



二元 Logistic 回归是分析二分类因变量(0/1)与多个自变量关系的标准方法。它通过对事件发生概率的对数变换建模,既能解释方向与显著性,又能给出优势比(Odds Ratio,OR)与边际效应。本文系统介绍二元 Logistic 的理论框架、常用判据、模型诊断、变量进入策略(全进入 / 向前 / 向后 / 逐步)。
一、Logistic 回归的建模思想
二元 Logistic 回归以事件发生的概率p为建模对象,采用对数几率(logit)形式建模: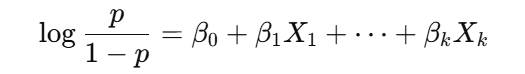
系数β的含义:保持其他变量不变时,Xj增加一个单位会使对数几率变化 βj。常用解释方式是转化为优势比 exp(βj),表示自变量变化对事件发生概率的乘法效应。
二、SPSSAU二元Logit回归分析流程总览
一个严谨的二元Logit回归分析,绝非简单地跑出一个公式了事。它是一套环环相扣、层层验证的科学流程。SPSSAU的设计正是将这一流程自动化、标准化,引导用户走向正确的分析路径。其核心流程可概括为下图:
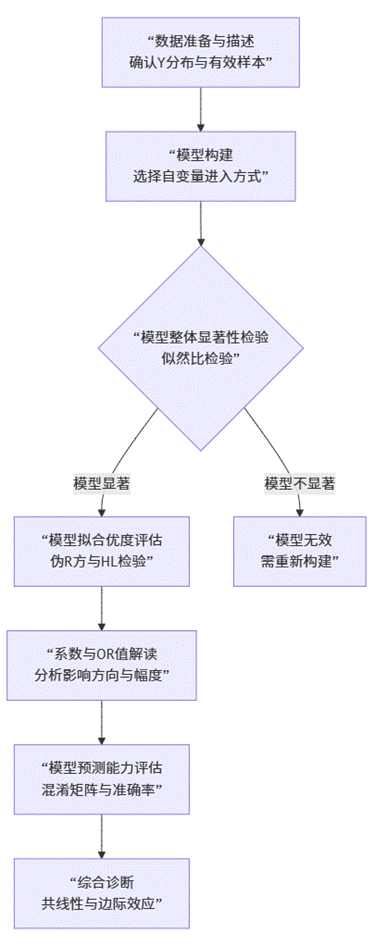
该流程清晰地展示了SPSSAU在分析过程中的三大核心价值:
导向性:每一步都有明确目标,避免用户在复杂指标中迷失方向。
完整性:从数据基础到模型诊断,覆盖了学术研究所需的全部环节。
严谨性:自动进行多重检验,确保模型结果的有效与可靠。
三、 基石与蓝图:数据描述与模型构建策略
1. 数据基础诊断
任何模型构建的前提都是数据质量。SPSSAU在分析伊始便会提供因变量的分布情况(如0和1的频数与百分比)和有效样本量。理想情况下,因变量两类别的分布不应过于失衡(如99%:1%),且有效样本量应足够大,以保证模型的稳定性和普适性。
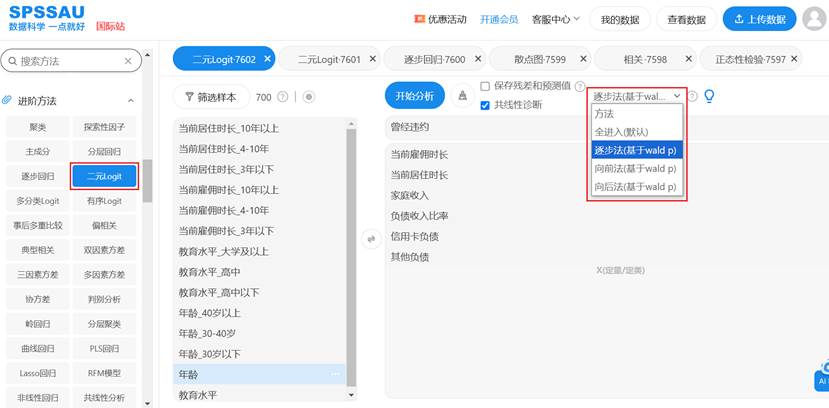
2. 模型构建策略:自变量进入方法的选择
这是模型构建的关键决策点。SPSSAU提供了多种自变量进入方法,如何选择体现了研究者的分析哲学:
(1)输入(全部进入)法:将所有预设自变量强制纳入模型。适用于理论驱动性强,研究者事先已明确所有需要考察的变量,且变量数量不多的研究。
(2)逐步法:一种自动化的变量筛选方法。SPSSAU会基于统计准则(如似然比),逐一将最显著的变量引入模型,并检查已引入变量是否因新变量的引入而变得不显著,若是则将其移除。这是一种数据驱动与理论驱动的折中方案,能有效防止过拟合,构建出简洁而有力的模型,在实践中应用极为广泛。
