




【USparkle专栏】如果你深怀绝技,爱“搞点研究”,乐于分享也博采众长,我们期待你的加入,让智慧的火花碰撞交织,让知识的传递生生不息!
背景:前段时间在项目内做了关于Mono内存(堆内存)的优化。从结果上将Mono内存从220MB降低到130MB,优化过程中唤起了部分关于GC的消失的回忆,虽然实际的优化工作中也许并用不到,但是更明确底层实现机制总归是一件迭代自我的过程,在这里就来回顾一下。
一、什么是垃圾回收 - GC(Garbage Collector)
在游戏运行的时候,数据主要存储在内存中,当游戏的数据在不需要的时候,存储当前数据的内存就可以被回收以再次使用。内存垃圾是指当前废弃数据所占用的内存,垃圾回收(GC)是指将废弃的内存重新回收再次使用的过程。
1. 什么时候触发垃圾回收
有三个操作会触发垃圾回收:
- 在堆内存上进行内存分配操作而内存不够的时候都会触发垃圾回收来利用闲置的内存。
- GC会自动触发,不同平台运行频率不一样。
- GC被代码强制执行。
2. GC操作带来的问题
直白点就两个问题:一个是Stop-the-world导致的“卡”;一个是内存碎片导致的“堆内存太大”。
-
GC操作会需要大量的时间来运行,如果堆内存上有大量的变量或者引用需要检查,则检查的操作会十分缓慢,这就会使得游戏运行缓慢。
-
GC可能会在关键时候运行,例如在CPU处于游戏的性能运行关键时刻,此时任何一个额外的操作都可能会带来极大的影响,使得游戏帧率下降。
-
另外一个GC带来的问题是堆内存的碎片。当一个内存单元从堆内存上分配出来,其大小取决于其存储的变量的大小。当该内存被回收到堆内存上的时候,有可能使得堆内存被分割成碎片化的单元。也就是说堆内存总体可以使用的内存单元较大,但是单独的内存单元较小,在下次内存分配的时候不能找到合适大小的存储单元,这也会触发GC操作或者堆内存扩展操作。
-
堆内存碎片会造成两个结果:一个是游戏占用的内存会越来越大;一个是GC会更加频繁地被触发。
特别是在堆内存上进行内存分配时内存单元不足够的时候,GC会被频繁触发,这就意味着频繁在堆内存上进行内存分配和回收会触发频繁的GC操作。
二、Unity托管堆
在讲具体的Unity GC机制之前再回顾一下Unity托管堆。
1. 托管堆的工作原理及其扩展原因
“托管堆”是由项目脚本运行时(Mono或IL2CPP)的内存管理器自动管理的一段内存。必须在托管堆上分配托管代码中创建的所有对象。

在上图中,白框表示分配给托管堆的内存量,而其中的彩色框表示存储在托管堆的内存空间中的数据值。当需要更多值时,将从托管堆中分配更多空间。
GC定期运行将扫描堆上的所有对象,将任何不再引用的对象标记为删除。然后会删除未引用的对象,从而释放内存。
至关重要的是,Unity的垃圾收集是非分代的,也是非压缩的。“非分代”意味着GC在执行每遍收集时必须扫描整个堆,因此随着堆的扩展,其性能会下降。“非压缩”意味着不会为内存中的对象重新分配内存地址来消除对象之间的间隙。

上图为内存碎片化示例。释放对象时,将释放其内存。但是,释放的空间不会整合成为整个“可用内存”池的一部分。位于释放的对象两侧的对象可能仍在使用中。因此,释放的空间成为其他内存段之间的“间隙”(该间隙由上图中的红色圆圈指示)。因此,新释放的空间仅可用于存储与释放相同大小或更小的对象的数据。
这导致了内存碎片化这个核心问题:虽然堆中的可用空间总量可能很大,但是可能其中的部分或全部的可分配空间对象之间存在小的“间隙”。这种情况下,即使可用空间总量高于要分配的空间量,托管堆可能也找不到足够大的连续内存块来满足该分配需求。

如果分配了大型对象又没有足够的连续空间提供使用则:
- 运行垃圾回收器,尝试释放空间来满足分配请求。
