



Meta 分析(Meta-analysis)是现代科学研究中最重要、最常用的证据整合方法之一。随着循证研究的普及,越来越多的学生、科研人员和行业分析从业者开始意识到:单个研究往往因为样本量、方法差异或实验条件限制,难以提供足够稳健的结论;而 Meta 分析能够在系统检索的基础上,通过量化整合多个独立研究的结果,得到更加可靠、更加普适的效应估计。因此,掌握 Meta 分析已经成为科研技能体系中的“硬通货”。
一、Meta 分析是什么?为什么要做?
Meta 分析是一种以定量整合为核心的统计方法,它通过系统检索、筛选符合标准的多项研究,并将其效应量(effect size)进行汇总,用以计算总体效应。相比传统综述,Meta 分析有三个显著优势:
第一,能够提升统计功效(power)。单个研究可能因样本量小导致统计检验效力不足,而多个研究的汇总能够扩大有效样本量,使结果更加稳定。
第二,可以揭示不同研究之间的异质性。例如,不同地区、不同实验方法或不同样本特征可能导致研究结果差异,Meta 分析提供定量检验与探索异质性的途径,使研究者能够理解结果差异背后的潜在机制。
第三,能够降低单个研究偏差的影响。虽然每项研究都有自身局限,但综合证据可帮助研究者建立更接近真实的效应水平。
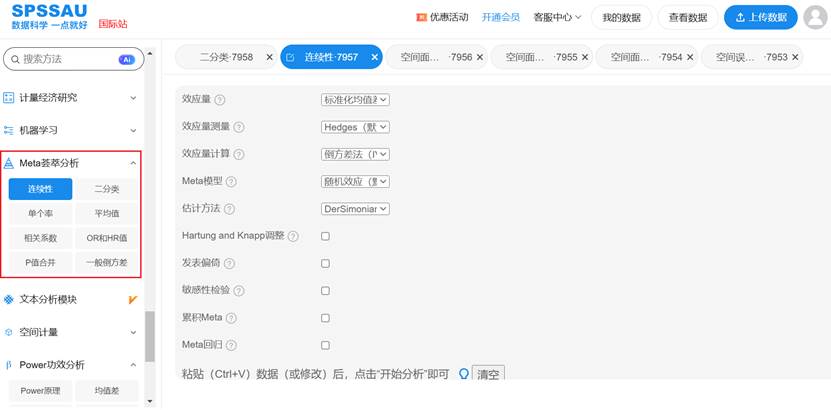
SPSSAU 提供的 Meta 荟萃分析模块采用的是标准文献计量流程,能够自动计算效应量、进行异质性检验、绘制森林图(Forest plot)与漏斗图(Funnel plot),对初学者而言非常友好。
二、Meta 分析完整流程概览
下面用一张 Mermaid 图呈现标准的 Meta 分析流程,适用于科研论文、综述或结题报告的写作逻辑。
Mermaid 图:Meta 分析流程
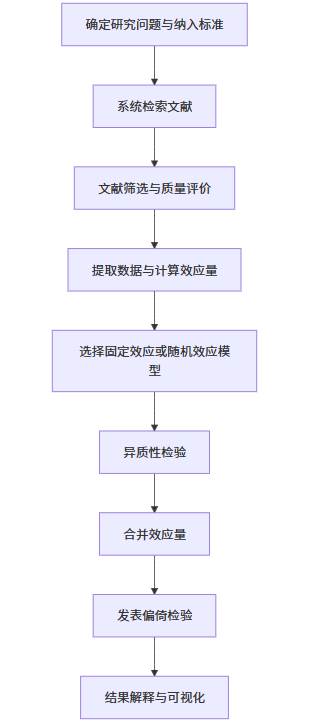
这张流程图展示了一个规范 Meta 分析的完整路径。从提出研究问题开始,到文献检索、数据提取,再到模型选择、效应量合并、偏倚检验及结果可视化,是一个由质到量、由证据收集到证据整合的系统过程。
三、研究问题定义与纳入标准设计
Meta 分析的第一步,是界定研究主题和目标。研究问题应当明确、具体,例如:“某项教学干预是否提高学生数学成绩?”或“某类治疗能否降低患者某项指标?”在此基础上,研究者需要进一步制定纳入与排除标准。
