



运行图生视频/文生视频(如Wan2.2)的显卡配置总结
Wan2.2 是一个基于深度学习的视频生成项目,支持 图生视频(Image-to-Video) 和 文生视频(Text-to-Video) 任务,类似于 Stable Video Diffusion 或 RunwayML 的视频生成模型。这类任务对 GPU 的 显存、算力、架构 要求较高,以下是推荐的显卡配置总结:
1. 最低配置(勉强可跑,低分辨率/低帧率)
| 显卡型号 | 显存 | 算力(FP16) | 适用场景 |
|---|---|---|---|
| NVIDIA RTX 3060 | 12GB | ~13 TFLOPS | 720p 视频生成,低 batch size |
| NVIDIA RTX 4060 Ti | 16GB | ~22 TFLOPS | 1080p 低帧率生成 |
| NVIDIA A2000 | 12GB | ~8 TFLOPS | 仅测试,不推荐 |
限制:
- 只能跑 低分辨率(如 512x512),batch size=1。
- 生成速度较慢(可能 1-2 分钟/帧)。
- 可能需要 模型量化(如 FP16/INT8) 才能运行。
2. 推荐配置(流畅运行 1080p 视频)
| 显卡型号 | 显存 | 算力(FP16) | 适用场景 |
|---|---|---|---|
| NVIDIA RTX 3090 | 24GB | ~36 TFLOPS | 1080p 视频生成,batch size=2 |
| NVIDIA RTX 4090 | 24GB | ~82 TFLOPS | 4K 低帧率生成 |
| NVIDIA A6000 | 48GB | ~38 TFLOPS | 适合长视频生成 |
| NVIDIA A100 40GB | 40GB | ~78 TFLOPS | 专业级训练/推理 |
优势:
- 可运行 1080p 视频生成,batch size≥2。
- 支持 更高帧率(24FPS+)。
- 适合 微调模型 或 长视频生成。
3. 高端/服务器级配置(4K/高帧率/批量生成)
| 显卡型号 | 显存 | 算力(FP16) | 适用场景 |
|---|---|---|---|
| NVIDIA H100 80GB | 80GB | ~197 TFLOPS | 4K 60FPS 视频生成 |
| NVIDIA A100 80GB | 80GB | ~124 TFLOPS | 多任务并行推理 |
| 2x/4x RTX 4090(NVLink) | 48GB(聚合) | ~164 TFLOPS | 高性能生成 |