- 如果在GC运行后,仍然没有足够的连续空间来满足请求的内存量,则必须扩展堆。堆的具体扩展量视平台而定。
2. Unity托管堆的问题
- Unity在扩展托管堆后不会经常释放分配给托管堆的内存页, 防止再次发生大量分配时需要重新扩展堆。
- 在大多数平台上,Unity最终会将托管堆的空置部分使用的页面释放回操作系统。发生此行为的间隔时间是不确定的,不要指望靠这种方法释放内存。
频繁分配临时数据给托管堆,这种情况通常对项目的性能极为不利。
如果每帧分配1KB的临时内存,并且以60帧的速率运行,那么它必须每秒分配60KB的临时内存。在一分钟内,这会在内存中增加3.6MB的垃圾。对内存不足的设备而言每分钟3.6MB的垃圾也无法接受。
三、Unity的GC机制 -- Boehm GC
以前看过Unity使用的GC方案但最近才惊觉现在使用的Unity都是IL2CPP的版本了,所谓的Mono GC本来就已经不存在了。于是来看下现在的IL2CPP的GC机制: Boehm GC(贝姆垃圾收集器)。
1. IL2CPP - Boehm GC
贝姆垃圾收集器是计算机应用在C/C++语言上的一个保守的垃圾回收器(Garbage Collector),可应用于许多经由C/C++开发的程序中。
摘录一段定义:
Boehm-Demers-Weiser garbage collector,适用于其它执行环境的各类编程语言,包括了GNU版Java编译器执行环境,以及Mono的Microsoft .NET移植平台。同时支援许多的作业平台,如各种Unix操作系统,微软的操作系统(Microsoft Windows),以及麦金塔上的操作系统(Mac OS X),还有更进一步的功能,例如:渐进式收集(Incremental Collection),平行收集(Parallel Collection)以及终结语意的变化(Variety Offinalizersemantics)。
在Unity中我们可以看到关于Boehm GC的算法部分:

BoehmGC.cpp内部调用的就是这个第三方库,他是Stop-the-world类型的垃圾收集器,这表明了在执行垃圾回收的时候,将会停止正在运行的程序,而停止时间的只有在完成工作后才会恢复,所以这就导致了GC引起的程序卡顿峰值,很显然这对游戏的平滑体验造成了较大的负面影响。
通常,解决这个问题的常规方案是尽可能地“减少”运行时垃圾回收(后续用GC代替),亦或者将GC放在不那么操作敏感的场景中,比如回城、死亡后等。但完全避免运行时垃圾回收在大部分时间是不现实的。
接下来我们来看看Boehm GC的背后机制。
2. Boehm GC算法思路
Boehm GC是一种Mark-Sweep(标记-清扫)算法,大致思路包含了四个阶段:
- 准备阶段:每个托管堆内存对象在创建出来的时候会有一个关联的标记位,来表示当前对象是否被引用,默认为0。
- 标记阶段:从根内存节点(静态变量;栈;寄存器)出发,遍历扫描托管堆的内存节点,将被引用的内存节点标记为1。
- 清扫阶段:遍历所有节点,将没有被标记的节点的内存数据清空,并且基于一定条件释放。
- 结束阶段:触发注册过的回调逻辑。
3. 渐进式GC
使用渐进式GC允许把GC工作分成多个片,因此为了不让GC工作长时间的“阻塞”主线程,将其拆分成了多个更短的中断。需要明确的是这并不会使GC总体上变得更快,但是却可以将工作负载分配到多帧来平缓单次GC峰值带来的卡顿影响。
注: Unity在高版本已经默认是渐进式GC了,大概是Unity 19.1a10版本。
[Unity 活动]-浅谈Unity内存管理_哔哩哔哩_bilibili
4. GC中的内存分配
Boehm GC的使用方法非常简单,只需要将malloc替换为GC_malloc即可,在此之后便无需关心free的问题。
