




文章目录
相关文章
Transformer架构:结构介绍:网页链接
Transformer架构:输入部分代码实现(基于PyTorch):网页链接
Transformer架构:核心模块代码实现(基于PyTorch):网页链接
Transformer架构:编码器部分代码实现(基于PyTorch):网页链接
Transformer架构:输出部分代码实现(基于PyTorch):网页链接
Transformer架构:整体实现代码(基于PyTorch):网页链接
一、解码器的核心作用
在Transformer架构中,解码器(Decoder)是序列生成的核心模块,负责基于编码器输出的上下文特征和自身历史输出,生成符合任务需求的目标序列(如机器翻译中的译文、文本摘要中的摘要句)。其核心能力体现在:
- autoregressive 生成:通过掩码自注意力机制确保生成时仅依赖已生成的token,避免未来信息泄露。
- 跨模态对齐:通过编码器-解码器注意力机制,动态关联目标序列与源序列的上下文信息(如翻译时将“苹果”关联到“Apple”)。
- 特征精细化加工:通过多层堆叠的解码器层,逐步优化生成序列的语义一致性和语法正确性。
二、解码器整体工作流程图
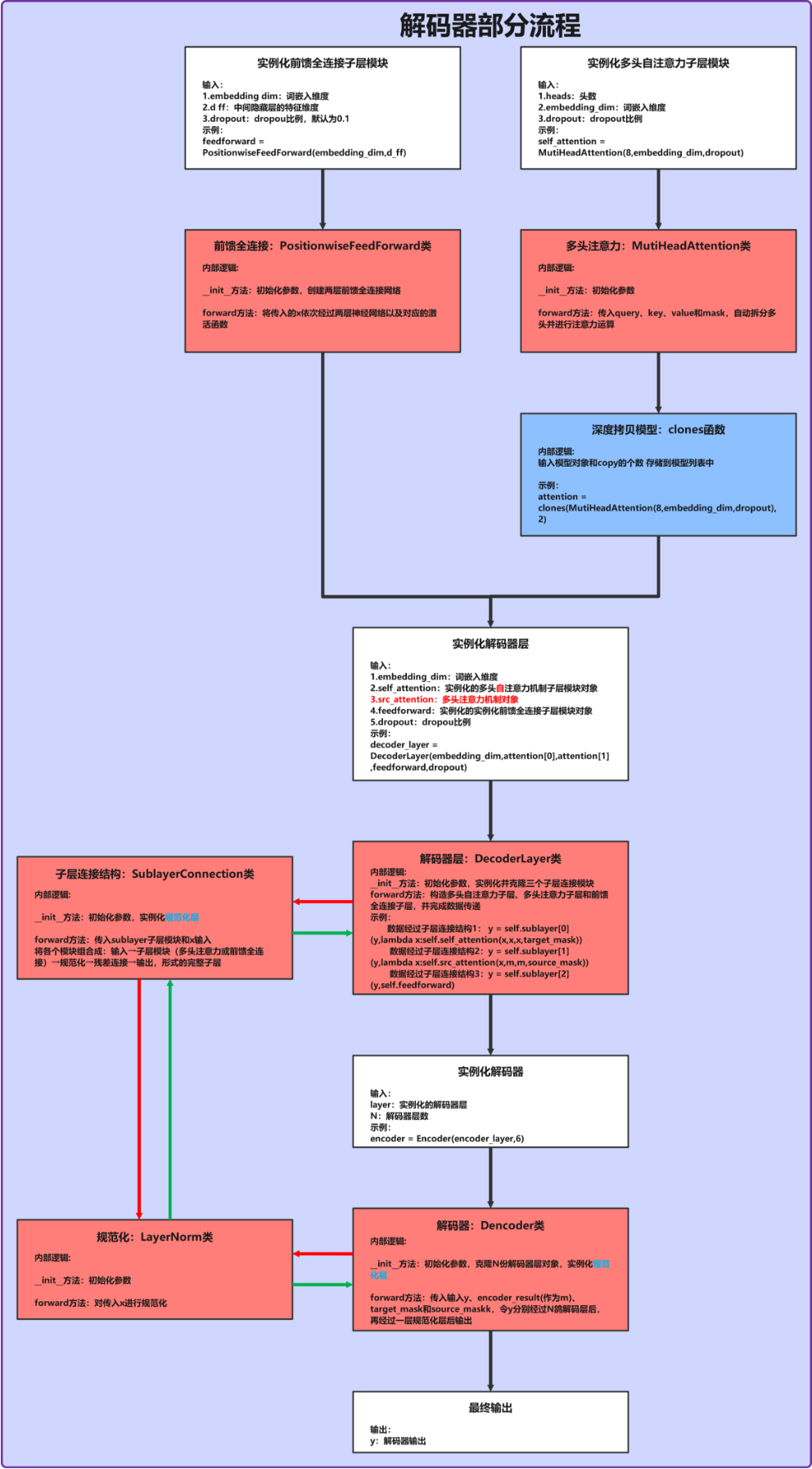
三、解码器层(DecoderLayer):单一层级的序列生成逻辑
解码器层是构成解码器的基本单元,每个层包含“自注意力子层”“编码器-解码器注意力子层”和“前馈网络子层”,通过子层连接结构实现特征的逐步优化。
3.1 代码实现与结构解析
class DecoderLayer(nn.Module):
def __init__(self, embedding_dim, self_attention, src_attention, feedforward, dropout):
super().__init__()
self.embedding_dim = embedding_dim # 词嵌入维度(如512)
self.self_attention = self_attention # 目标序列自注意力模块(带掩码)
self.src_attention = src_attention # 编码器-解码器注意力模块
self.feedforward = feedforward # 前馈全连接模块
# 克隆3个子层连接结构(分别对应三个子层)
self.sublayer = clones(SublayerConnection(embedding_dim, dropout), 3)
def forward(self, y, encoder_result, target_mask, source_mask):
m = encoder_result # 编码器输出的源序列特征
# 第一个子层:目标序列自注意力 + 残差连接 + 规范化
y = self.sublayer[0](y, lambda x: self.self_attention(x, x, x, target_mask))
# 第二个子层:编码器-解码器注意力 + 残差连接 + 规范化
y = self.sublayer[1](y, lambda x: self.src_attention(x, m, m, source_mask))
# 第三个子层:前馈网络 + 残差连接 + 规范化
y = self.sublayer[2](y, self.feedforward)
return y
3.2 关键细节解析
-
模块依赖:
self_attention:多头注意力实例(如8头),用于目标序列的自注意力计算(query=key=value=y)。src_attention:多头注意力实例,用于关联目标序列与源序列(query=y, key=value=encoder_result)。sublayer:通过clones函数复制的3个子层连接结构,封装“残差连接+LayerNorm+Dropout”逻辑,确保深层网络训练稳定。
-
前向传播流程:
- 自注意力子层:输入目标序列
y通过自注意力捕捉内部依赖,target_mask屏蔽未来token(如生成第i个词时,仅允许关注1~i个词)。 - 编码器-解码器注意力子层:使用目标序列作为查询(
query),编码器输出作为键值对(key=value),实现“目标序列→源序列”的信息对齐(如翻译时将“我”关联到源文中的“我”)。 - 前馈网络子层:对注意力输出进行线性变换和ReLU激活,增强模型的非线性拟合能力。
- 自注意力子层:输入目标序列
-
张量形状变化:
输入y的形状为[batch_size, tgt_seq_len, embedding_dim],经过三层子处理后形状保持不变,确保多层堆叠时的兼容性。
四、解码器(Decoder):多层堆叠的序列生成优化
解码器由N个相同的解码器层堆叠而成,通过多层迭代处理,逐步优化目标序列的生成质量,最终输出可直接用于预测的特征表示。