(3)向前法:与逐步法类似,但“只进不出”。一旦变量进入模型,就不会被移除。
(4)向后法:先将所有变量纳入模型,然后逐一移除最不显著的变量,直到模型中的所有变量都满足保留标准。
SPSSAU的智能之处在于:无论您选择哪种方法(尤其是逐步法),系统都会在“迭代中间过程”表中完整展示变量进入或移出的每一步,使得“黑箱”操作变得透明可视,让您对模型的诞生过程了如指掌。
四、 指标体系:模型质量的“体检报告”
SPSSAU的输出结果是一套完整的、相互印证的指标体系。我们将其分为以下几大类,以便于理解每个指标的理论内涵。
|
指标类别 |
核心指标 |
回答的理论问题 |
在SPSSAU中的价值 |
|
1. 模型整体显著性 |
似然比检验(卡方值、p值) |
本次构建的包含自变量的模型,是否比一个只有截距的“空模型”表现得更好? |
验证模型存在的必要性,是分析的第一道门槛。 |
|
2. 模型拟合优度 |
伪R方(McFadden等)、H-L检验 |
我的模型对数据的拟合程度如何?模型预测的概率与实际观测到的概率是否匹配? |
评估模型解释力与校准度,从不同角度衡量模型拟合效果。 |
|
3. 系数与个体显著性 |
回归系数(B)、z值、p值、OR值 |
具体是哪个自变量对因变量有显著影响?影响的方向和强度有多大? |
定位关键驱动因素,并量化其影响幅度。 |
|
4. 模型预测精度 |
预测准确率、混淆矩阵 |
这个模型在样本上的整体预测能力如何?它对哪一类别的预测更在行? |
评估模型的实用分类性能,连接统计意义与现实意义。 |
|
5. 模型辅助诊断 |
AIC/BIC、共线性诊断(VIF) |
哪个模型更简洁高效?自变量之间是否存在多重共线性干扰? |
保障模型简洁性与稳定性,为模型优化提供依据。 |
|
6. 经济意义解读 |
边际效应(dy/dx) |
自变量每增加一个单位,导致“事件发生概率”的实际变化是多少? |
将系数转化为更直观的概率变化,便于业务解读。 |
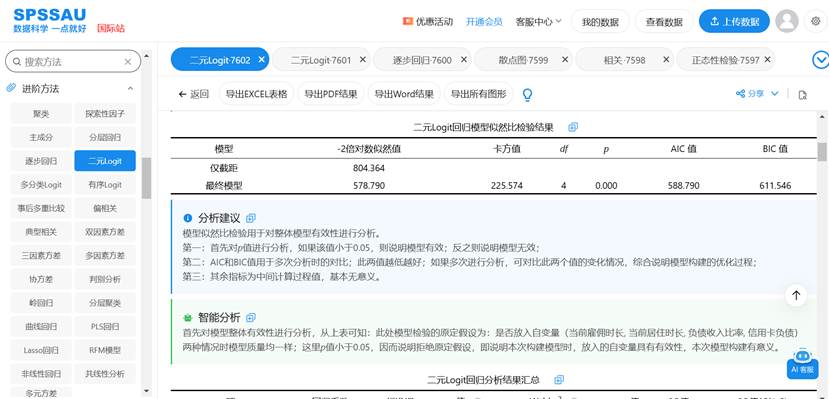
SPSSAU二元logistic回归分析结果示例如下:
五、 逻辑之网:指标间的关联与协同诊断