void * GC_malloc(size_t lb)
{
return GC_malloc_kind(lb, NORMAL);
}
void * GC_malloc_kind(size_t lb, int k)
{
return GC_malloc_kind_global(lb, k);
}在整个内存分配链的最底部,Boehm GC通过平台相关接口来向操作系统申请内存。为了提高申请的效率,每次批量申请4KB的倍数大小。
分配器的核心是一个分级的结构,Boehm GC把每次申请根据内存大小归类成小内存对象和大内存对象。
- 小内存对象:不超过PageSize/2,小于2048字节的对象。
- 大内存对象:大于PageSize/2的对象。
对于大内存对象,向上取整到4KB的倍数大小,以整数的内存块形式给出。而小内存对象则会先申请一个内存块出来,而后在这块内存上进一步细分为Small Objects,形成free-list。
下面会分别说下大内存对象和小内存对象,参考网上的资料整理,确实有点点干,但是配图我重新做了一下,大概可以辅助消化。
四、IL2CPP - Boehm GC:小内存分配
1. 粒度对齐
实现思路是,提出粒度(GRANULES)的概念,即一个GRANULE的大小是16字节。实际分配内存的时候按照GRANULE为基本单位来分配。分配过程中,按照原始需要的大小,计算并映射得到实际需要分配的GRANULE个数,代码如下:
//lb是原始的分配大小,lg是GRANULE(1~128)。
size_t lg = GC_size_map[lb];例如需要18字节的内存,则lg=2,即实际分配2个GRANULE(32字节),如果需要1字节的内存,则lg=1,即实际分配1个GRANULE(16字节)。
GC_size_map是一个“GRANULE索引映射表”,用来维护原始分配的内存大小和内存索引之间的关系。最多可以返回128个GRANULE,所以小内存的大小上限是128*16=2048。GC_size_map数组本身会不断加载根据需要不断扩容。

2. 空闲链表 - ok_freelist
决定了GRANULE的大小之后,在申请内存时刻首先会从“空闲链表”中查看是否有空闲内存块,如果有则直接返回这块内存,完成分配,其算法维护了一个数据结构obj_kind:
struct obj_kind {
void **ok_freelist;
struct hblk **ok_reclaim_list;
...
} GC_obj_kinds[3];GC_obj_kinds[3]对应了3种内存类型,分别是PTRFREE、NORMAL和UNCOLLECTABLE,每种类型都有一个obj_kind结构体信息。
PTRFREE:无指针内存分配,明确的告诉GC,该对象内无任何的指针信息,在GC时候无需查找该对象是否引用了其他对象。
NORMAL:无类型的内存分配,因为无法得到对象的类型元数据,所以在GC时会按照只针对其的方式扫描内存块,如果通过了指针校验,就会认为该对象引用了该指针地址指向的对象。
UNCOLLECTABLE:为BOEHM自己分配的内存,这些不需要标记和回收。
每一个obj_kind的结构体都维护了一个ok_freelist的二维指针链表用来存放空闲的内存块。ok_freelist维护了0~127个链表索引。而每一个尺寸的freelist就是对应大小的GRANULE池子,其结构示意如图:
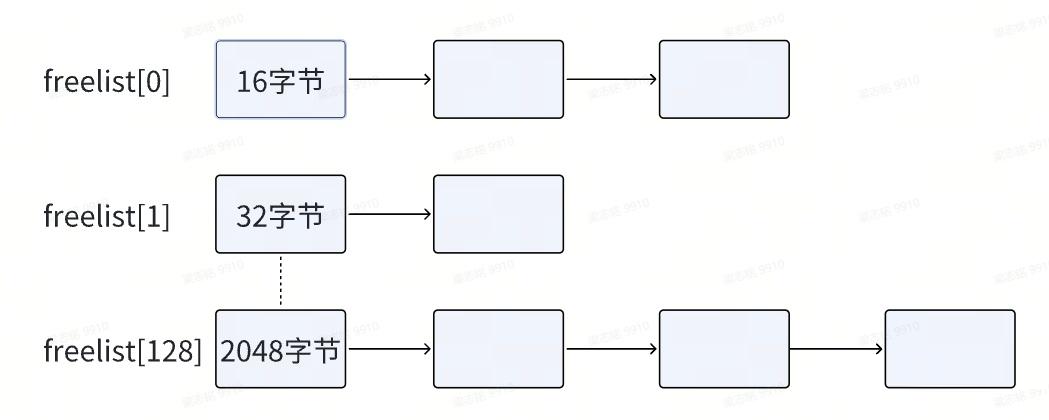
于是,根据要申请的内存大小计算得到GRANULE在freelist的索引,然后去查询对应索引的freelist,如果存在空闲看空间ok_freelist[index][ 0],则将其返回并从链上移除。