- 在纳入标准方面,通常包括研究类型(如随机对照试验、观察性研究)、研究对象特征、干预方式、结果指标、研究语言和出版年份等。
- 排除标准则可能涉及样本量过小、数据缺失严重或研究设计缺陷等。明确的标准确保筛选过程可复现,也为后续的质量评价奠定基础。
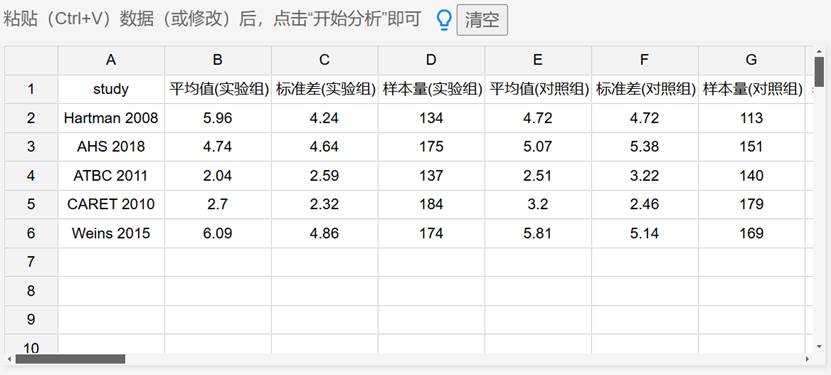
在 SPSSAU 的 Meta 分析工具中,研究者需要准备统一的数据提取表,例如研究 ID、均值、标准差、样本量、相关系数等。系统化的数据输入有助于后续自动计算效应量。
四、系统文献检索:构建完整的证据体系
系统检索是 Meta 分析最关键的部分之一,其目标是从数据库中尽可能完整地获取相关研究,避免遗漏导致的选择性偏倚。常用数据库包括 Web of Science、PubMed、CNKI 等。
检索式应根据研究主题设计,并结合主题词(MeSH)与自由词进行组合。例如:
- (“intervention” OR “treatment”) AND (“math performance”)
- (“teaching method”) AND (“meta analysis”)
为了保证可重复性,检索策略应在正式报告中完整记录,包括检索日期、数据库、关键词和过滤条件。
五、文献筛选与质量评价:从数量到质量的过滤
文献筛选一般分为两步:标题摘要筛选和全文筛选。研究者需要依据纳入标准逐条判断文献是否符合条件。筛选过程通常需要两位研究者独立进行,并计算一致性指标以保证客观性。
质量评价作为 Meta 分析的重要组成部分,会根据研究设计类型选择适用的工具。例如随机对照试验常用 Cochrane 风险偏倚工具,观察性研究常用 Newcastle-Ottawa Scale(NOS)。质量评价的结果既可以作为敏感性分析的依据,也可以用于异质性来源分析。
六、提取数据与计算效应量:Meta 分析的核心数据基础
Meta 分析的定量部分依赖对多个研究的关键数据进行提取。常见数据包括:
- 均值与标准差(用于计算标准化均差 SMD)
- 比例或率(用于计算风险比 RR、赔率比 OR)
- 相关系数(用于 Fisher Z 转换)
效应量的计算是 Meta 分析的数学基础,不同指标对应不同的计算方法。对于无统计背景的初学者,手动计算效应量可能是学习过程中最大的障碍之一,而 SPSSAU 的 Meta 模块自动提供了效应量计算功能,只需输入原始数据即可快速得到统一的 effect size。