上述指标并非孤立存在,它们构成了一个严密的逻辑验证网络。理解这个网络,是读懂模型的关键。其内在关联如下图所示:
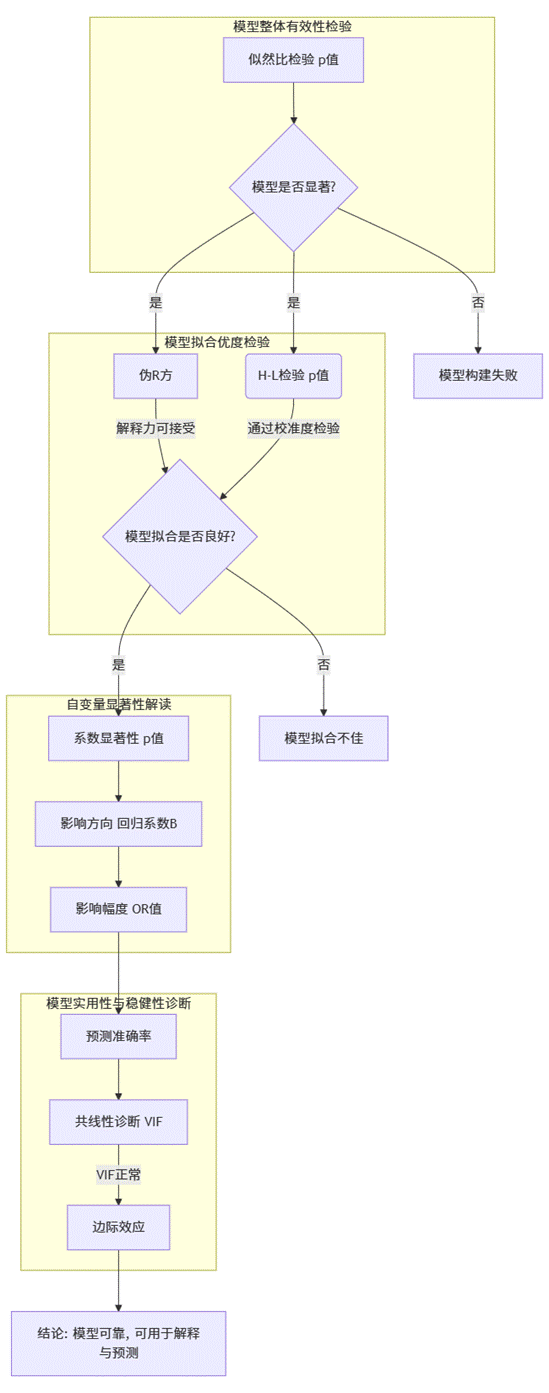
(1)模型是否值得存在?(整体显著性)
分析始于似然比检验。如果其p值不显著,说明当前模型与“空模型”无本质差异,分析应就此止步,需要重新考虑自变量选择。只有通过此检验,才证明模型整体有意义,可以进入下一步。
(2)模型拟合得怎么样?(拟合优度)
- 伪R方(McFadden, Cox & Snell等)类似于线性回归中的R方,提供了模型解释力的一个相对参考。但需要注意的是,其值通常远低于线性回归的R方。
- Hosmer-Lemeshow (H-L) 检验则更为重要。它的原假设是“模型拟合良好”。因此,我们希望看到它的p值大于显著性水平。一个不显著的H-L检验(p > 0.05)是模型通过校准度检验的标志。
(3)谁是关键因素?(变量显著性)
在确认模型整体有效且拟合良好后,我们聚焦于各个自变量的系数显著性(p值)。对于显著的变量,回归系数(B) 的符号(正负)决定了影响的方向。而更具解释力的是优势比(OR值)。OR值 > 1,表示该变量是“风险因素”,会增加事件发生几率;OR值 < 1,则表示是“保护因素”,会降低事件发生几率。OR值的大小直接反映了影响强度。
- 模型表现是否稳健?(综合诊断)
- 预测准确率与混淆矩阵从应用层面验证模型。它们告诉我们模型在样本内的分类效果如何,尤其需要关注少数类(通常是我们感兴趣的事件,如“违约”)的预测准确率。
- 共线性诊断(VIF) 确保了自变量之间没有高度相关性,从而保证系数估计的稳定性和可解释性。
- 边际效应将Logit模型的非线性关系线性化,计算出在平均水平上,自变量每变动一单位,所带来的“事件发生概率”的实际变化,这使得结论非常直观,易于向非专业人士传达。
六、SPSSAU:专业数据分析的智能化实现
二元Logit回归分析的严谨性要求研究者具备系统的统计知识框架。SPSSAU通过技术创新,将复杂的建模过程转化为具有系统性、可解释性与规范性的分析方案。SPSSAU构建的结构化分析流程确保从数据准备、模型检验到结果诊断的完整闭环,引导用户完成符合学术规范的分析路径。

















 6184
6184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









