




文章目录
相关文章
Transformer架构:结构介绍:网页链接
Transformer架构:输入部分代码实现(基于PyTorch):网页链接
Transformer架构:核心模块代码实现(基于PyTorch):网页链接
Transformer架构:编码器部分代码实现(基于PyTorch):网页链接
Transformer架构:解码器部分代码实现(基于PyTorch):网页链接
Transformer架构:整体实现代码(基于PyTorch):网页链接
一、输出部分的核心作用
在Transformer架构中,输出部分(Generator)是连接模型特征与任务目标的“最后一公里”,负责将解码器输出的高维特征转化为可直接用于预测的词表概率分布。其核心功能体现在:
- 特征映射:将解码器输出的
[batch_size, seq_len, embedding_dim]特征张量,通过线性变换映射到词表维度(vocab_size),实现“特征→词表”的维度转换。 - 概率归一化:使用
log_softmax对输出进行归一化,既保证概率总和为1,又通过对数形式提升数值稳定性,便于后续计算负对数似然损失(NLLLoss)。 - 生成决策:为序列生成任务(如机器翻译、文本生成)提供每个位置的预测词概率,支持贪婪搜索、束搜索等解码策略。
二、输出部分工作流程图
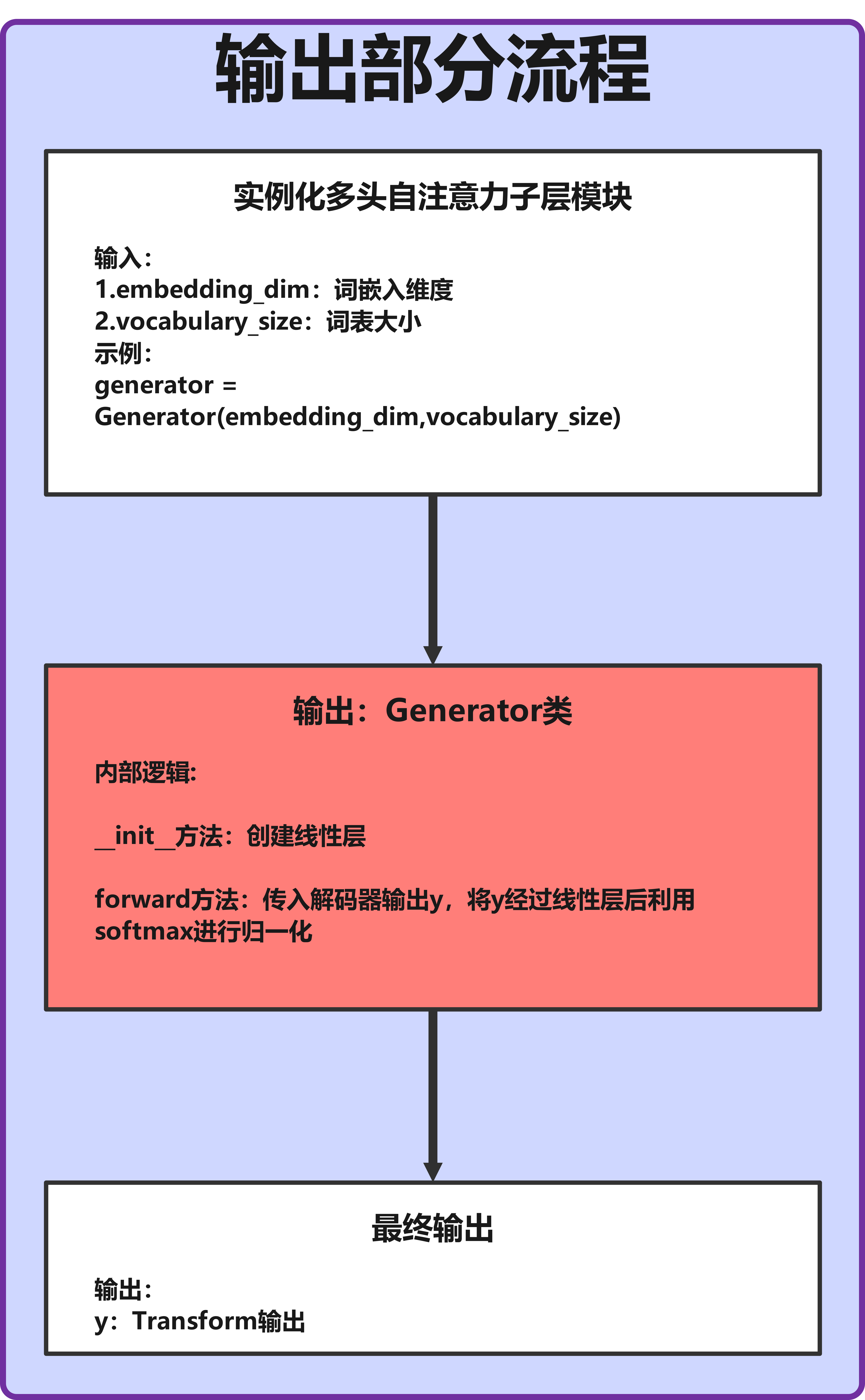
流程说明:
- 输入:解码器输出的特征张量(形状:
[batch_size, tgt_seq_len, embedding_dim])。 - 线性层:将
embedding_dim维度的特征映射到vocab_size维度(形状:[batch_size, tgt_seq_len, vocab_size])。 - Log-Softmax:对最后一个维度进行归一化,输出每个token的对数概率(形状不变)。
- 输出:可直接用于计算损失(训练阶段)或生成预测结果(推理阶段)。
三、输出部分核心代码实现与解析
Transformer输出部分的核心是Generator类,其代码简洁但作用关键,下面详细解析:
3.1 Generator类代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class Generator(nn.Module):
"""将解码器输出映射到词表概率分布的模块"""
def __init__(self, embedding_dim, vocab_size):
super().__init__()
# 线性层:将解码器输出的高维特征映射到词表大小
self.project = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
"""
参数:
x: 解码器输出的特征张量,形状为[batch_size, seq_len, embedding_dim]
返回:
log_probs: 对数概率分布,形状为[batch_size, seq_len, vocab_size]
"""
# 先通过线性层映射到词表维度,再应用log_softmax归一化
return F.log_softmax(self.project(x), dim=-1)
3.2 代码细节解析
-
初始化方法(init):
embedding_dim:解码器输出的特征维度(需与Transformer整体维度一致,如512)。vocab_size:目标任务的词表大小(如机器翻译中的目标语言词表大小)。self.project:线性层(nn.Linear)是核心组件,权重矩阵形状为[embedding_dim, vocab_size],负责将高维特征压缩到词表维度。
-
前向传播(forward):
- 输入
x是解码器的输出特征,形状为[batch_size, seq_len, embedding_dim]。 - 第一步通过
self.project(x)将特征映射到词表维度,输出形状为[batch_size, seq_len, vocab_size]。 - 第二步应用
