




文章目录
相关文章
Transformer架构:结构介绍:网页链接
Transformer架构:输入部分代码实现(基于PyTorch):网页链接
Transformer架构:核心模块代码实现(基于PyTorch):网页链接
Transformer架构:编码器部分代码实现(基于PyTorch):网页链接
Transformer架构:解码器部分代码实现(基于PyTorch):网页链接
Transformer架构:输出部分代码实现(基于PyTorch):网页链接
一、Transformer整体架构与核心作用
Transformer是一种基于自注意力机制的序列转换模型,通过编码器-解码器架构实现端到端的序列建模任务(如机器翻译、文本摘要、问答系统等)。其核心优势在于:
- 并行计算能力:相比RNN类模型的时序依赖,Transformer通过自注意力机制实现序列元素的并行处理,大幅提升训练效率。
- 长距离依赖捕捉:自注意力机制通过动态计算 token 间的关联权重,有效解决了传统模型对长序列依赖捕捉不足的问题。
- 灵活的跨模态对齐:编码器-解码器架构天然支持源序列与目标序列的语义关联,适用于各类序列转换任务。
整体架构由六大核心组件构成:
- 输入处理模块(词嵌入+位置编码)
- 编码器(Encoder):处理源序列,输出上下文特征
- 解码器(Decoder):基于编码器输出和目标序列历史,生成目标序列
- 多头注意力机制:模型的核心计算单元
- 前馈网络:增强模型非线性拟合能力
- 输出层(Generator):将解码器输出转换为词汇概率分布
二、Transformer整体工作流程图
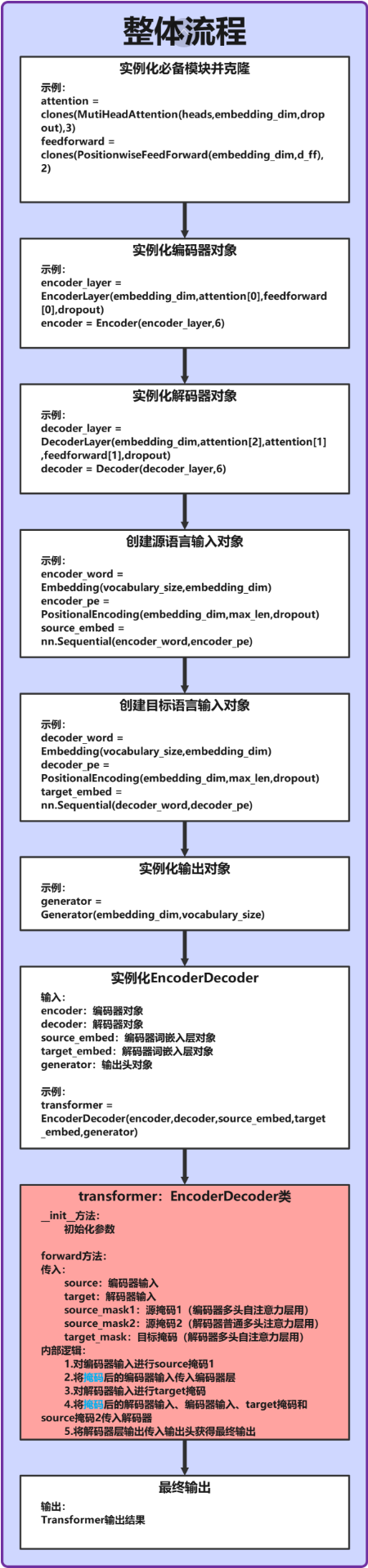
(注:上图为示意图,实际流程需结合代码细节理解)
核心流程说明:
- 源序列(如中文句子)经输入处理模块转换为向量表示,送入编码器得到上下文特征。
- 目标序列(如英文句子)经输入处理模块转换为向量表示,与编码器输出共同送入解码器。
- 解码器通过自注意力和编码器-解码器注意力生成目标序列特征。
- 输出层将解码器特征转换为词汇表上的概率分布,完成序列生成。
三、核心组件协同工作机制
3.1 输入处理模块:序列向量化
输入处理模块负责将离散的词汇索引转换为包含语义和位置信息的连续向量,由Embedding和PositionalEncoding组成。
# 源语言输入处理(编码器侧)
encoder_word = Embedding(vocabulary_size, embedding_dim) # 词嵌入
encoder_pe = PositionalEncoding(embedding_dim, max_len, dropout) # 位置编码
source_embed = nn.Sequential(encoder_word, encoder_pe) # 组合为序列
# 目标语言输入处理(解码器侧)
decoder_word = Embedding(vocabulary_size, embedding_dim)
decoder_pe = PositionalEncoding(embedding_dim, max_len, dropout)
target_embed = nn.Sequential(decoder_word, decoder_pe)
工作流程:
- 词嵌入:将词汇索引
[batch_size, seq_len]映射为[batch_size, seq_len, embedding_dim]的语义向量。 - 位置编码:通过正弦余弦函数生成位置特征,与词嵌入相加,保留序列顺序信息。
3.2 编码器:源序列特征提取
编码器由N个EncoderLayer堆叠而成,每个层包含“多头自注意力”和“前馈网络”两个子层。
# 编码器构建
attention = clones(MutiHeadAttention(heads, embedding_dim, dropout), 3) # 注意力实例
feedforward = clones(PositionwiseFeedForward(embedding_dim, d_ff), 2) # 前馈网络实例
encoder_layer = EncoderLayer(embedding_dim, attention[0], feedforward[0], dropout) # 单编码器层
encoder = Encoder(encoder_layer, 6) # 6层堆叠编码器
工作流程:
- 输入向量经多头自注意力捕捉源序列内部依赖(如“天气”与“晴朗”的关联)。
- 前馈网络对注意力输出进行非线性变换,增强特征表达能力。
- 每层通过残差连接和LayerNorm稳定训练,多层堆叠实现特征逐步优化。
3.3 解码器:目标序列生成
解码器由N个DecoderLayer堆叠而成,每个层包含“掩码自注意力”“编码器-解码器注意力”和“前馈网络”三个子层。
# 解码器构建
decoder_layer = DecoderLayer(embedding_dim, attention[2], attention[1], feedforward[1], dropout) # 单解码器层
decoder = Decoder(decoder_layer, 6) # 6层堆叠解码器
工作流程:
- 掩码自注意力:仅允许目标序列关注已生成的token(如生成第i个词时,仅看1~i个词),避免未来信息泄露。
- 编码器-解码器注意力:使用目标序列作为查询(query),编码器输出作为键值对(key=value),实现跨序列语义对齐。
- 前馈网络:进一步优化特征,多层堆叠提升生成质量。
3.4 输出层:词汇概率生成
输出层Generator将解码器输出的特征向量转换为词汇表上的概率分布,用于预测下一个token。
# 输出层构建
generator = Generator(embedding_dim, vocabulary_size)
工作流程:
- 线性层将
[batch_size, seq_len, embedding_dim]映射为[batch_size, seq_len, vocabulary_size]。 - log_softmax归一化得到概率分布,便于计算交叉熵损失。
四、整体架构封装:EncoderDecoder类
EncoderDecoder类将上述组件整合为完整模型,定义了从输入到输出的端到端计算流程。
4.1 代码实现与结构解析
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, source_embed, target_embed, generator):
super().__init__()
self.encoder = encoder # 编码器实例
self.decoder = decoder # 解码器实例
self.source_embed = source_embed # 源序列输入处理
self.target_embed = target_embed # 目标序列输入处理
self.generator = generator # 输出层
def forward(self, source, target, source_mask1, source_mask2, target_mask):
# 1. 源序列编码
encode_word_embed = self.source_embed(source) # 源序列嵌入+位置编码
encoder_output = self.encoder(encode_word_embed, source_mask1) # 编码器输出
# 2. 目标序列解码
decoder_word_embed = self.target_embed(target) # 目标序列嵌入+位置编码
decoder_output = self.decoder(decoder_word_embed, encoder_output, target_mask, source_mask2) # 解码器输出
# 3. 生成词汇概率
output = self.generator(decoder_output)
return output
4.2 前向传播完整流程
-
输入处理:
- 源序列
source(形状[batch_size, src_seq_len])→ 经source_embed转换为[batch_size, src_seq_len, embedding_dim]。 - 目标序列
target(形状[batch_size, tgt_seq_len])→ 经target_embed转换为[batch_size, tgt_seq_len, embedding_dim]。
- 源序列
-
编码过程:
- 源序列嵌入向量与
source_mask1(源序列自注意力掩码)送入编码器,输出encoder_output(形状[batch_size, src_seq_len, embedding_dim])。
- 源序列嵌入向量与
-
解码过程:
- 目标序列嵌入向量、
encoder_output、target_mask(目标序列自注意力掩码)、source_mask2(编码器-解码器注意力掩码)送入解码器,输出decoder_output(形状[batch_size, tgt_seq_len, embedding_dim])。
- 目标序列嵌入向量、
-
输出生成:
decoder_output经generator转换为[batch_size, tgt_seq_len, vocabulary_size]的概率分布。
五、关键掩码机制解析
Transformer通过三种掩码确保模型正确学习序列依赖:
-
source_mask1(源序列自注意力掩码):
- 形状:
[heads, src_seq_len, src_seq_len] - 作用:屏蔽源序列中的填充token(如PAD),避免注意力关注无效信息。
- 形状:
-
target_mask(目标序列自注意力掩码):
- 形状:
[heads, tgt_seq_len, tgt_seq_len] - 作用:通过下三角矩阵屏蔽未来token,确保生成时仅依赖已生成内容( autoregressive 特性)。
- 形状:
-
source_mask2(编码器-解码器注意力掩码):
- 形状:
[heads, tgt_seq_len, src_seq_len] - 作用:在解码器查询编码器输出时,屏蔽源序列中的填充token。
- 形状:
六、完整模型测试与验证
通过test_complete函数验证Transformer整体功能,观察各环节的张量形状变化:
def test_complete():
# 1. 实例化核心组件
attention = clones(MutiHeadAttention(heads, embedding_dim, dropout), 3)
feedforward = clones(PositionwiseFeedForward(embedding_dim, d_ff), 2)
# 编码器
encoder_layer = EncoderLayer(embedding_dim, attention[0], feedforward[0], dropout)
encoder = Encoder(encoder_layer, 6)
# 解码器
decoder_layer = DecoderLayer(embedding_dim, attention[2], attention[1], feedforward[1], dropout)
decoder = Decoder(decoder_layer, 6)
# 输入处理
source_embed = nn.Sequential(Embedding(vocabulary_size, embedding_dim), PositionalEncoding(embedding_dim, max_len, dropout))
target_embed = nn.Sequential(Embedding(vocabulary_size, embedding_dim), PositionalEncoding(embedding_dim, max_len, dropout))
# 输出层
generator = Generator(embedding_dim, vocabulary_size)
# 2. 构建完整模型
transformer = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
# 3. 准备测试数据
source = torch.tensor([[1,2,3,4], [7,8,9,10]]) # 源序列(2条样本,每条4个token)
target = torch.tensor([[10,20,30,40,50,60], [70,80,90,100,110,120]]) # 目标序列(2条样本,每条6个token)
source_mask1 = torch.zeros(heads, source.shape[-1], source.shape[-1]) # 源自注意力掩码
source_mask2 = torch.zeros(heads, target.shape[-1], source.shape[-1]) # 编码器-解码器掩码
target_mask = torch.zeros(heads, target.shape[-1], target.shape[-1]) # 目标自注意力掩码
# 4. 前向传播
result = transformer(source, target, source_mask1, source_mask2, target_mask)
# 5. 输出验证
print(f'最终输出形状:{result.shape}') # 预期:[2, 6, 1024](batch_size=2, tgt_seq_len=6, vocabulary_size=1024)
print(f'与PyTorch官方实现对比:')
# 官方Transformer测试
source_input = untest_input(source) # 转换为嵌入向量
target_input = untest_input(target)
nn_transformer = nn.Transformer(batch_first=True)
nn_result = nn_transformer(source_input, target_input)
print(f'官方Transformer输出形状:{nn_result.shape}') # 预期:[2, 6, 512]
6.1 核心组件实例化
# 实例化3个多头注意力模块(编码器自注意力/解码器-编码器注意力/解码器自注意力)
attention = clones(MutiHeadAttention(heads, embedding_dim, dropout), 3)
# 实例化2个前馈网络(编码器/解码器各用1个)
feedforward = clones(PositionwiseFeedForward(embedding_dim, d_ff), 2)
- 多头注意力机制通过
clones函数复制3份,分别用于编码器自注意力、解码器自注意力、解码器-编码器交叉注意力 - 前馈网络复制2份,分别给编码器层和解码器层使用
6.2 编码器与解码器构建
# 编码器:6层EncoderLayer堆叠
encoder_layer = EncoderLayer(embedding_dim, attention[0], feedforward[0], dropout)
encoder = Encoder(encoder_layer, 6)
# 解码器:6层DecoderLayer堆叠
decoder_layer = DecoderLayer(embedding_dim, attention[2], attention[1], feedforward[1], dropout)