ok_freelist链表最初为空,如果ok_freelist中没有相应的空闲内存块,则调用GC_allocobj(lg, k)去底层查找可用的内存。
GC_allocobj的核心逻辑是调用GC_new_hblk(gran, kind)去底层内存池获取内存,并且查看底层内存池中是否分配了空闲的内存块,如果没有则通过系统函数例如malloc分配内存给底层内存池,如果内存池有,直接取出一块返回。GC_new_hblk的代码逻辑如下:
GC_INNER void GC_new_hblk(size_t gran, int kind)
{
struct hblk *h; /* the new heap block */
GC_bool clear = GC_obj_kinds[kind].ok_init;
/* Allocate a new heap block */
h = GC_allochblk(GRANULES_TO_BYTES(gran), kind, 0);
if (h == 0) return;
/* Build the free list */
GC_obj_kinds[kind].ok_freelist[gran] =
GC_build_fl(h, GRANULES_TO_WORDS(gran), clear,(ptr_t)GC_obj_kinds[kind].ok_freelist[gran]);
}GC_new_hblk的主要逻辑有2步:
- 调用GC_allochblk方法进一步获取内存池中可用的内存块;
- 调用GC_build_fl方法,利用内存池中返回的内存块构建ok_freelist,供上层使用。
3. 核心内存块链表GC_hblkfreelist
底层内存池的实现逻辑和ok_freelist类似,维护了一个空闲内存块链表的指针链表GC_hblkfreeelist,但是和ok_freelist不同的是,这个链表中的内存块的基本单位是4KB,也就是一个内存页(page_size)的大小。GC_hblkfreelist一个有60个元素,每一个元素都是一个链表。
4. 内存块 - hblk、头信息 - hblkhdr
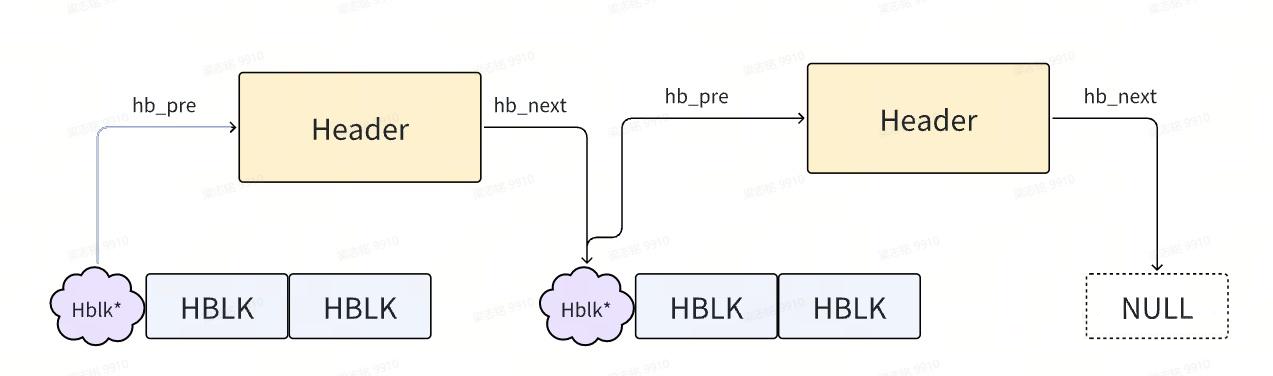
链表中的每一个内存块都以大小4096(4KB)为一基本单位,一个大小为4096的内存块被称为hblk,数据定义如下:
struct hblk {
char hb_body[HBLKSIZE]; //HBLKSIZE=4096
};每个hblk拥有一个相应的header信息,用来描述这个内存快的情况,数据的定义如下:
//头部信息
struct hblkhdr {
struct hblk * hb_next; //指向下一个hblk
struct hblk * hb_prev; //指向上一个hblk
struct hblk * hb_block; //对应的hblk
unsigned char hb_obj_kind; //kink类型
unsigned char hb_flags; //标记位
word hb_sz; //如果给上层使用,则表示实际分配的单位,如果空闲,则表示内存块的大小
word hb_descr;
size_t hb_n_marks;//标记位个数,用于GC
word hb_marks[MARK_BITS_SZ]; //标记为,用于GC
}
5. hblk内存块查询
structh blk *GC_allochblk(size_t sz, int kind, unsigned flags/* IGNORE_OFF_PAGE or 0 */)
{
...