4.1 代码实现与结构解析
class Decoder(nn.Module):
def __init__(self, layer, N):
super().__init__()
# 克隆N个解码器层(如N=6,与编码器对称)
self.layers = clones(layer, N)
# 最终规范化层(输出前的特征分布调整)
self.norm = LayerNorm(embedding_dim)
def forward(self, y, encoder_result, target_mask, source_mask):
# 依次通过N个解码器层
for layer in self.layers:
y = layer(y, encoder_result, target_mask, source_mask)
# 最终规范化,确保输出特征分布稳定
return self.norm(y)
4.2 关键细节解析
-
多层堆叠逻辑:
通过clones(layer, N)复制N个解码器层(Transformer原论文中N=6),形成深度生成网络。每层的输出作为下一层的输入,实现“粗→细”的序列特征优化(如从“词级语义”到“句子级连贯性”的提升)。 -
掩码的传递与作用:
target_mask:贯穿所有解码器层,始终屏蔽目标序列中的未来token和填充token(PAD),确保生成过程的 autoregressive 特性。source_mask:用于屏蔽源序列中的填充token,避免编码器-解码器注意力关注无效信息。
-
与编码器的协同:
编码器输出encoder_result在所有解码器层中被复用,作为key和value提供源序列的上下文信息,而目标序列y则通过query动态查询相关信息,实现“源→目标”的精准对齐。
五、核心设计思想
-
双注意力机制的分工:
自注意力聚焦于目标序列内部的连贯性(如语法正确),编码器-解码器注意力聚焦于跨序列的语义对齐(如语义一致),两者结合确保生成序列“既通顺又准确”。 -
掩码机制的必要性:
在自注意力中,target_mask通过下三角矩阵屏蔽未来token(如下表),强制模型仅依赖已生成信息,这是序列生成任务的核心约束。# target_mask示例(3个token的序列) [[1, 0, 0], [1, 1, 0], [1, 1, 1]] -
模块化设计的扩展性:
解码器层的三个子层通过统一的SublayerConnection接口封装,便于替换子层实现(如将自注意力替换为稀疏注意力以提升效率)。
六、解码器测试与验证
通过test_decoder函数验证解码器的功能,观察输入输出的形状一致性和特征变换效果:
def test_decoder():
# 模拟目标序列输入(2条样本,每条6个token)
y = torch.tensor([[10, 20, 30, 40, 50, 60], [70, 80, 90, 100, 110, 120]])
y = untest_input(y) # 转换为嵌入向量(形状:[2, 6, 512])
# 获取编码器输出(模拟源序列特征)
encoder_result = test_encoder() # 形状:[2, 4, 512]
# 初始化注意力和前馈网络
attention = clones(MutiHeadAttention(8, embedding_dim, dropout), 2) # 2个多头注意力实例
feedforward = PositionwiseFeedForward(embedding_dim, d_ff) # 前馈网络
# 构建解码器
decoder_layer = DecoderLayer(embedding_dim, attention[0], attention[1], feedforward, dropout)
decoder = Decoder(decoder_layer, 6) # 6层解码器
# 初始化掩码(模拟填充和未来信息屏蔽)
target_mask = torch.zeros(heads, 6, 6) # 目标序列掩码(6个token)
source_mask = torch.zeros(heads, 6, 4) # 源序列掩码(6个目标token→4个源token)
# 解码器前向传播
decoder_result = decoder(y, encoder_result, target_mask, source_mask)
# 输出验证
print(f'{"*"*30}解码器输出{"*"*30}')
print(decoder_result)
print(f'解码器输出形状:{decoder_result.shape}') # 预期:[2, 6, 512]
return decoder_result
if __name__ == '__main__':
test_decoder()