适用场景:
- 4K 超清视频生成。
- 批量生成(如广告/影视特效)。
- 多任务并行(如同时跑文生视频+图生视频)。
4. 其他替代方案
(1) 华为昇腾(Ascend)
- Ascend 910B(算力 ~256 TFLOPS FP16)可运行 Wan2.2,但 依赖 MindSpore 框架,生态适配较差。
- 需要 华为 CANN 工具链 转换模型(如 ONNX → OM)。
(2) AMD ROCm(如 MI250X)
- 理论上支持 PyTorch,但 Wan2.2 可能未优化 AMD 架构,性能不如 NVIDIA。
- 仅推荐 实验性尝试。
(3) 云服务(低成本方案)
- AWS(p4d.24xlarge - A100 x8)
- Google Cloud(A100/A2)
- 华为云(Ascend 910)
5. 关键影响因素
-
显存(VRAM):
- 12GB → 勉强跑 720p。
- 24GB+ → 流畅 1080p。
- 40GB+ → 4K/长视频。
-
算力(TFLOPS FP16):
- < 20 TFLOPS → 生成速度慢。
- > 50 TFLOPS → 适合实时/高帧率。
-
架构优化:
- NVIDIA Ampere/Ada Lovelace(RTX 30/40 系)比 Pascal(GTX 10 系)快 3-5 倍。
- CUDA + Tensor Core 对 PyTorch 优化更好。
6. 总结推荐
| 需求 | 推荐显卡 | 预估性能 |
|---|---|---|
| 入门体验 | RTX 3060 12GB | 720p,低帧率 |
| 1080p 流畅 | RTX 3090/4090 | 1080p 24FPS |
| 4K/专业级 | A100/H100 | 4K 60FPS |
| 国产替代 | Ascend 910B | 需适配 MindSpore |
建议:
- 如果预算有限,可尝试 云服务(如 AWS A100)。
- RTX 4090 是目前性价比最高的消费级选择(24GB 显存 + 高算力)。
- 企业级推荐 A100/H100,适合稳定生产环境。
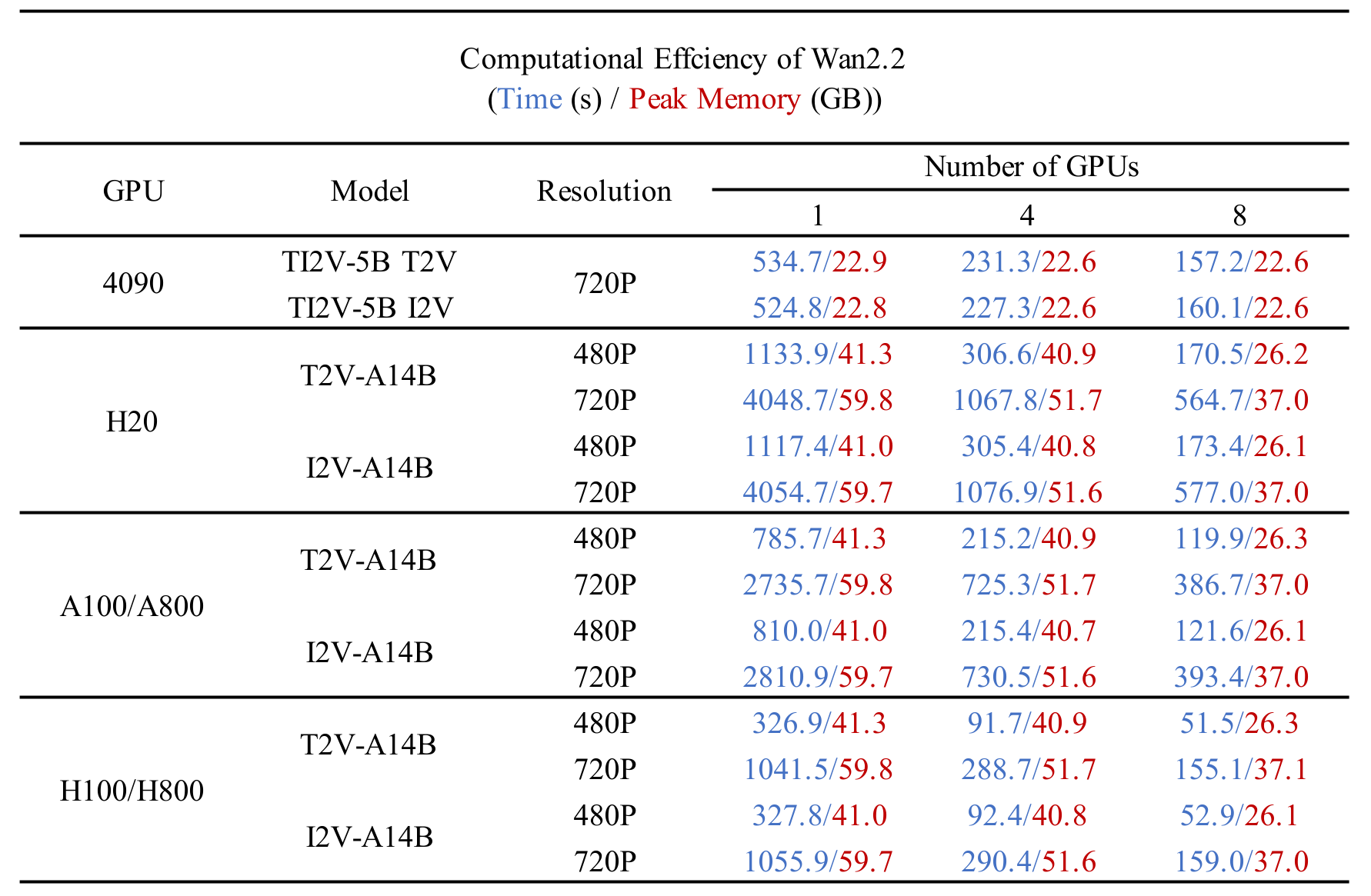
如果有具体需求(如分辨率、帧率、batch size),可以进一步优化配置!

















 3865
3865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