//1.计算需要的内存块大小
blocks_needed = OBJ_SZ_TO_BLOCKS_CHECKED(sz);
start_list = GC_hblk_fl_from_blocks(blocks_needed);
//2.查找精确的hblk内存块
result = GC_allochblk_nth(sz, kind, flags, start_list, FALSE);
if (0 != result) return result;
may_split = TRUE;
...
if (start_list < UNIQUE_THRESHOLD) {
++start_list;
}
//3.从更大的内存块链表中找
for (; start_list <= split_limit; ++start_list) {
result = GC_allochblk_nth(sz, kind, flags, start_list, may_split);
if (0 != result) break;
}
return result;
}
STATIC int GC_hblk_fl_from_blocks(word blocks_needed)
{
if (blocks_needed <= 32) return blocks_needed;
if (blocks_needed >= 256) return (256-32)/8+32;
return (blocks_needed-32)/8+32;
}先根据上层需要分配的内存大小计算出需要的内存块大小,如果申请的大小小于4096字节,则结果是1,对于小对象内存块的个数就是1。
根据实际需要的内存块数,判断并决定从哪一个GC_hblkfreelist链表查找,start_list是开始查找的链表index,即从GC_hblkfreelist[start_list]开始查找。并不是需要blocks,就一定会从GC_hblkfreelist[blocks]的链表中查找,遵循转换规则(小内存索引是连续的,中内存索引是32+8的步长,大点的内存索引都是60)。
- 如果blocks_needed小于32,则startlist=blocks_needed,直接去GC_hblkfreelist[blocks_needed]中查找。
- 如果blocks_needed位于32~256,则startlist=(blocks_needed-32)/8+32,即blocks_needed每增加8个,对应GC_hblkfreelist[index]的index增加1。
- 如果blocks_needed大于256,则都从GC_hblkfreelist[60]链表中查找。
决定从哪个链表开始查找之后,首先进行精确查找,如果直接找到,则直接返回找到的内存块。
如果精准查找失败,则逐渐增大start_list,从更大的内存块链表中查找。
STATIC struct hblk *GC_allochblk_nth(size_t sz, int kind, unsigned flags, int n, int may_split)
{
struct hblk *hbp;
hdr * hhdr;
struct hblk *thishbp;
hdr * thishdr;/* Header corr. to thishbp */
//计算需要分配的内存块大小
signed_word size_needed = HBLKSIZE * OBJ_SZ_TO_BLOCKS_CHECKED(sz);
//从链表中查找合适的内存块
for (hbp = GC_hblkfreelist[n];; hbp = hhdr -> hb_next) {
signed_word size_avail;
if (NULL == hbp) return NULL;
//获取内存块的header信息
GET_HDR(hbp, hhdr);
//内存块大小
size_avail = (signed_word)hhdr->hb_sz;
if (size_avail < size_needed) continue;
//可用内存大于需要的分配的大小
if (size_avail != size_needed) {
//要求精准不分割,退出循环,返回空
if (!may_split) continue;
...
if( size_avail >= size_needed ) {
...
//分割内存块,修改链表
hbp = GC_get_first_part(hbp, hhdr, size_needed, n);
break;
}
}
}
if (0 == hbp) return0;
...
//修改header信息
setup_header(hhdr, hbp, sz, kind, flags)
...
