
test_img_data = STL10(root=DATASET_PATH, split='test', download=True,
transform=img_transforms)
print("Number of training examples:", len(train_img_data))
print("Number of test examples:", len(test_img_data))
Out:
Number of training examples: 5000
Number of test examples: 8000
接下来,我们实现一个小函数来对数据集中的所有图像进行编码。输出的表示将被用作逻辑回归模型的输入。
@torch.no_grad()
def prepare_data_features(model, dataset):
# Prepare model
network = deepcopy(model.convnet)
network.fc = nn.Identity()
network.eval()
network.to(device)
data_loader = data.DataLoader(dataset, batch_size=64, num_workers=NUM_WORKERS, shuffle=False, drop_last=False)
feats, labels = [], []
for batch_imgs, batch_labels in tqdm(data_loader):
batch_imgs = batch_imgs.to(device)
batch_feats = network(batch_imgs)
feats.append(batch_feats.detach().cpu())
labels.append(batch_labels)
feats = torch.cat(feats, dim=0)
labels = torch.cat(labels, dim=0)
labels, idxs = labels.sort()
feats = feats[idxs]
return data.TensorDataset(feats, labels)
1.2.2 Logistic 回归训练
让我们在训练集和测试集上都应用这个函数。
train_feats_simclr = prepare_data_features(simclr_model, train_img_data)
test_feats_simclr = prepare_data_features(simclr_model, test_img_data)
最后,我们可以像往常一样编写一个训练函数。我们每10个epoch在测试集上评估一次模型,以便进行早停(early stopping),但验证的低频率也确保了我们不会在测试集上过度拟合。
def train_logreg(batch_size, train_feats_data, test_feats_data, model_suffix, max_epochs=100, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "LogisticRegression"),
accelerator="gpu" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode='max', monitor='val_acc'),
LearningRateMonitor("epoch")],
enable_progress_bar=False,
check_val_every_n_epoch=10)
trainer.logger._default_hp_metric = None
train_loader = data.DataLoader(train_feats_data, batch_size=batch_size, shuffle=True,
drop_last=False, pin_memory=True, num_workers=0)
test_loader = data.DataLoader(test_feats_data, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=0)
pretrained_filename = os.path.join(CHECKPOINT_PATH, f"LogisticRegression_{model_suffix}.ckpt")
if os.path.isfile(pretrained_filename):
print(f"Found pretrained model at {pretrained_filename}, loading...")
model = LogisticRegression.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42)
model = LogisticRegression(**kwargs)
trainer.fit(model, train_loader, test_loader)
model = LogisticRegression.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
train_result = trainer.test(model, train_loader, verbose=False)
test_result = trainer.test(model, test_loader, verbose=False)
result = {"train": train_result[0]["test_acc"], "test": test_result[0]["test_acc"]}
return model, result
尽管 STL10 的训练数据集每个类别只有 500 张标记图像,我们仍将进行使用更小数据集的实验。具体来说,我们将为每个类别只有 10、20、50、100、200 和全部 500 个样本的数据集训练逻辑回归模型。这可以让我们直观地了解通过对比学习学到的表示在像这种分类任务这样的图像识别任务中可以被转移得有多好。首先,让我们定义一个函数,从完整的训练集中创建目标子数据集:
def get_smaller_dataset(original_dataset, num_imgs_per_label):
new_dataset = data.TensorDataset(