F.log_softmax(..., dim=-1):- 对最后一个维度(词表维度)进行归一化,确保每个位置的概率和为1。
- 使用
log_softmax而非softmax的原因:一是避免数值下溢(softmax在高维时易出现极小数),二是与PyTorch的NLLLoss损失函数直接兼容(NLLLoss需输入log概率)。
- 输入
3.3 张量形状变化示例
假设Transformer的embedding_dim=512,目标语言词表vocab_size=10000,输入解码器输出的特征形状为[2, 6, 512](2条样本,每条6个token):
- 经过
self.project(x)后,形状变为[2, 6, 10000](映射到词表维度)。 - 经过
log_softmax后,形状保持[2, 6, 10000],但每个[6, 10000]矩阵的最后一个维度满足概率和为1(对数空间)。
四、输出部分与损失函数的配合
在训练阶段,Generator的输出需与损失函数配合计算模型误差。以机器翻译为例,常用NLLLoss(负对数似然损失),其计算流程如下:
# 示例:Generator输出与损失计算
def test_loss():
# 模拟解码器输出:[batch_size=2, seq_len=6, embedding_dim=512]
decoder_output = torch.randn(2, 6, 512)
# 初始化生成器(词表大小10000)
generator = Generator(embedding_dim=512, vocab_size=10000)
# 生成对数概率分布
log_probs = generator(decoder_output) # 形状:[2, 6, 10000]
# 模拟目标标签(每个位置的真实token索引):[batch_size=2, seq_len=6]
target_labels = torch.randint(0, 10000, (2, 6), dtype=torch.long)
# 计算损失(NLLLoss需将log_probs展平为[batch*seq_len, vocab_size],标签展平为[batch*seq_len])
criterion = nn.NLLLoss()
loss = criterion(log_probs.reshape(-1, 10000), target_labels.reshape(-1))
print(f"损失值:{loss.item()}") # 输出一个标量损失
test_loss()
关键说明:
NLLLoss会自动取出每个位置真实标签对应的对数概率,并计算平均值的相反数,实现“最大化正确标签概率”的训练目标。- 若使用
CrossEntropyLoss,则无需log_softmax,但Transformer中通常保留log_softmax以提升数值稳定性。
五、生成阶段的预测逻辑(推理阶段)
在推理阶段(如生成译文),Generator的输出需通过解码策略转化为具体token序列。以贪婪搜索为例:
def greedy_decode(generator, decoder_output):
"""贪婪搜索:每个位置选择概率最高的token"""
log_probs = generator(decoder_output) # [batch_size, seq_len, vocab_size]
# 取最后一个维度的最大值索引(即预测的token)
predicted_tokens = torch.argmax(log_probs, dim=-1) # [batch_size, seq_len]
return predicted_tokens
# 测试贪婪搜索
decoder_output = torch.randn(2, 6, 512) # 模拟解码器输出
generator = Generator(512, 10000)
