







本文主要内容为 MySQL 表中数据 的增删改查。
1. 数据查询
1.1. SELECT
SELECT column1,column2 FROM table1;
SELECT * FROM table1;
展示表table1中的叫column1和column2列的所有数据。
展示表table1中的所有列的所有数据。
DISTINCT
SELECT DISTINCT column1 FROM table1;
展示表table1中的列column1中的互不相同的数据。
AS
将输出的列名 更改(不更改表的列名)
若与关键字重复用 引号 括起
可以用空格替换AS
SELECT column1 AS c1 FROM table1;
SELECT t1.column1,t2.column1 FROM table1 t1, table2 t2 WHERE t1.column2 = t2.column2;
SELECT CONCAT(column1, column2) AS 'Information' from table1;
LIMIT
SELECT * FROM table1 LIMIT n;
SELECT * FROM table1 LIMIT n,m;
展示前n行的 表table1中的所有列的所有数据。
展示从第n+1行开始的m个行的数据。(表的第一行为行0,n表示行n)
☆注意 SELECT语句的 各查询语句顺序 为
SELECT + FROM + LEFT OUTER JOIN + ON / WHERE + GROUP BY + HAVING + ORDER BY + LIMIT
且顺序不能改变
1.2. 标量处理函数
本节描述的函数会对一列所有数据进行计算,即 函数名(列名) 会将 一整列数据作为输入计算
1.2.1. 字符处理函数
LENGTH()
返回字符串的大小,UTF8中 字母1字节汉字3字节
CONCAT()
可将输出的字符串、数字拼接
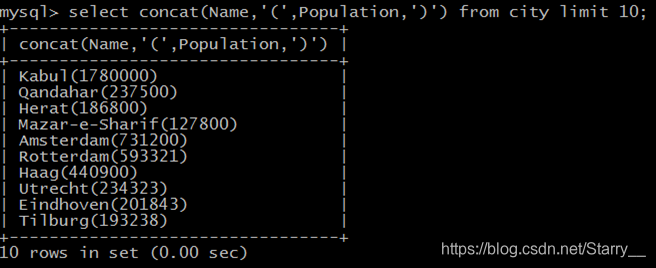
SELECT CONCAT(column1,'(',column2,')') FROM table1;
SELECT CONCAT(column1,10) FROM table1;
SELECT * From city where CONCAT(column1,column2) LIKE 'K%'
LTrim()与RTrim()
去掉左侧与右侧的空格
Left()与Right()
返回最左字符和最右字符
Upper()与Lower()
转换为大写 转换为小写
Substring(列名,数字n)
返回某个列,从第n个字符开始的子串
Replace(列名,字符串1,字符串2)
将某列的 所有 字符串1替换为 字符串2
SELECT LENGTH(column1) FROM table1 LIMIT 10;
SELECT LTrim(column1) FROM table1;
SELECT Lower(column1) FROM table1;
SELECT Substring(column1,2) From table1;
SELECT REPLACE(column1,'abc','def') FROM table1;
1.2.3. 数字处理函数
+-× ÷
四则运算
SELECT column1 + column2 FROM table1
Date(), Year(), Month(), Day(), Time()
分别返回datetime类型的日期、年、月、日、时间部分。
数据类型datetime按照 yyyy-mm-dd hh:mm:ss 的格式存储日期和时间。
例如
SELECT DATE(column1) FROM city LIMIT 10; //返回2021-1-9,...