七、模型选择:固定效应与随机效应的核心差异
Meta 分析的模型主要包括固定效应模型和随机效应模型,二者在理论假设和结果解释上都有重要差异。
- 固定效应模型假设所有研究共享同一真实效应,适用于研究条件高度一致的情形。该模型关注的是“精确估计一个共同效应”。
- 随机效应模型假设研究之间存在差异,其效应值来自一个分布。该模型允许存在研究间差异,更强调“平均效应”的整体估计。实际应用中,由于研究背景差异较大,随机效应模型通常更常用。

SPSSAU 提供固定效应与随机效应模型的自动选择,也允许用户手动切换,并提供相应结果的森林图与权重展示。
八、异质性检验:理解研究差异的必要流程
异质性是 Meta 分析的关键概念,代表不同研究结果之间的差异程度。常用指标包括:
第一,Q 检验。用于检验研究结果是否存在显著差异,但受样本量影响较大。
第二,I² 指标。用于衡量异质性程度。I² 越高,说明研究间差异越大。一般可按照 25%、50%、75% 分别代表低、中、高异质性。
第三,τ²(Tau-squared)。是随机效应模型的关键参数,代表真实效应分布的方差。
当异质性显著时,需要进一步考虑亚组分析、元回归或剔除个别异常研究进行敏感性分析。

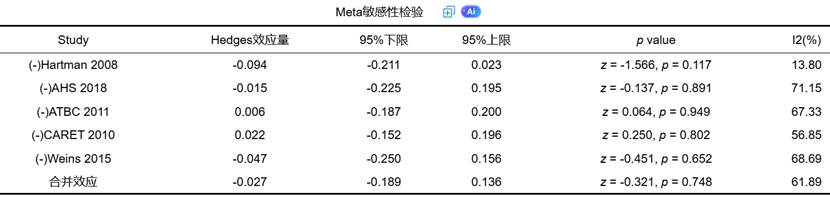
九、合并效应量:森林图背后的统计含义
合并效应量是 Meta 分析的最终核心结果,其可视化通常以森林图(Forest Plot)形式呈现。每条研究对应的点和区间表示其效应估计值及置信区间,而底部钻石形状代表综合效应量。
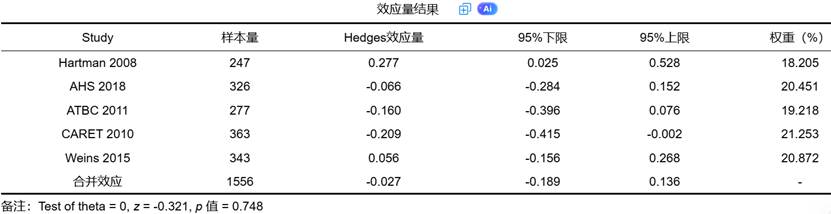
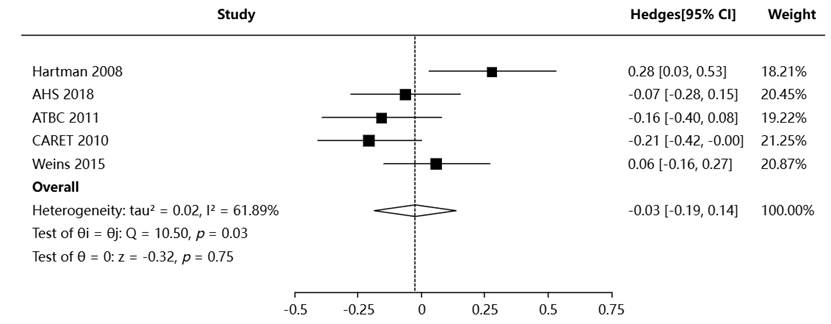
森林图除了呈现效应外,也展示了各研究的权重分配。在固定效应模型中,权重主要由研究的标准误决定;在随机效应模型中,还需要考虑研究间差异。
SPSSAU 自动生成的森林图包含研究名称、效应量、置信区间、权重百分比等核心信息,非常适合用于发表文章或展示在学术汇报中。
十、发表偏倚检验:Funnel Plot 的意义
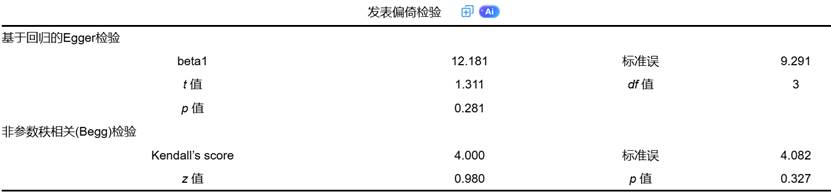
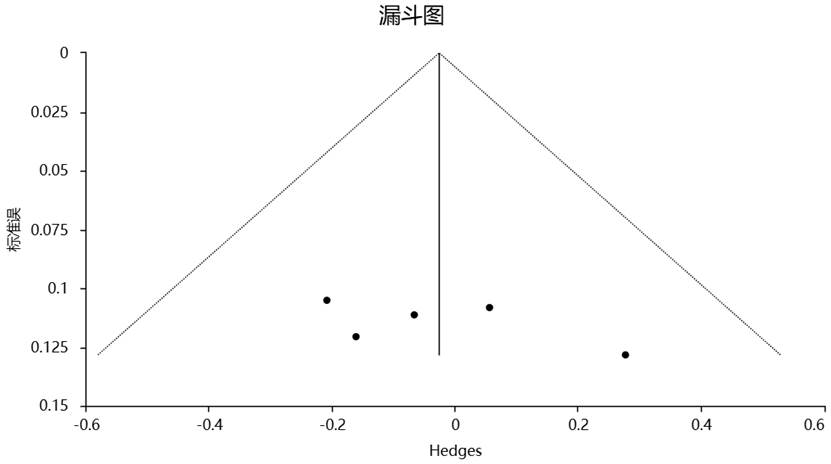