preds = greedy_decode(generator, decoder_output)
print(f"预测的token序列:{preds}")
print(f"预测形状:{preds.shape}") # 预期:[2, 6]
扩展说明:
- 实际应用中,贪婪搜索可能生成重复或不合理的序列,因此常使用束搜索(Beam Search)等更优策略,但核心都是基于
Generator输出的概率分布。
六、输出部分的设计思想
-
极简主义设计:
输出部分仅包含一个线性层和log_softmax,与复杂的编码器、解码器形成对比。这种设计的原因是:特征提取和语义建模已由前面的层完成,输出部分只需专注于“特征→词表”的映射,避免引入冗余参数。 -
与整体架构的兼容性:
embedding_dim必须与解码器输出维度一致,确保张量形状匹配。vocab_size需与目标任务的词表对应(如翻译任务中与目标语言词表大小一致)。
-
数值稳定性优先:
使用log_softmax而非softmax,解决了高维空间中概率值过小导致的下溢问题,同时兼容PyTorch的损失函数接口,简化训练流程。
七、完整代码与测试验证
7.1 完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# 假设从解码器模块导入测试函数
from Transformer_decoder import test_decoder
class Generator(nn.Module):
"""Transformer输出部分:将解码器特征映射到词表概率分布"""
def __init__(self, embedding_dim, vocab_size):
super().__init__()
self.project = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
return F.log_softmax(self.project(x), dim=-1)
# 测试输出部分与解码器的配合
def test_generator():
# 获取解码器输出(来自解码器测试函数)
decoder_result = test_decoder() # 形状:[2, 6, 512]
# 初始化生成器(假设词表大小为10000)
generator = Generator(embedding_dim=512, vocab_size=10000)
# 生成对数概率
generator_result = generator(decoder_result)
# 验证输出形状
print(f'{"*"*30}生成器输出{"*"*30}')
print(f'生成器输出形状:{generator_result.shape}') # 预期:[2, 6, 10000]
# 验证log_softmax的归一性(最后一个维度的指数和应为1)
probs = torch.exp(generator_result) # 转换为概率
sum_probs = torch.sum(probs, dim=-1) # 每个位置的概率和
print(f'概率和(应接近1.0):{sum_probs}')
return generator_result
if __name__ == '__main__':
test_generator()
7.2 测试输出说明
- 形状验证:生成器输出形状为
[2, 6, 10000],与解码器输出的[2, 6, 512]兼容,确保序列长度和批次大小不变。 - 归一性验证:
torch.sum(probs, dim=-1)的结果接近1.0,证明log_softmax正确实现了概率归一化。


















&spm=1001.2101.3001.5002&articleId=149772659&d=1&t=3&u=9270d77711ab4daeba06f88c836a8382)
 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