*[t.unflatten(0, (10, -1))[:,:num_imgs_per_label].flatten(0, 1) for t in original_dataset.tensors]
)
return new_dataset
接下来,让我们运行所有模型。尽管我们要训练6个模型,但如果没有预训练模型,这个单元格可能在一两分钟内就能运行完成。
results = {}
for num_imgs_per_label in [10, 20, 50, 100, 200, 500]:
sub_train_set = get_smaller_dataset(train_feats_simclr, num_imgs_per_label)
_, small_set_results = train_logreg(batch_size=512,
train_feats_data=sub_train_set,
test_feats_data=test_feats_simclr,
model_suffix=num_imgs_per_label,
feature_dim=train_feats_simclr.tensors[0].shape[1],
num_classes=10,
lr=1e-3,
weight_decay=1e-3)
results[num_imgs_per_label] = small_set_results
最后,让我们绘制结果图。
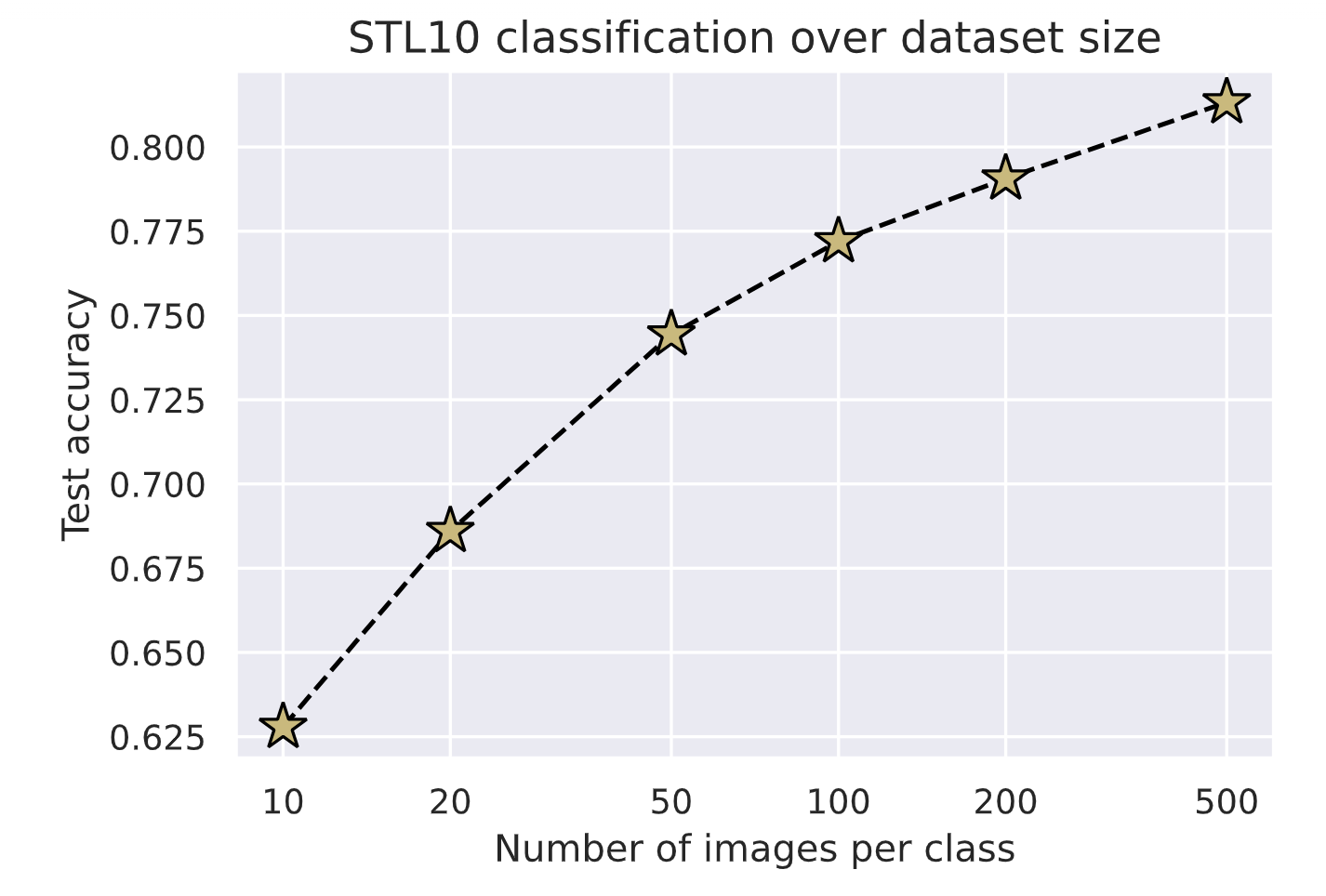
dataset_sizes = sorted([k for k in results])
test_scores = [results[k]["test"] for k in dataset_sizes]
fig = plt.figure(figsize=(6,4))
plt.plot(dataset_sizes, test_scores, '--', color="#000", marker="*", markeredgecolor="#000", markerfacecolor="y", markersize=16)
plt.xscale("log")
plt.xticks(dataset_sizes, labels=dataset_sizes)
plt.title("STL10 classification over dataset size", fontsize=14)
plt.xlabel("Number of images per class")
plt.ylabel("Test accuracy")
plt.minorticks_off()
plt.show()
for k, score in zip(dataset_sizes, test_scores):
print(f'Test accuracy for {k:3d} images per label: {100*score:4.2f}%')
Out:
正如我们所期望的,我们拥有的数据越多,分类性能就越好。然而,即使每个类别只有10张图像,我们也已经能够正确分类超过60%的图像。考虑到这些图像的维度比CIFAR10等数据集更高,这已经相当令人印象深刻了。使用完整的数据集,我们达到了81%的准确率。从50张图像到500张图像每个类别的准确率增长,可能暗示着性能会随着数据集呈指数级增长而线性提升。然而,如果有更多的数据,我们还可以在训练过程中对基础网络 f ( ⋅ ) f(\cdot) f(⋅)进行微调,使表示能够更好地适应特定的分类任务。
为了使上述结果更具参考价值,我们将从头开始在分类任务上训练基础网络,即ResNet-18。
1.2.3 Logistic 回归基线
为了与上述结果形成对比,我们将在STL10的标记训练集上训练一个标准的ResNet-18模型,该模型采用随机初始化。这些结果将为我们提供对比学习在未标记数据上的优势与仅使用监督训练相比的参考。由于ResNet架构在torchvision库中已经提供,因此模型的实现非常简单。
class ResNet(pl.LightningModule):
def __init__(self, num_classes, lr, weight_decay, max_epochs=100):
super().__init__()
self.save_hyperparameters()
self.model = torchvision.models.resnet18(num_classes=num_classes)
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(),
lr=self.hparams.lr,
weight_decay=self.hparams.weight_decay)
lr_scheduler = optim.lr_scheduler.MultiStepLR(optimizer,
milestones=[int(self.hparams.max_epochs*0.7),
int(self.hparams.max_epochs*0.9)],
gamma=0.1)
return [optimizer], [lr_scheduler]
def _calculate_loss(self, batch, mode='train'):
imgs, labels = batch
preds = self.model(imgs)
loss = F.cross_entropy(preds, labels)
acc = (preds.argmax(dim=-1) == labels).float().mean()
self.log(mode + '_loss', loss)
self.log(mode + '_acc', acc)
return loss
def training_step(self, batch, batch_idx):
return self._calculate_loss(batch, mode='train')
def validation_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='val')
def test_step(self, batch, batch_idx):
self._calculate_loss(batch, mode='test')