SELECT * FROM table1 WHERE DATE(column1) BETWEEN '2020-01-01' AND '2021-01-01';
ROUND(), CEIL(), FLOOR()
分别是 四舍五入、向上取整和向下取整
Abs(), Mod(), Sin(), Cos(), Tan(), Sqrt()
一些数值处理函数,含义易懂。
1.3. 条件查询 WHERE
SELECT * FROM table1 WHERE column1 = 10
只展示column1列中元素等于10的数据。WHERE后可加上一个或多个条件判断句。
判断语句:
SELECT * FROM table1 WHERE column1='abc';
SELECT * FROM table1 WHERE column1 BETWEEN 10 AND 20; //[10,20]
SELECT * FROM table1 WHERE column1 IS NULL;
SELECT * FROM table1 WHERE column1 IS NOT NULL;
column1 = 10:列中元素为10
column1 = ‘abc’:列中元素为字符串abc
column1 != 10:不等于10,类似的还包括<,<=,>,>=, BETWEEN…AND…表示双闭区间
column1 IS NULL:判空
1.3.1 LIKE
SELECT * FROM table1 WHERE column1 LIKE "_jet%";
- SELECT * FROM table1 WHERE column1 LIKE 1
条件为 值为1的列。
除此之外还可以
LIKE ‘ject%’ :表示 jet+任意数量字符,零个也可
LIKE ‘ject_’ :表示 jet+ 一个字符,不可为零
1.3.2 REGEXP
SELECT * FROM table1 WHERE column1 REGEXP '1000';
SELECT * FROM table1 WHERE column1 REGEXP '[1-10] ton';
SELECT * FROM table1 WHERE column1 REGEXP '\\([123] jobs\\)';
- SELECT * FROM table1 WHERE column1 REGEXP 正则表达式
条件为 值包含1的列,这里的REGEXP后面将使用正则表达式。
正则表达式:
‘1000’:表示含有‘1000’的(注意和LIKE为形式相区分)
‘jet . 1000’:此处点.表示任意一个字符
‘100|200|300|400 24’:表示100或200或300或400 24
‘[123] 90’:表示1 90或2 90或3 90,同时还等价于’[1-3] 90’
‘\\+字符’:表示匹配字符,例如\\f换页,\\n表示换行,\\r表示回车
1.3.3 OR、AND 与 IN
SELECT * FROM table1 WHERE (column1=10 OR column2<100)AND column3 >=50;
SELECT * FROM table1 WHERE column1 IN (1,10,51,84196,478,979,87);
SELECT * FROM table1 WHERE column1 NOT IN(1,10,23,423,13,3); // 没有 IS !!!
column1 = 10 OR column2 = 100: 两个条件或的关系,类似的还包括 AND。
column1 = 10 OR (column2 = 100 AND column3 = 1): 可用括号包括以标明顺序。
IN (1,2,3,4,5,6,7,8,9):等价于column1 = 1 OR column1 = 2 OR …OR column1 = 9
NOT IN (1,2):表示对column1 = 1 OR column1 = 2取非,但不可对其他语句取非,例如NOT column1 = 10则错误。
1.3.4 ANY 与 ALL
ANY 指 存在一个,任意一个 即可。
ALL 指 所有 全部
SELECT table1.column1,NULL FROM table1 WHERE table1.column2 != ALL (SELECT column2 FROM table2);
1.3.5 子查询
子查询主要包括 标量、列 和 行子查询。顾名思义,就是 子查询返回的结果 为标量、列 和行。
SELECT name,job_id,salary FROM employees WHERE job_id = (SELECT job_id FROM employees WHERE job_id = 141) AND salary > (SELECT salary FROM employees WHERE job_id = 143 );