return hbp;
}当分配字节的时候先通过精确查找如果发现有精确内存,则会返回相应的内存块,如果没有发现精确内存则会去查找更大的内存块并进行分割,一半返回使用,一半放到池子里。
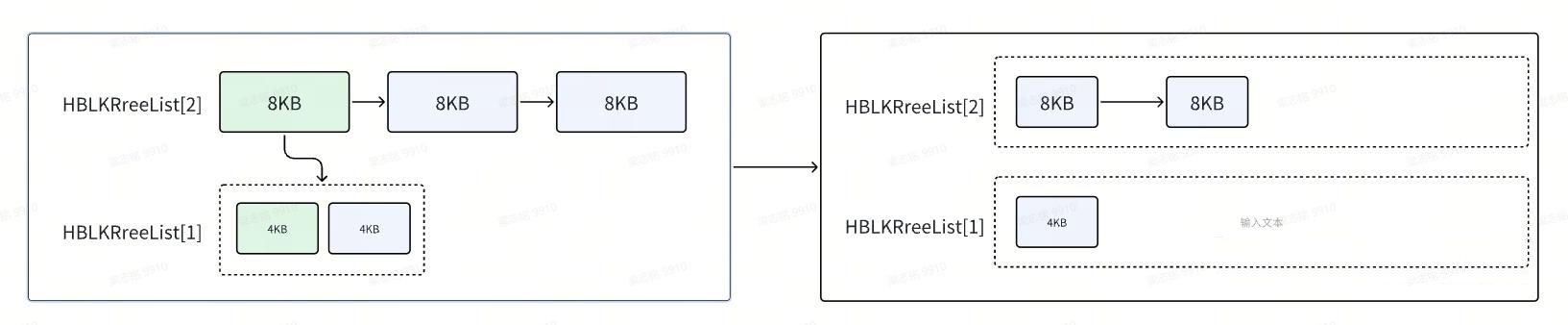
如上图示例,如果要申请1KB,则会先找4KB,如果没有4KB则去找8KB,找到了8KB就进行两个4KB的拆分,然后移除8KB出池子,再把拆分过的另一半4KB内存块加入到池子里:
STATIC struct hblk *GC_get_first_part(struct hblk *h, hdr *hhdr, size_t bytes, int index) {
word total_size = hhdr -> hb_sz;
struct hblk * rest;
hdr * rest_hdr;
//从空闲链表删除
GC_remove_from_fl_at(hhdr, index);
if (total_size == bytes) return h;
//后半部分
rest = (struct hblk *)((word)h + bytes);
//生成header信息
rest_hdr = GC_install_header(rest);
//内存块大小
rest_hdr -> hb_sz = total_size - bytes;
rest_hdr -> hb_flags = 0;
...
//加入相应的空闲链表
GC_add_to_fl(rest, rest_hdr);
}6. 内存块分配
如果GC_hblkfreelist空闲链表中找不到合适的内存块,则考虑从系统开辟一段新的内存,并添加到GC_hblkfreelist链表中。在GC_expand_hp_inner方法中实现:
GC_INNER GC_bool GC_expand_hp_inner(word n)
{
...
//调用系统方式开辟内存
space = GET_MEM(bytes);
//记录内存地址和大小
GC_add_to_our_memory((ptr_t)space, bytes);
...
//添加到GC_hblkfreelist链表中
GC_add_to_heap(space, bytes);
...
}GC_add_to_heap方法将创建出来的内存块加入相应的GC_hblkfreelist链表中。同时加入一个全局的存放堆内存信息的数组中。
其中如果发现内存连续的前后内存块存在且空闲,则合并前后的内存块,生成一个更大的内存块。
7. ok_freeList
在GC_new_hblk中调用GC_build_fl方法构建链表,就是这个GC系统的缓存池核心数据结构。
//构建ok_freelist[gran]
GC_obj_kinds[kind].ok_freelist[gran] = GC_build_fl(h, GRANULES_TO_WORDS(gran), clear,(ptr_t)GC_obj_kinds[kind].ok_freelist[gran]);
GC_INNER ptr_t GC_build_fl(struct hblk *h, size_t sz, GC_bool clear,
ptr_t list) {
word *p, *prev;
word *last_object;/* points to last object in new hblk*/
...