decoder = Decoder(decoder_layer, 6)
- 编码器使用第1个注意力模块(
attention[0])和第1个前馈网络 - 解码器中:
attention[2]用于解码器自注意力(query=key=value=目标序列)attention[1]用于交叉注意力(query=目标序列,key=value=编码器输出)
6.3 输入处理模块
# 源序列嵌入:词嵌入 + 位置编码
source_embed = nn.Sequential(
Embedding(vocabulary_size, embedding_dim),
PositionalEncoding(embedding_dim, max_len, dropout)
)
# 目标序列嵌入:与源序列共享结构(参数独立)
target_embed = nn.Sequential(
Embedding(vocabulary_size, embedding_dim),
PositionalEncoding(embedding_dim, max_len, dropout)
)
- 输入处理包含两个关键步骤:
- 词嵌入:将离散token索引转为
embedding_dim维稠密向量 - 位置编码:通过正弦余弦函数注入位置信息,解决Transformer无序列感知的问题
- 词嵌入:将离散token索引转为
6.4 输出层与完整模型组装
# 输出层:将解码器输出映射到词汇表空间
generator = Generator(embedding_dim, vocabulary_size)
# 组装完整Transformer
transformer = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
Generator通过线性层将embedding_dim维特征映射到vocabulary_size维,配合log_softmax输出概率分布
6.5 测试数据与掩码策略(重点)
# 测试数据:2条样本,源序列长度4,目标序列长度6
source = torch.tensor([[1,2,3,4], [7,8,9,10]])
target = torch.tensor([[10,20,30,40,50,60], [70,80,90,100,110,120]])
# 掩码说明(此处为演示用全零掩码,实际应用需根据场景设计):
# 1. 源自注意力掩码(source_mask1):[heads, 4, 4]
# 作用:掩盖源序列中的padding token,避免注意力关注无效位置
source_mask1 = torch.zeros(heads, source.shape[-1], source.shape[-1])
# 2. 编码器-解码器掩码(source_mask2):[heads, 6, 4]
# 作用:解码器关注编码器输出时,掩盖源序列的padding token
source_mask2 = torch.zeros(heads, target.shape[-1], source.shape[-1])
# 3. 目标自注意力掩码(target_mask):[heads, 6, 6]
# 作用:
# - 掩盖目标序列的padding token
# - 通过上三角掩码实现"自回归",确保预测第i个token时仅关注前i-1个token
target_mask = torch.zeros(heads, target.shape[-1], target.shape[-1])
- 实际掩码设计:
- padding mask:用
True/False标记无效token位置 - sequence mask:对目标序列使用上三角矩阵,避免未来信息泄露
- padding mask:用
6.6 前向传播与结果验证
# 自定义模型前向传播
result = transformer(source, target, source_mask1, source_mask2, target_mask)
print(f'最终输出形状:{result.shape}') # [2, 6, 1024]
# 对应:[batch_size, 目标序列长度, 词汇表大小]
# 与PyTorch官方实现对比
source_input = untest_input(source) # 转换为嵌入向量[2,4,512]
target_input = untest_input(target) # 转换为嵌入向量[2,6,512]
nn_transformer = nn.Transformer(batch_first=True)
nn_result = nn_transformer(source_input, target_input)
print(f'官方Transformer输出形状:{nn_result.shape}') # [2,6,512]
- 自定义模型输出直接映射到词汇表空间,可用于预测
- 与官方实现中间特征维度一致,验证了基础架构的正确性
七、完整代码整合
GitCode链接:网页链接


















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