SELECT name,job_id,salary FROM employees WHERE job_id != 'IT_PROG' AND salary > (SELECT MAX(salary) FROM employees WHERE job_id = 'IT_PROG');
SELECT * FROM employees WHERE (employee_id,salary) = (SELECT (MIN(employee_id),MAX(salary)) FROM employees);
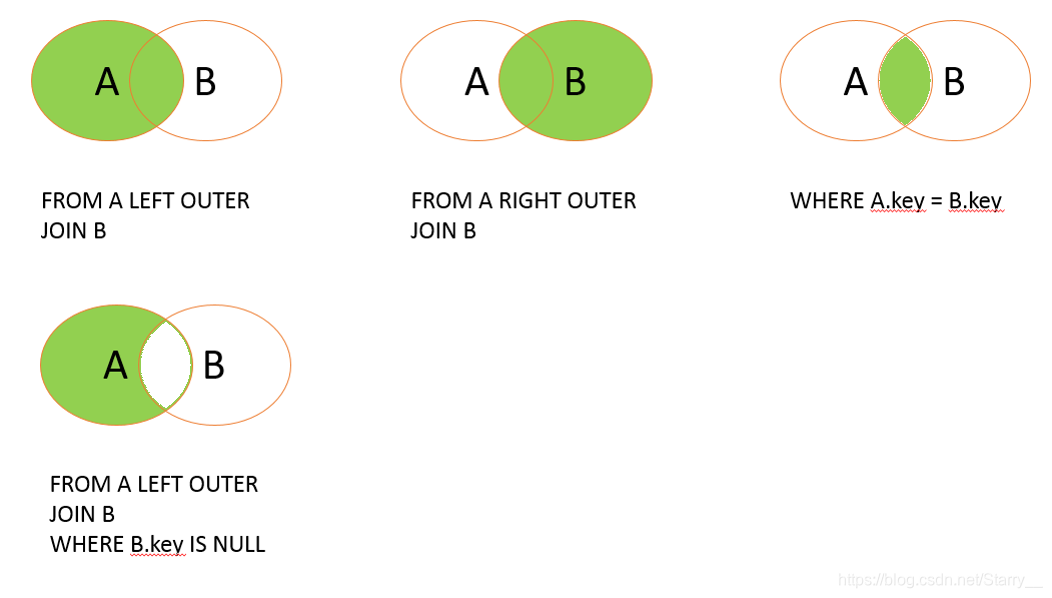
1.3.6 外联结查询 LEFT OUTER JOIN…ON…
指查询 主表 中的某些字段,给出这些字段 与 从表 字段 的匹配结果,若存在无法匹配的 从表 则相应输出NULL。
即最终得到的是 多表能够匹配的结果 ∪ 存在一个从表不能匹配的结果。
主表 LEFT OUTER JOIN 从表 ON 条件
注意一定要在 WHERE前使用,还可以 用.修饰 字段所属 的表名,以防歧义。
SELECT table1.column1,table2.column1 FROM table1 LEFT OUT JOIN table2 ON table1.column2 = table2.column2;
内联结查询
只 查询能够匹配 的字段,可以直接用WHERE,也可以在 外联结 的基础上 排除为NULL的字段。
还可以使用 INNER JOIN 和ON 关键字,但没必要。
SELECT table1.column1 FROM table1,table2 WHERE table1.column2 = table2.column2;
SELECT table1.column1 FROM table1,table2,table3 WHERE table1.column2 = table2.column2 AND table3.column1 IS NOT NULL;
SELECT t1.column1 FROM table1 t1,table1 t2 WHERE t1.column2 = t2.column1; //自联结查询
SELECT column1 FROM table1 LEFT OUTER JOIN table2 ON table1.column1= table2.column2 WHERE table2.column2 IS NOT NULL //使用关键字INNER JOIN和ON
综上使用一张图解释 联结表
1.4. 分组查询 GROUP BY
指 根据某一列,将该列中 数据相同 的合并为一组,返回 该组的特征(分组函数)
1.4.1. 分组函数
分组函数或叫统计函数,表示 对一整个列的数据进行 统计,得到某个标量数据。
MIN(), MAX()
返回某列的最小值最大值,可用于字符列,从第一位字符算起,按照符号-数字-小写-大写的顺序寻找最值。忽略NULL的行
SUM(), AVG()
求和与平均数,忽略NULL的行
COUNT()
计算某列的行数,不算NULL值。
COUNT(*)表示计算 满足条件的行数,算上NULL。
下面给出例子,注意以上函数可以与DISTINCT配合使用,但不可COUNT( DISTINCT * )
SELECT SQRT(column1 * column1 + column2 * column2) AS 'Distance' FROM table1 WHERE LIMIT 10;
SELECT AVG(DISTINCT column1) FROM table1 WHERE column2 > 10;
SELECT COUNT(DISINCT column1) FROM table1 WHERE column2 = 100;
SELECT COUNT(DISINCT *) FROM table1; //非法
1.4.2. 分组查询 GROUP BY
将表按照 某一列中内容相同的行 分组。即 将某一列中 内容相同的行 合并在一起进行统计。
SELECT SUM(column1),column1 FROM table1 GROUP BY column2; //将column2内容相同的行分为一组,并计算每一组的column1的和。
SELECT COUNT(*),column2 FROM table1 WHERE column2 > 1000 GROUP BY column2;
//先筛选出 column2>1000的行,再按照column2分组,输出各组的行数。
1.4.3. 过滤分组 HAVING
使用group by分好组之后,某些 不满足 组条件的组要剔除,例如 组的平均值较低的、组的行数较低的等等。
使用HAVING,后面加上过滤组的条件。
SELECT MIN(column1) FROM table1 WHERE column2 > 100 GROUP BY column3 HAVING AVG(column4)>10;