显而易见的是,ResNet很容易在训练数据上过拟合,因为其参数数量比数据集的大小要大出1000多倍。为了使与对比学习模型的比较更加公平,我们应用了与之前相似的数据增强方法:水平翻转、裁剪并调整大小、灰度化以及高斯模糊。之前使用的色彩失真在这里没有采用,因为图像的色彩分布对于分类来说是一个重要的特征。因此,我们在数据增强中加入色彩失真时,并没有观察到明显的性能提升。同样地,我们在裁剪前对图像大小的调整限制为最大125%的原始分辨率,而不是像SimCLR中那样调整到1250%。这是因为,对于分类任务,模型需要识别出完整的物体,而在对比学习中,我们只是想检查两个图像块是否属于同一图像/物体。因此,下面选择的数据增强方法总体上比对比学习的情况要弱一些。
train_transforms = transforms.Compose([transforms.RandomHorizontalFlip(),
transforms.RandomResizedCrop(size=96, scale=(0.8, 1.0)),
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=9, sigma=(0.1, 0.5)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_img_aug_data = STL10(root=DATASET_PATH, split='train', download=True,
transform=train_transforms)
ResNet的训练函数几乎与逻辑回归设置完全相同。请注意,我们允许ResNet每2个epoch进行一次验证,以检查模型在最初的几次迭代中是否严重过拟合。
def train_resnet(batch_size, max_epochs=100, **kwargs):
trainer = pl.Trainer(default_root_dir=os.path.join(CHECKPOINT_PATH, "ResNet"),
accelerator="gpu" if str(device).startswith("cuda") else "cpu",
devices=1,
max_epochs=max_epochs,
callbacks=[ModelCheckpoint(save_weights_only=True, mode="max", monitor="val_acc"),
LearningRateMonitor("epoch")],
check_val_every_n_epoch=2)
trainer.logger._default_hp_metric = None
# Data loaders
train_loader = data.DataLoader(train_img_aug_data, batch_size=batch_size, shuffle=True,
drop_last=True, pin_memory=True, num_workers=NUM_WORKERS)
test_loader = data.DataLoader(test_img_data, batch_size=batch_size, shuffle=False,
drop_last=False, pin_memory=True, num_workers=NUM_WORKERS)
pretrained_filename = os.path.join(CHECKPOINT_PATH, "ResNet.ckpt")
if os.path.isfile(pretrained_filename):
print("Found pretrained model at %s, loading..." % pretrained_filename)
model = ResNet.load_from_checkpoint(pretrained_filename)
else:
pl.seed_everything(42)
model = ResNet(**kwargs)
trainer.fit(model, train_loader, test_loader)
model = ResNet.load_from_checkpoint(trainer.checkpoint_callback.best_model_path)
train_result = trainer.test(model, train_loader, verbose=False)
val_result = trainer.test(model, test_loader, verbose=False)
result = {"train": train_result[0]["test_acc"], "test": val_result[0]["test_acc"]}
return model, result
最后,让我们训练模型并检查其结果:
resnet_model, resnet_result = train_resnet(batch_size=512,
num_classes=10,
lr=1e-3,
weight_decay=2e-4,
max_epochs=100)
print(f"Accuracy on training set: {100*resnet_result['train']:4.2f}%")
print(f"Accuracy on test set: {100*resnet_result['test']:4.2f}%")
out:
Accuracy on training set: 99.83%
Accuracy on test set: 73.31%
从头开始训练的ResNet在测试集上达到了73.31%的准确率。这比对比学习模型少了近8%,甚至比SimCLR在只有十分之一数据的情况下所达到的准确率还要稍低一些。这表明,当只有少量标记数据可用时,通过利用大量未标记数据,自监督的对比学习能够显著提升性能。
- PyTorch基础与异或问题实践
- 激活函数与神经网络优化
- 数据预处理与模型优化:FashionMNIST实验
- 经典CNN架构与PyTorch Lightning实践
- Transformers与多头注意力机制实战
- 深度能量模型与PyTorch实践
- 图神经网络
- 自编码器与神经网络应用
- 深度归一化流图像建模与实践
- 自回归图像建模与像素CNN实现
- Vision Transformers with PyTorch Lightning on昇腾
- ProtoNet与ProtoMAML元学习算法实践
- SimCLR与Logistic回归在自我监督学习中的应用



















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









