



当我们在搭建AI知识库时,往往会遇到这些软件对于PDF文档或者文档中含有复杂表格&手写内容识别不准的情况。最后导致大模型出现幻觉,知识库答非所问,如果是企业知识库,错误的结果会影响员工判断,耽误企业的正常运营。在这其中,数据清洗/文档处理是目前搭建RAG系统时最头疼的环节。
根据IDC调研显示,80%的企业将知识存储在非结构化文档(PDF/Word/扫描件等),传统OCR工具仅提取文本,但丢失表格、公式、排版结构等关键信息,这对于企业知识库的正常使用来讲是个“致命”的痛点。
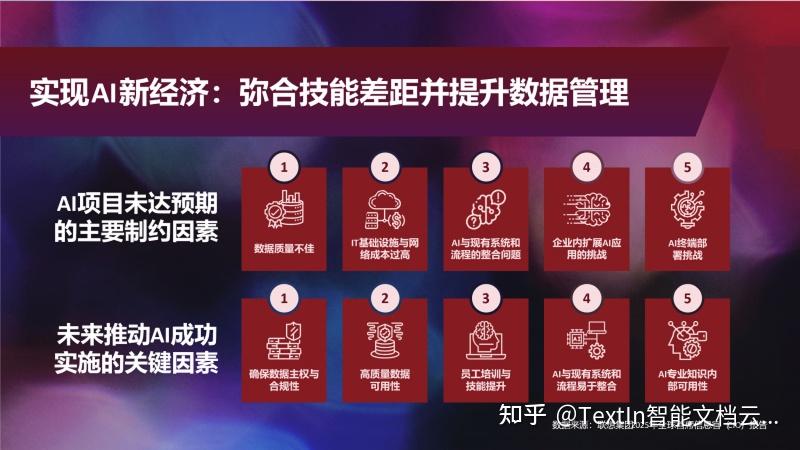
根据联想发布的调研来看,目前制约企业运用好AI的主要因素是数据质量不佳。若直接将文档丢给LLM阅读,大模型经常会出现识别错误和大模型幻觉的情况。传统的OCR又只能将文字信息独立的提取出来,面对复杂文档也无计可施。以企业知识库为例,一旦数据质量不佳,LLM无法识别和理解文档内容,企业知识库将”形同虚设“。
因此在搭建RAG知识库时,一定不能忘记添加TextIn文档解析进入RAG工作流。
相对于市面上的开源的文档处理产品,TextIn文档解析展现出两个独特的优势:
1.数据安全
企业知识库中所涉及的文档往往包含了许多公司机密,如生产工艺、成本、发票、合同和内部决策规则等,这些数据资产是企业的宝贵财产,无论如何都不愿意让这些知识外泄。而TextIn提供多种接入方式如API调用或私有化部署及离线包模式,为企业数据机密保驾护航。
2. 个性化服务
当前开源产品是提供标准化服务,应对企业的不同类型文档的解析结果则效果大相径庭。一些企业独特的文档结构或者单据样式,大部分开源文档解析产品都无法精准解析或者为企业个性化定制解析方案。而TextIn提供1对1的专属服务,为企业用户个性化的解决解析需求。“因地制宜”的为企业知识库的正常运转发挥作用。
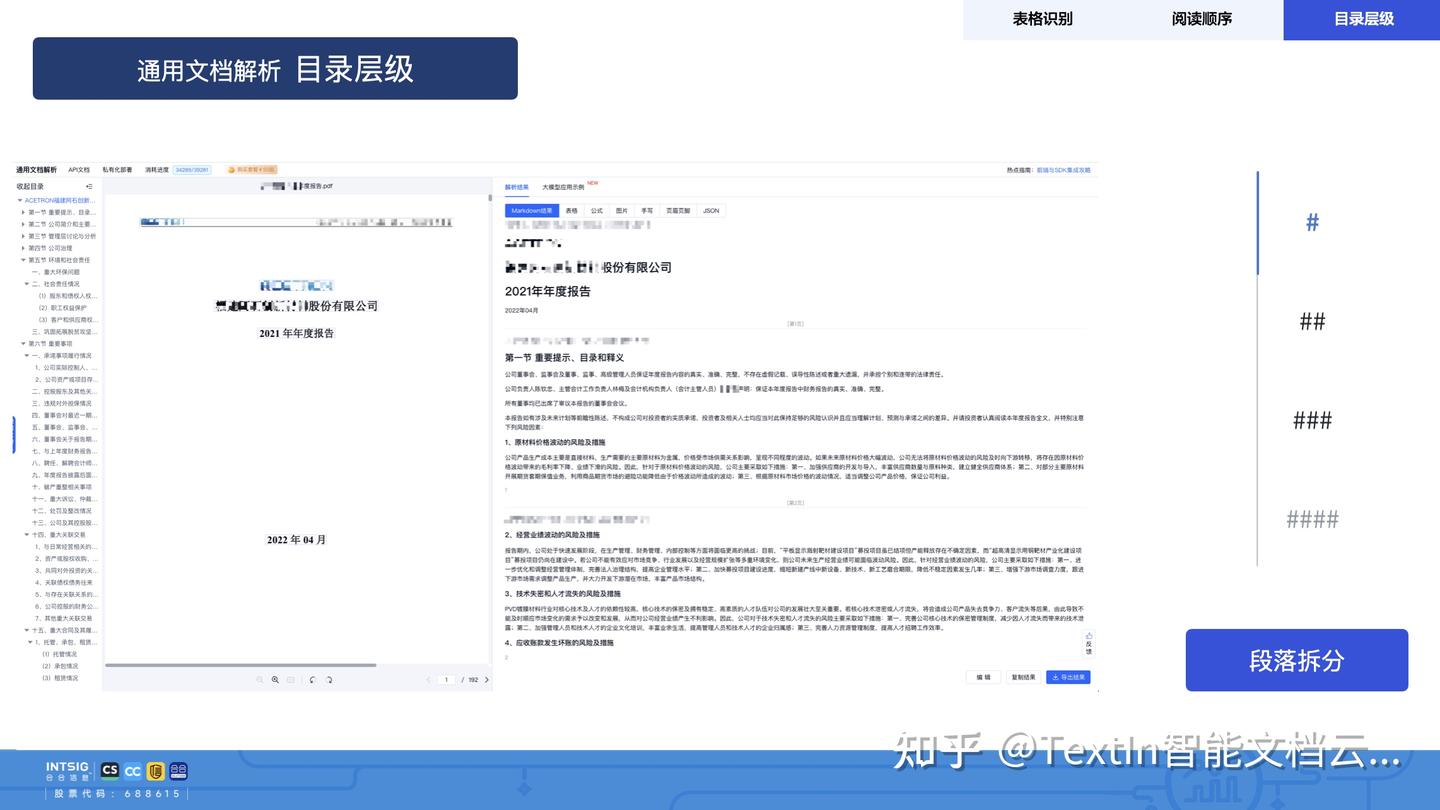
除了上述的独特优势,TextIn能够识别文档中的版面信息,将文档解析为Markdown格式,并按常见的阅读顺序进行还原,从而赋能下游各类大语言模型任务。它可以灵活接入全球多种类型大模型,配合完成企业端AI部署,让AI更好的融入企业日常业务场景中。
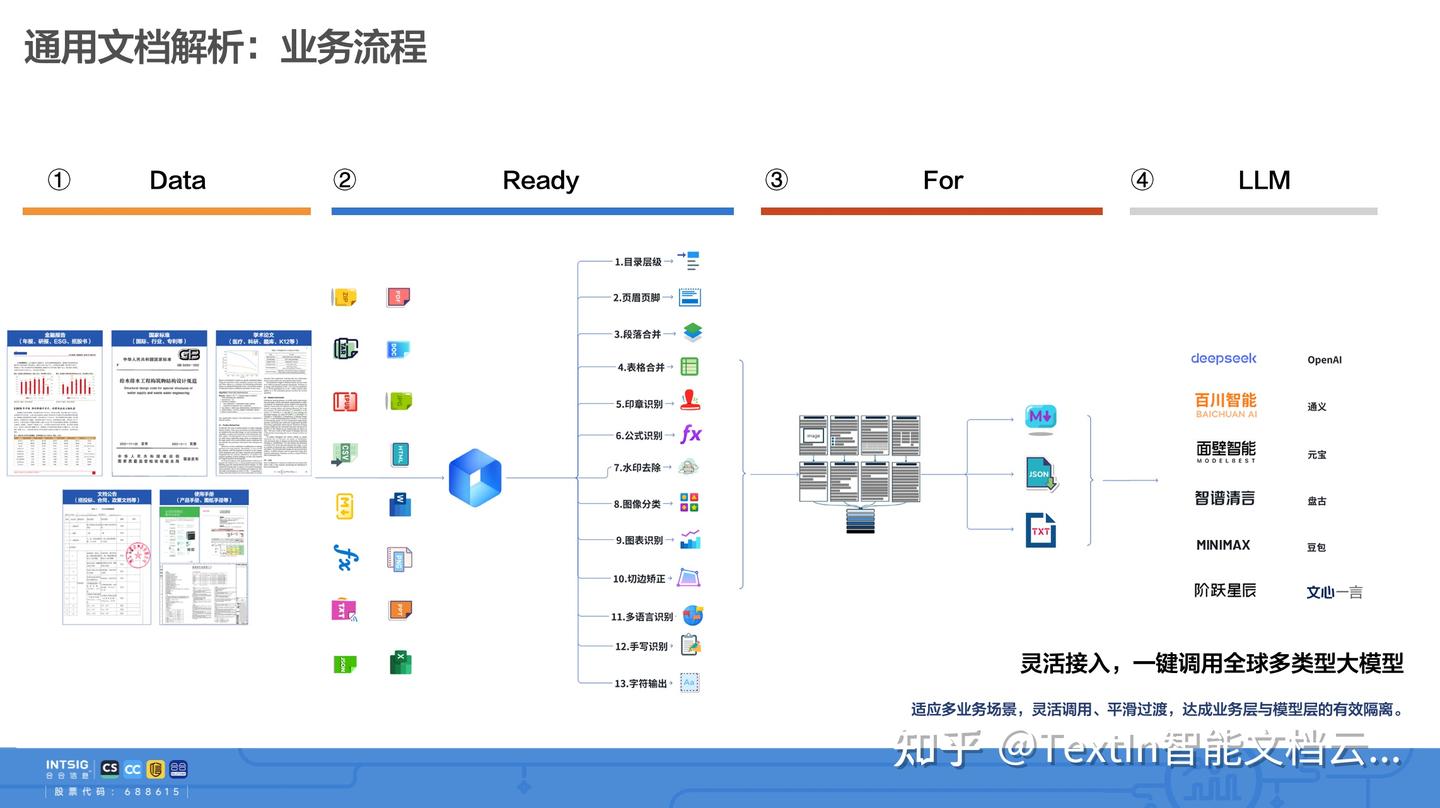