测试输出说明:
- 解码器输出形状与输入目标序列一致(
[2, 6, 512]),确保后续可直接接入线性层预测下一个token。 - 特征值经过多层处理后发生非线性变换,体现了解码器对序列特征的优化能力。
七、完整代码
from Transformer_encoder import *
from Transformer_moduls import *
# 解码器层类 DecoderLayer 实现
class DecoderLayer(nn.Module):
def __init__(self, embedding_dim, self_attention, src_attention, feedforward, dropout):
super().__init__()
self.embedding_dim = embedding_dim
self.self_attention = self_attention # 目标序列自注意力(q=k=v)
self.src_attention = src_attention # 编码器-解码器注意力(q≠k=v)
self.feedforward = feedforward
self.sublayer = clones(SublayerConnection(embedding_dim, dropout), 3) # 3个子层连接
def forward(self, y, encoder_result, target_mask, source_mask):
m = encoder_result
# 自注意力子层(带目标掩码)
y = self.sublayer[0](y, lambda x: self.self_attention(x, x, x, target_mask))
# 编码器-解码器注意力子层(带源掩码)
y = self.sublayer[1](y, lambda x: self.src_attention(x, m, m, source_mask))
# 前馈网络子层
y = self.sublayer[2](y, self.feedforward)
return y
# 解码器类 Decoder 实现
class Decoder(nn.Module):
def __init__(self, layer, N):
super().__init__()
self.layers = clones(layer, N) # 堆叠N个解码器层
self.norm = LayerNorm(embedding_dim) # 最终规范化
def forward(self, y, encoder_result, target_mask, source_mask):
for layer in self.layers:
y = layer(y, encoder_result, target_mask, source_mask)
return self.norm(y)
# 解码器测试函数
def test_decoder():
y = torch.tensor([[10,20,30,40,50,60],[70,80,90,100,110,120]])
y = untest_input(y) # 转换为嵌入向量
encoder_result = test_encoder() # 获取编码器输出
# 初始化组件
attention = clones(MutiHeadAttention(8, embedding_dim, dropout), 2)
feedforward = PositionwiseFeedForward(embedding_dim, d_ff)
decoder_layer = DecoderLayer(embedding_dim, attention[0], attention[1], feedforward, dropout)
decoder = Decoder(decoder_layer, 6) # 6层解码器
# 掩码设置
target_mask = torch.zeros(heads, 6, 6)
source_mask = torch.zeros(heads, 6, 4)
# 前向传播
decoder_result = decoder(y, encoder_result, target_mask, source_mask)
print(f'{"*"*30}解码器输出{"*"*30}')
print(decoder_result)
print(f'解码器输出形状:{decoder_result.shape}')
return decoder_result
if __name__ == '__main__':
test_decoder()


















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