//构建链表
p = (word *)(h -> hb_body) + sz;/* second object in *h*/
prev = (word *)(h -> hb_body);/* One object behind p*/
last_object = (word *)((char *)h + HBLKSIZE);
last_object -= sz;
while ((word)p <= (word)last_object) {
/* current object's link points to last object */
obj_link(p) = (ptr_t)prev;
prev = p;
p += sz;
}
p -= sz;
//拼接之前的链表
*(ptr_t *)h = list;
//返回入口地址
return ((ptr_t)p);
}以4096字节的内存块划分为16字节单元的freeList为例,步骤如下:
- 4096字节按照16字节分配,划分为256个小内存块,编号是0~255,将最后一个内存块(255)作为新链表的首节点。
- 内存地址向前遍历,建立链表,即255的下一个节点是254,尾节点是0。
- 将尾节点的下一个节点指向原链表的首地址。
- 将新链表的首节点地址作为ok_freelist[N],N是上文提到的GRANULE,例如16字节对应1。
重建好的freeList,并将首节点提供给上层使用。
五、Boehm GC:大内存分配
分配大内存对象是指分配的内存大于2048字节。
OBJ_SZ_TO_BLOCKS用于计算需要的hblk内存块的个数,对于大内存,需要的个数大于等于1。例如需要分配9000字节的内存,则需要3个hblk内存块,然后调用GC_alloc_large分配内存。
GC_INNER ptr_t GC_alloc_large(size_t lb, int k, unsigned flags)
{
struct hblk * h;
word n_blocks;
ptr_t result;
...
n_blocks = OBJ_SZ_TO_BLOCKS_CHECKED(lb);
...
//分配内存
h = GC_allochblk(lb, k, flags);
...
//分配失败,系统分配内存块后继续尝试分配
while (0 == h && GC_collect_or_expand(n_blocks, flags != 0, retry)) {
h = GC_allochblk(lb, k, flags);
retry = TRUE;
}
//记录大内存创建大小
size_t total_bytes = n_blocks * HBLKSIZE;
...
GC_large_allocd_bytes += total_bytes;
...
result = h -> hb_body;
//返回内存地址
return result;
}大内存分配的内存查找和小对象方式一样,会不断增加start_list。从更大的链表中查找是否有空闲内存,不同的是,如果查找到了空闲内存不会分裂构建ok_freeList链表而是直接返回大内存块的地址提供使用。
六、Boehm GC:内存分配流程图
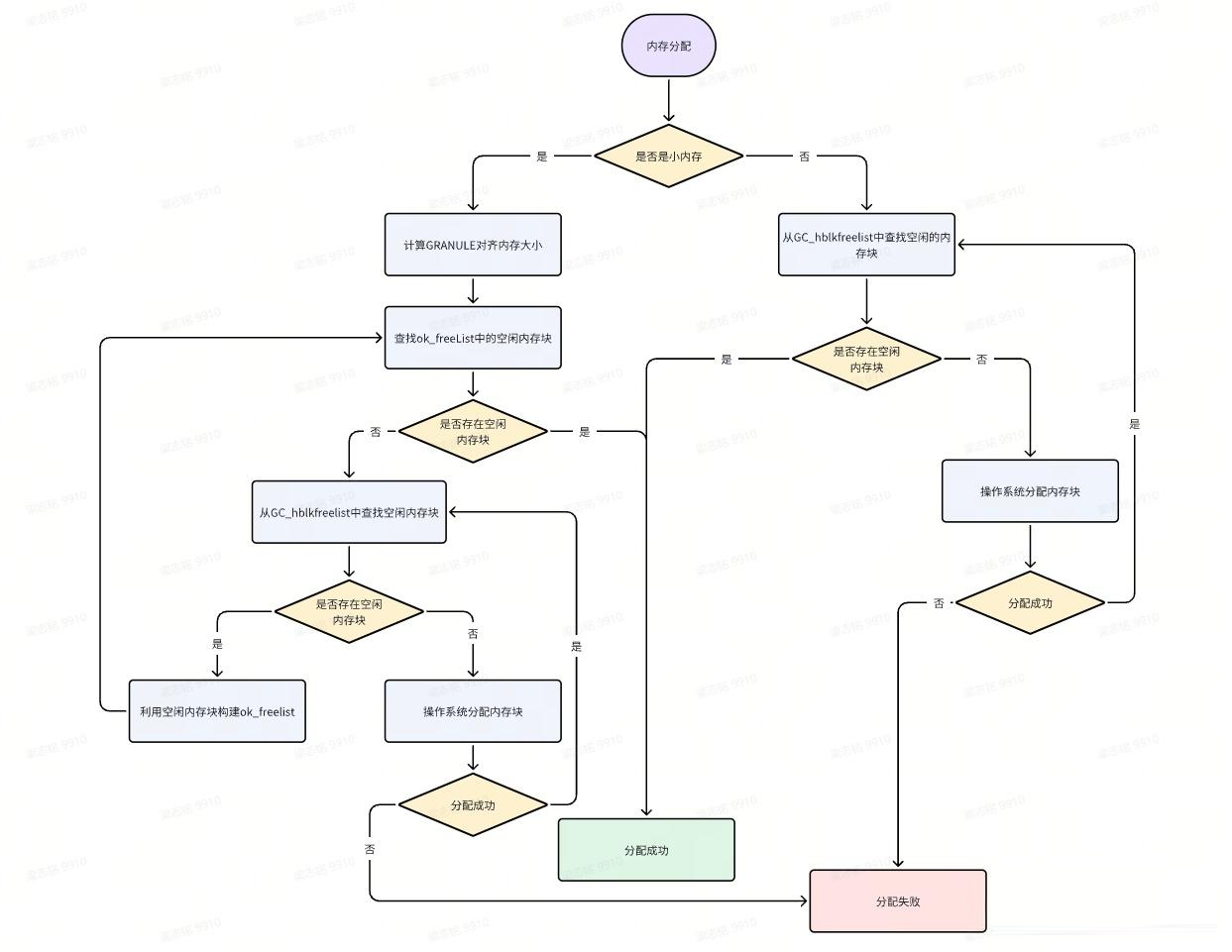