在 Meta 分析中,发表偏倚(publication bias)指的是正向结果更容易发表,负向或不显著结果被压制,从而导致分析结果偏差。漏斗图(Funnel Plot)是最常用的偏倚检查方式:如果研究点分布不对称,可能暗示存在发表偏倚。
同时,Egger 回归检验也是一种常用的定量检验方法,用于判断漏斗图的不对称是否显著。SPSSAU 的 Meta 模块能够自动生成漏斗图,并提供 Egger 检验结果,便于研究者进行偏倚诊断,SPSSAU输出结果示例如下:
十一、Meta 分析的结果解释与报告写作
一个规范的 Meta 分析报告通常需要包括以下内容:
- 检索策略与筛选流程
- 纳入研究基本特征表
- 质量评价结果
- 效应量计算方法
- 模型选择依据
- 异质性检验结果
- 合并效应值与95%CI
- 亚组分析与敏感性分析
- 发表偏倚检验
- 研究限制与未来方向
SPSSAU 提供结构化导出功能,能够将 Meta 分析的结果自动组织为表格、图形和结论段落,大幅减少写作成本。
十二、Meta 分析方法总结(附方法金字塔)
为了更系统地展示 Meta 分析的结构,我们再用一张 Mermaid 图展示从数据准备到结果解释的简化步骤。
Mermaid 图:Meta 分析核心方法结构

该图展示了 Meta 分析中从数据层到模型层再到解释层的基本结构。它强调了“效应量”“模型选择”和“异质性”之间的逻辑关系,是所有 Meta 模型的共同核心。该结构也对应了 SPSSAU Meta 分析界面的模块化布局,能够帮助研究者在软件中快速理解每一步的意义。
结语:Meta 分析是科研技能中真正“越早掌握越受益”的方法
Meta 分析不仅是一种统计技术,更是一种系统、严谨、可复现的证据整合思想。对于科研初学者而言,掌握 Meta 分析能够更深刻地理解研究设计,提升文献阅读能力,并具备开展高质量综述研究的能力。
得益于如今软件工具的普及,即便没有编程基础,也可以通过 SPSSAU 一键进行效应量计算、森林图绘制和发表偏倚检验,使 Meta 分析变得更加可操作、可实践。无论你是准备写综述论文、毕业论文,还是科研课题报告,Meta 分析都将会是一项极具价值的技能。

















 6839
6839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









