




文章目录
欢迎查看我的公众号原文
细嗦Transformer(一): 整体架构及代码实现
也欢迎关注我的公众号:

Transformer架构
Q1: 简单描述一下Transformer架构
Transformer模型由Encoder和Decoder两部分组成,Encoder和Decoder部分又分别是由多个encoder和decoder层堆叠而成。每个encoder层包含有两个子层,分别为多头注意力机制层和全连接前馈神经网络,在两个子层后分别添加残差连接和层归一化。每个decoder层结构与encoder类似,由3个子层组成,分别为掩码注意力、交叉注意力和全连接前馈神经网络。在输入部分都使用了正余弦位置编码,Decoder最后输出时还要经过一次线性变化和Softmax。
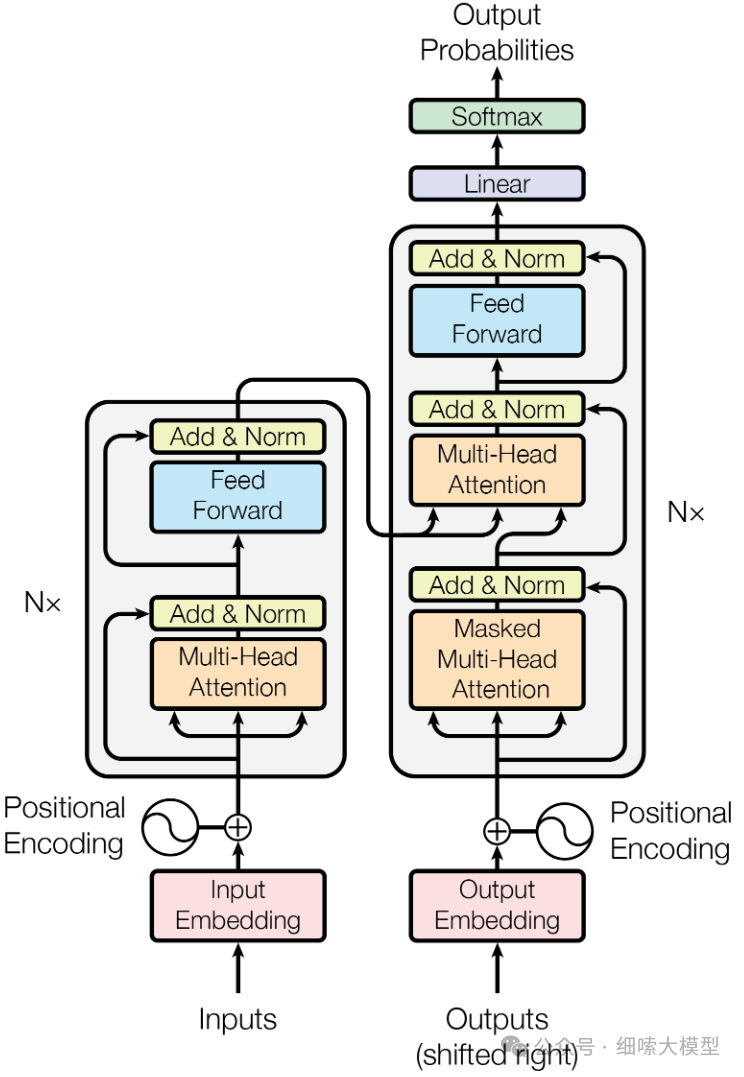
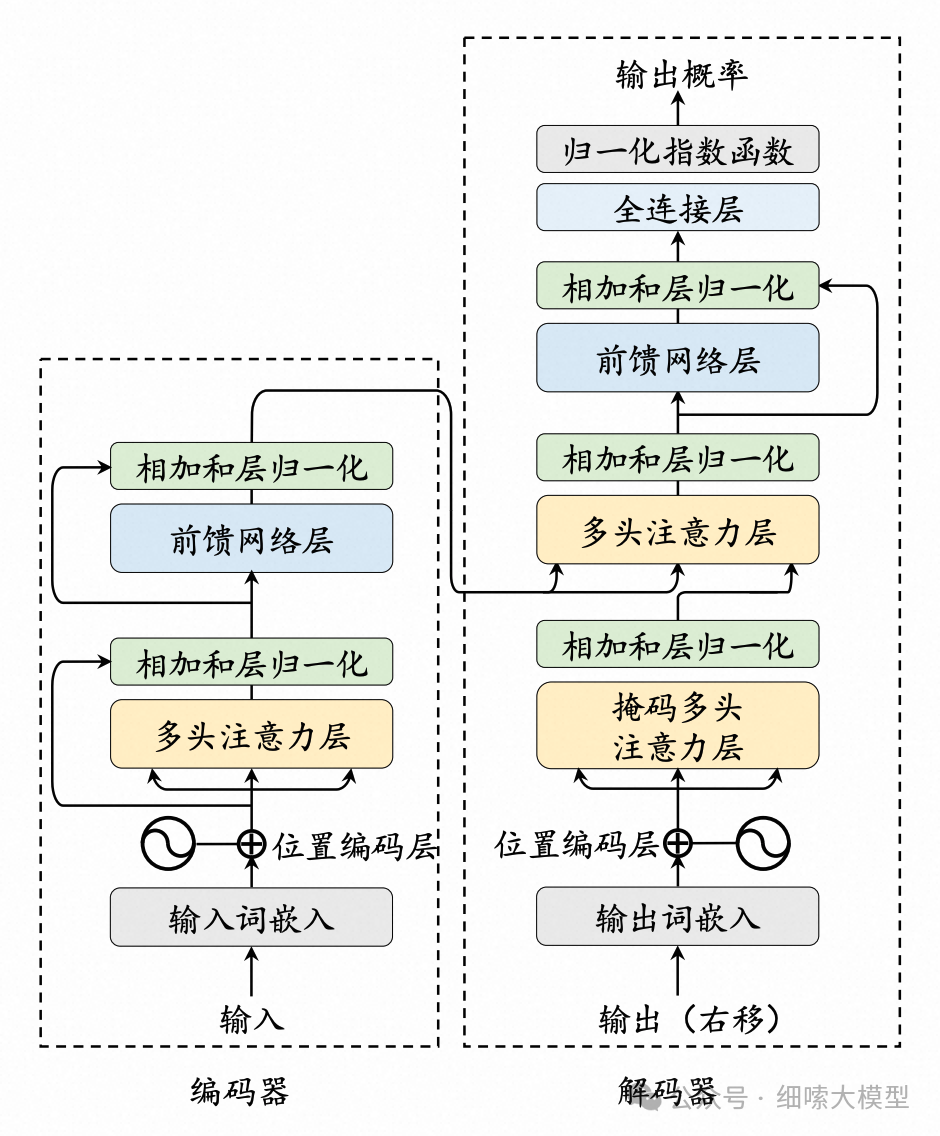
如果理解了这个架构图,那一定能够清晰地说出:
-
编码器和解码器分别由多个EncoderLayer和DecoderLayer堆叠而成。
-
一个EncoderLayer有2个子层,一个DecoderLayer有3个子层。
-
每个子层后面都有Add & Norm(残差连接和层归一化)
-
交叉注意力机制是接受编码器中最后一个EncoderLayer输出的 K , V K,V K,V, Q Q Q来自于掩码多头注意力层。
-
掩码注意力机制,掩盖大于等于i部分的序列。
-
编码器解码器输入部分都有位置编码,采用的是正余弦位置编码。
-
解码器最后的输出需要经过全连接层,将最后一个DecoderLayer的输出映射成词表大小的向量,再经过Softmax得到词表中每个词的预测概率,概率最大的即为预测的词。
Transformer架构代码实现
Transformer architecture
下面,我们按照自顶向下的顺序,搭建Transformer的整体框架,注意力机制等细节的实现,我们放到后续文章中实现。
Encoder-Decoder架构
下面是一个标准的Encoder-Decoder架构实现。是最后的输出部分,经过一个标准线性变化
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder # 编码器部分
self.decoder = decoder # 解码器部分
self.src_embed = src_embed # 编码器输入的嵌入层Embedding
self.tgt_embed = tgt_embed # 解码器输入的嵌入层Embedding
self.generator = generator # 最后的线性层和softmax层
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask) # Embedding完之后才传入编码器
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