//剔除column2 > 100的行,然后按照column3进行分组,再保留column4平均值大于10的组,输出column1的最小值
1.4.4. WHERE 还是 HAVING ?
首先分组的依据很好找,题目中每个后面的字段就是 GROUP BY 的列名。
然后找修饰,限定词每组统一 则用 HAVING,如果限定词不是每组都统一则用 WHERE
例如 “面积大于10000的每个地区”用HAVING 、“每个地区中的美国人”用WHERE、“平均年龄大于40的各地区”用HAVING
例如:
- 邮箱中的包含a的每个部门的平均工资
- 查询有奖金的每个领导手下员工的最高工资
- 哪个部门的员工>2
- 每个工种里,有奖金的员工的最高工资>12000的工种编号和最高工资
- 领导编号>102,每个领导手下的员工最低工资>5000,输出领导编号,以及最低工资
- 查询各job_id员工工资的最大值、最小值、平均值、总和,按照job_id升序
- 查询各job_id的员工最高工资和最低工资的差
- 查询各管理者手下员工的最低工资,除去最低工资低于6000,和无管理者的员工
- 查询所有部门的编号,员工数量和工资平均值,按平均工资降序
- 选择具有各job_id员工的人数
1.SELECT AVG(salary) FROM employees WHERE mailbox LIKE '%a%' GROUP BY department_id;
2.SELECT MAX(salary) FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;
3.SELECT COUNT(*), department_id FROM employees GROUP BY department_id HAVING COUNT(*) > 2;
4.SELECT MAX(salary),job_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY job_id HAVING MAX(salary) > 12000;
5.SELECT MIN(salary), manager_id FROM employees GROUP BY manager_id HAVING manager_id > 102 AND MIN(salary) > 5000;
6.SELECT MAX(salary),MIN(salary),AVG(salary),SUM(salary) FROM employees GROUP BY job_id ORDER BY job_id;
7.SELECT MAX(salary) - MIN(salary) FROM employees GROUP BY job_id;
8.SELECT MIN(salary) FROM employees WHERE manager_id IS NOT NULL GROUP BY manager_id HAVING MIN(salary) >= 6000;
9.SELECT COUNT(*),AVG(salary),department_id FROM employees GROUP BY department_id ORDER BY DESC AVG(salary);
10.SELECT COUNT(*) FROM employees GROUP BY job_id;
1.5. 排序查询 ORDER BY
ORDER BY 与 DESC
SELECT * FROM table1 ORDER BY column1;
SELECT * FROM table1 ORDER BY DESC column1, column2;
按照column1的 符号+数字+小写+大写 的正向顺序,如果column1的两个元素相同则再按照column2的上述顺序,排列输出结果。
展示所有数据,并按照column1的 逆顺序、column2的正顺序排列,且只显示前10行。
(注意上述排序只是在展示数据时排列,对表不做任何修改)
1.6. 查询语句联合 UNION
使用 UNION 将 两条查询语句联合起来,输出为 两个查询语句结果的合并。
但注意两个输出的结果的列数必须一致,且UNION 之间的查询语句无需分号;
UNION会自动去重,选择UNION ALL 可以 不去重
SELECT table1.column1,table2.column1 FROM table1,table2 WHERE table1.column2 = table2.column2
UNION
SELECT column1,NULL FROM table1 WHERE column2 != ALL (SELECT column2 FROM table2); //该语句等价于外查询结果。
2. 数据插入 INSERT INTO…VALUES…
即向表中插入一行数据。
-
INSERT INTO 表名
VALUES (列1数据,列2数据,NULL,…),(列1数据,列2数据,NULL,…),… -
INSERT INTO 表名(列1,列3,列5)
VALUES (列1数据,列3数据,列5数据,),(列1数据,列3数据,列5数据,),… -
INSERT INTO 表名(列3,列2,列1)
VALUES (列3数据,列2数据,列1数据,),(列3数据,列2数据,列1数据,),… -
INSERT INTO 表名(列1,列2,列3)
SELECT 列1,列2,列3 FROM 表名 WHERE 条件
注意 NULLable 的列 可以为NULL,否则不能为NULL,也不能省去不填。INSERT 支持子查询结果插入。
并且插入之后,不会输出新表,刷新之后打开表即可。
INSERT INTO beauty(id,NAME,sex,borndate,phone)
VALUES(15,'蒋欣','女','1980-01-04 00:00:00','12345678910'),(16,'杨超越','女','1990-01-04 00:00:00','12345678910');
INSERT INTO beauty(id,name,phone)
SELECT id,name,phone FROM boys WHERE id<3;
INSERT INTO targets
SELECT 2,'RADAR',devices.id FROM devices WHERE devices.device_name = 'EO';
2. 数据修改 UPDATE… SET…
修改表中数据
- UPDATE 表名
SET 列1 = 列1数据,列2 = 列2数据,列3 = 列3数据
WHERE 条件
UPDATE table1 set column1 = 'eat',column2 = 'apple',column3 = 'a' WHERE column4 > 5;
UPDATE table1 set column1 = 1,column3 = 3 WHERE table1.column2 = table2.column3;
3. 数据删除 DELETE FROM与 TRUNCATE
即删除表中的某些行 或 清空表。
- DELETE FROM 表名 WHERE 条件
- TRUNCATE TABLE 表名
分别是删除某些行 以及 清空表。
注意delete之后,再插入行,行的主键(序号)将从断点处添加,例如 table1 为1-5行,使用 delete 删除了4、5行,再insert则为6行起始,即table1主键变成1,2,3,6.
truncate不可回滚,delete可以回滚
DELETE FROM table1 WHERE column1 = '唐%';
TRUNCATE TABLE table1;


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