七、额外:SGen GC
Simple Generational Garbage Collection简称SGen GC,是相比Boehm GC(贝姆GC)更为先进的一种GC方式。官方Mono在2.8版本中增加了SGen GC,但默认的仍是Boehm GC。3.2版本之后,Mono正式将SGen GC作为默认GC方式。
SGen GC将堆内存分为初生代(Nursery)和旧生代(Old Generation)两代进行管理,并包含两个GC过程:Minor GC对初生代进行清理;Major GC对初生代和旧生代同时进行清理。
1. 内存分配策略 - 初代
在SGen GC中,初生代是一块固定大小的连续内存,默认为4MB,可以通过配置修改。这一点与G1不同,在G1中同一代的Region在物理上是不要求连续的。
为了支持多线程工作,新对象的内存分配依然在每个线程的TLAB中进行,当前每个TLAB均为4KB,有提到可能会在不久后进行优化。而在TLAB内部,内存分配是通过指针碰撞的方式进行的,也就是说,在SGen GC中,初生代内存并没有进行粒度划分也没有分块管理。
初生代对象跟随Minor GC和Major GC进行回收。
2. 内存分配策略 - 旧代
在SGen GC中,旧生代内存划分方式可以概括为:
Section(1MB) → Block(16KB)→ Page(4KB)→ Slot(不同粒度)
在使用内存时,按照上述链条依次向下拆分,与贝姆GC相同,同一个Block中的Page也只能拆分成相同粒度的Slot。
虽然在初生代中并没有划分内存粒度,但是当对象从初生代转移到旧生代时会找到对应粒度的Slot进行存储。释放对象时,对应的Slot也会返还给空闲链表(类似贝姆GC中的ok_freeList),并在某一级结构完全清空时依次向上一级返还。
旧生代内存最终是通过一个GCMemSection结构的链表进行管理的。
3. 内存分配策略 - 大对象
超过8KB的对象均被视为大对象,大对象通过单独的LOSSection结构进行管理。而大对象的内存管理又分为两种情况:
- 不超过1MB的,仍然存储在Mono自己的托管堆上,清理后返还给托管堆;
- 超过1MB的,直接从操作系统申请内存,清理后内存也同样返还给操作系统。
4. 内存分配策略 - 固定内存对象
有一些对象被显式或隐式地标记为了固定内存的对象,这些对象在初始时依然被分配在初生代中,但不会被GC过程移动位置。
- 显式:用户显式声明的,比如通过fixed关键字进行修饰;
- 隐式:在GC开始时,所有寄存器和ROOT中直接指向的对象都视为固定内存对象。
这是侑虎科技第1924篇文章,感谢作者Jamin供稿。欢迎转发分享,未经作者授权请勿转载。如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。
作者主页:https://www.zhihu.com/people/liang-zhi-ming-70
再次感谢Jamin的分享,如果您有任何独到的见解或者发现也欢迎联系我们,一起探讨。

















 1121
1121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