解析性能强大:
百页PDF批量解析≤1.5秒,面对文档的即时处理需求,可以显著压缩等待时间,超快速完成文档处理。另外TextIn支持PDF(含扫描件)、Office、HTML、图像等办公文档格式,并能保留原始层级结构,帮助大模型更好理解文档结构和上下文逻辑。
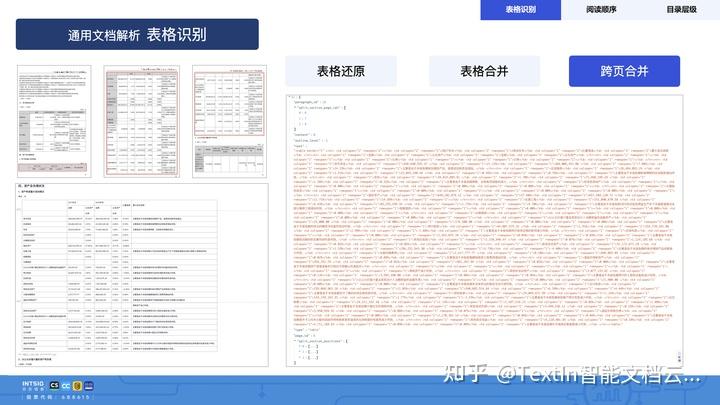
复杂元素解析:
TextIn支持一键分离文字、标题层级、公式、手写字符、图片等版面信息,并将表格转换为结构化数据(如Markdown表格),且保持行列关系。对于合并表格、合并跨页内容、合并单元格等传统解析难点都有95%以上的解析准确率。
最后,大模型一直都有“Garbage in, Garbage out”的说法,这强调了数据质量的重要性。一旦企业将输入文档的质量提升至高水平,则大模型的潜能即可被最大化的激发,RAG的发挥将更加稳定,知识库问答也将更加有实用价值,辅助企业及员工更好的提升工作效率,解放生产力。

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









